 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-based Drone Assisted Human Rescue in Disaster Environments: Challenges and Opportunities
Jun 22, 2024In this survey we are focusing on utilizing drone-based systems for the detection of individuals, particularly by identifying human screams and other distress signals. This study has significant relevance in post-disaster scenarios, including events such as earthquakes, hurricanes, military conflicts, wildfires, and more. These drones are capable of hovering over disaster-stricken areas that may be challenging for rescue teams to access directly. Unmanned aerial vehicles (UAVs), commonly referred to as drones, are frequently deployed for search-and-rescue missions during disaster situations. Typically, drones capture aerial images to assess structural damage and identify the extent of the disaster. They also employ thermal imaging technology to detect body heat signatures, which can help locate individuals. In some cases, larger drones are used to deliver essential supplies to people stranded in isolated disaster-stricken areas. In our discussions, we delve into the unique challenges associated with locating humans through aerial acoustics. The auditory system must distinguish between human cries and sounds that occur naturally, such as animal calls and wind. Additionally, it should be capable of recognizing distinct patterns related to signals like shouting, clapping, or other ways in which people attempt to signal rescue teams. To tackle this challenge, one solution involves harnessing artificial intelligence (AI) to analyze sound frequencies and identify common audio signatures. Deep learning-based networks, such as convolutional neural networks (CNNs), can be trained using these signatures to filter out noise generated by drone motors and other environmental factors. Furthermore, employing signal processing techniques like the direction of arrival (DOA) based on microphone array signals can enhance the precision of tracking the source of human noises.
Delay-Doppler Domain Pulse Design for OTFS-NOMA
May 29, 2024



We address the challenge of developing an orthogonal time-frequency space (OTFS)-based non-orthogonal multiple access (NOMA) system where each user is modulated using orthogonal pulses in the delay Doppler domain. Building upon the concept of the sufficient (bi)orthogonality train-pulse [1], we extend this idea by introducing Hermite functions, known for their orthogonality properties. Simulation results demonstrate that our proposed Hermite functions outperform the traditional OTFS-NOMA schemes, including power-domain (PDM) NOMA and code-domain (CDM) NOMA, in terms of bit error rate (BER) over a high-mobility channel. The algorithm's complexity is minimal, primarily involving the demodulation of OTFS. The spectrum efficiency of Hermite-based OTFS-NOMA is K times that of OTFS-CDM-NOMA scheme, where K is the spreading length of the NOMA waveform.
Deep Dict: Deep Learning-based Lossy Time Series Compressor for IoT Data
Jan 18, 2024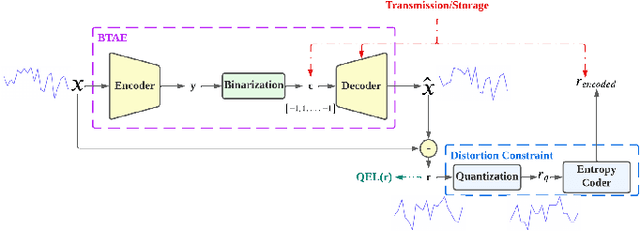
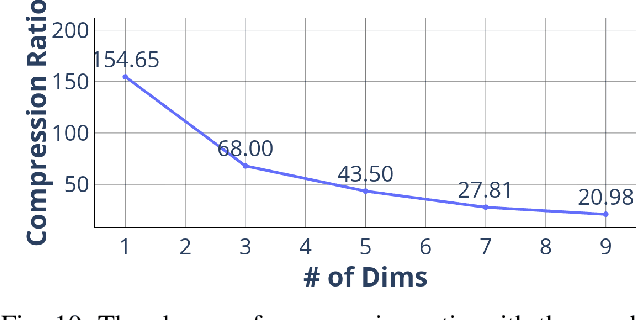
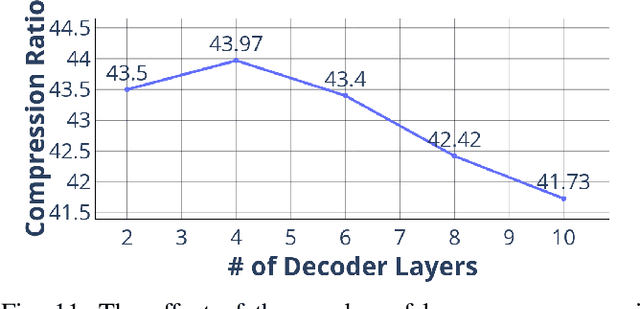
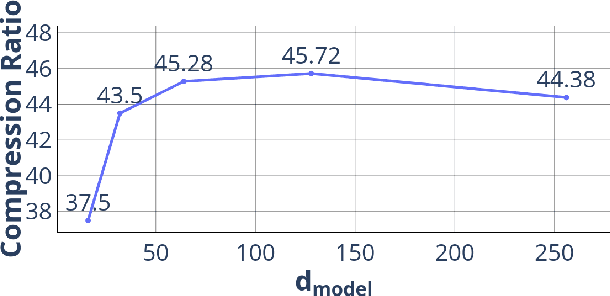
We propose Deep Dict, a deep learning-based lossy time series compressor designed to achieve a high compression ratio while maintaining decompression error within a predefined range. Deep Dict incorporates two essential components: the Bernoulli transformer autoencoder (BTAE) and a distortion constraint. BTAE extracts Bernoulli representations from time series data, reducing the size of the representations compared to conventional autoencoders. The distortion constraint limits the prediction error of BTAE to the desired range. Moreover, in order to address the limitations of common regression losses such as L1/L2, we introduce a novel loss function called quantized entropy loss (QEL). QEL takes into account the specific characteristics of the problem, enhancing robustness to outliers and alleviating optimization challenges. Our evaluation of Deep Dict across ten diverse time series datasets from various domains reveals that Deep Dict outperforms state-of-the-art lossy compressors in terms of compression ratio by a significant margin by up to 53.66%.
