 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Information Sharing in ICT Supply Chain Social Network via Table Structure Recognition
Nov 03, 2022

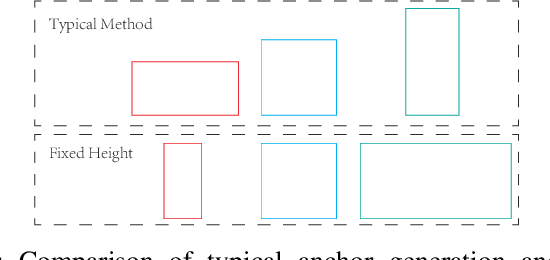

The global Information and Communications Technology (ICT) supply chain is a complex network consisting of all types of participants. It is often formulated as a Social Network to discuss the supply chain network's relations, properties, and development in supply chain management. Information sharing plays a crucial role in improving the efficiency of the supply chain, and datasheets are the most common data format to describe e-component commodities in the ICT supply chain because of human readability. However, with the surging number of electronic documents, it has been far beyond the capacity of human readers, and it is also challenging to process tabular data automatically because of the complex table structures and heterogeneous layouts. Table Structure Recognition (TSR) aims to represent tables with complex structures in a machine-interpretable format so that the tabular data can be processed automatically. In this paper, we formulate TSR as an object detection problem and propose to generate an intuitive representation of a complex table structure to enable structuring of the tabular data related to the commodities. To cope with border-less and small layouts, we propose a cost-sensitive loss function by considering the detection difficulty of each class. Besides, we propose a novel anchor generation method using the character of tables that columns in a table should share an identical height, and rows in a table should share the same width. We implement our proposed method based on Faster-RCNN and achieve 94.79% on mean Average Precision (AP), and consistently improve more than 1.5% AP for different benchmark models.
On Cropped versus Uncropped Training Sets in Tabular Structure Detection
Oct 07, 2021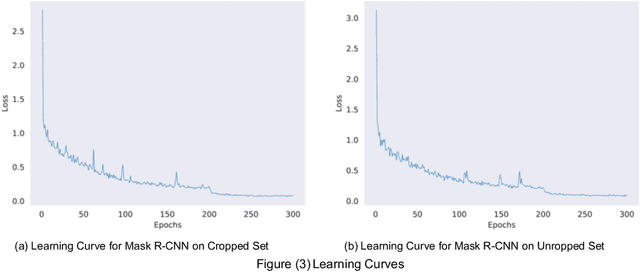
Automated document processing for tabular information extraction is highly desired in many organizations, from industry to government. Prior works have addressed this problem under table detection and table structure detection tasks. Proposed solutions leveraging deep learning approaches have been giving promising results in these tasks. However, the impact of dataset structures on table structure detection has not been investigated. In this study, we provide a comparison of table structure detection performance with cropped and uncropped datasets. The cropped set consists of only table images that are cropped from documents assuming tables are detected perfectly. The uncropped set consists of regular document images. Experiments show that deep learning models can improve the detection performance by up to 9% in average precision and average recall on the cropped versions. Furthermore, the impact of cropped images is negligible under the Intersection over Union (IoU) values of 50%-70% when compared to the uncropped versions. However, beyond 70% IoU thresholds, cropped datasets provide significantly higher detection performance.