On the Impact of CDL and TDL Augmentation for RF Fingerprinting under Impaired Channels
Dec 11, 2023



Cyber-physical systems have recently been used in several areas (such as connected and autonomous vehicles) due to their high maneuverability. On the other hand, they are susceptible to cyber-attacks. Radio frequency (RF) fingerprinting emerges as a promising approach. This work aims to analyze the impact of decoupling tapped delay line and clustered delay line (TDL+CDL) augmentation-driven deep learning (DL) on transmitter-specific fingerprints to discriminate malicious users from legitimate ones. This work also considers 5G-only-CDL, WiFi-only-TDL augmentation approaches. RF fingerprinting models are sensitive to changing channels and environmental conditions. For this reason, they should be considered during the deployment of a DL model. Data acquisition can be another option. Nonetheless, gathering samples under various conditions for a train set formation may be quite hard. Consequently, data acquisition may not be feasible. This work uses a dataset that includes 5G, 4G, and WiFi samples, and it empowers a CDL+TDL-based augmentation technique in order to boost the learning performance of the DL model. Numerical results show that CDL+TDL, 5G-only-CDL, and WiFi-only-TDL augmentation approaches achieve 87.59%, 81.63%, 79.21% accuracy on unobserved data while TDL/CDL augmentation technique and no augmentation approach result in 77.81% and 74.84% accuracy on unobserved data, respectively.
Low-Density Spreading Design Based on an Algebraic Scheme for NOMA Systems
Jan 01, 2022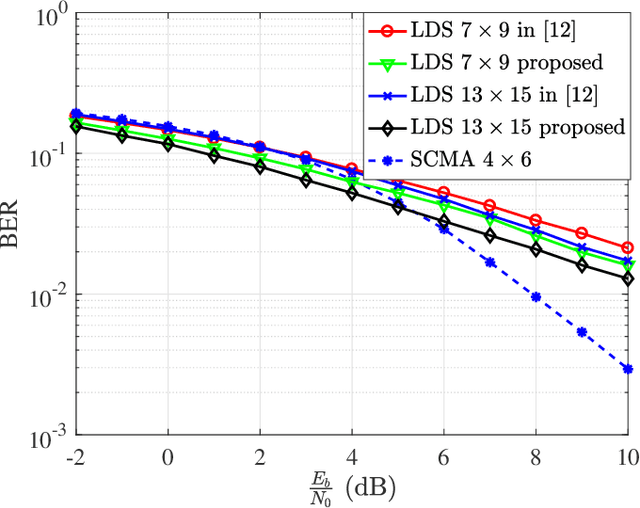
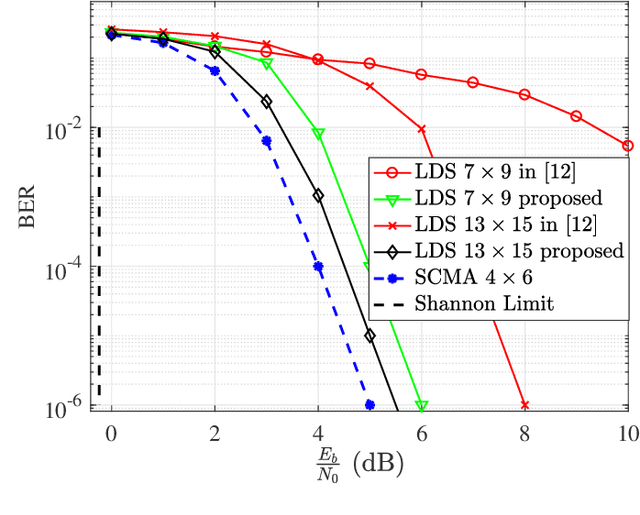
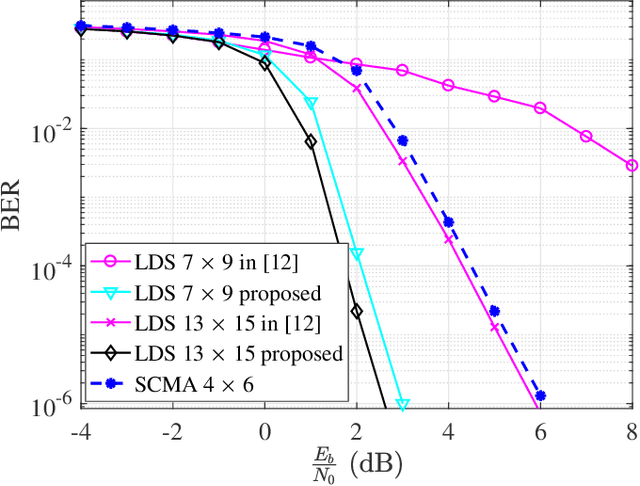
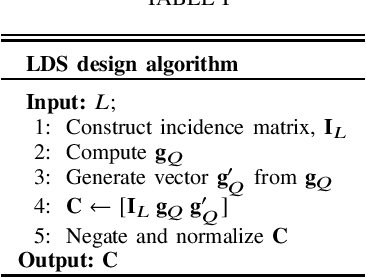
NOMA) technique based on an algebraic design is studied. We propose an improved low-density spreading (LDS) sequence design based on projective geometry. In terms of its bit error rate (BER) performance, our proposed improved LDS code set outperforms the existing LDS designs over the frequency nonselective Rayleigh fading and additive white Gaussian noise (AWGN) channels. We demonstrated that achieving the best BER depends on the minimum distance.
NOMA Computation Over Multi-Access Channels for Multimodal Sensing
Jan 01, 2022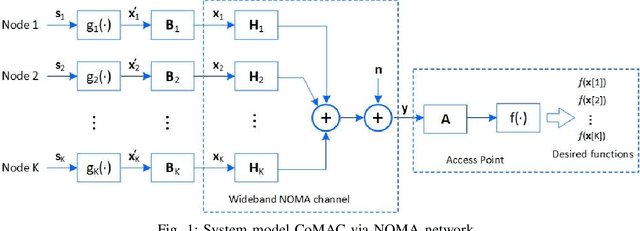
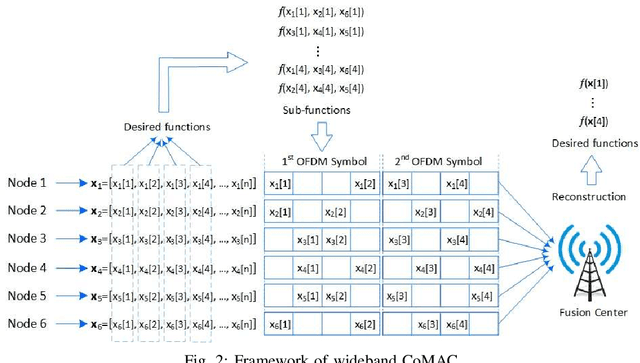
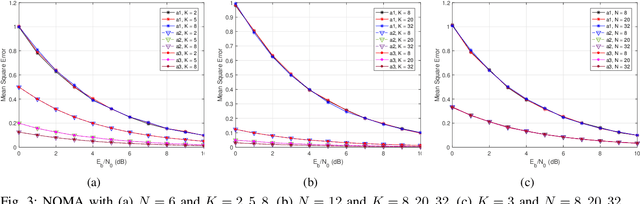
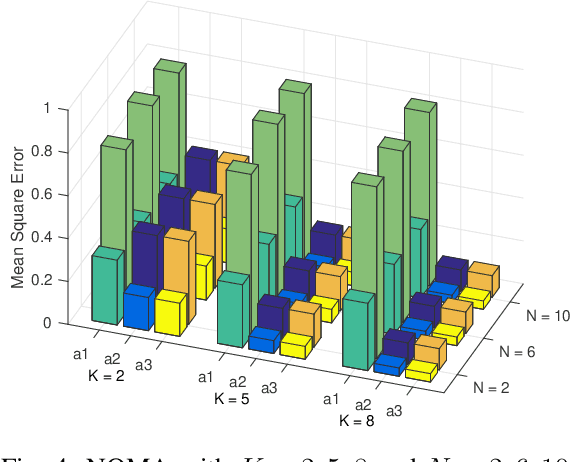
An improved mean squared error (MSE) minimization solution based on eigenvector decomposition approach is conceived for wideband non-orthogonal multiple-access based computation over multi-access channel (NOMA-CoMAC) framework. This work aims at further developing NOMA-CoMAC for next-generation multimodal sensor networks, where a multimodal sensor monitors several environmental parameters such as temperature, pollution, humidity, or pressure. We demonstrate that our proposed scheme achieves an MSE value approximately 0.7 lower at E_b/N_o = 1 dB in comparison to that for the average sum-channel based method. Moreover, the MSE performance gain of our proposed solution increases even more for larger values of subcarriers and sensor nodes due to the benefit of the diversity gain. This, in return, suggests that our proposed scheme is eminently suitable for multimodal sensor networks.