 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Detection Based Table Structure Recognition for Visually Rich Documents
Dec 01, 2023



Table Structure Recognition (TSR) aims at transforming unstructured table images into structured formats, such as HTML sequences. One type of popular solution is using detection models to detect components of a table, such as columns and rows, then applying a rule-based post-processing method to convert detection results into HTML sequences. However, existing detection-based studies often have the following limitations. First, these studies usually pay more attention to improving the detection performance, which does not necessarily lead to better performance regarding cell-level metrics, such as TEDS. Second, some solutions over-simplify the problem and can miss some critical information. Lastly, even though some studies defined the problem to detect more components to provide as much information as other types of solutions, these studies ignore the fact this problem definition is a multi-label detection because row, projected row header and column header can share identical bounding boxes. Besides, there is often a performance gap between two-stage and transformer-based detection models regarding the structure-only TEDS, even though they have similar performance regarding the COCO metrics. Therefore, we revisit the limitations of existing detection-based solutions, compare two-stage and transformer-based detection models, and identify the key design aspects for the success of a two-stage detection model for the TSR task, including the multi-class problem definition, the aspect ratio for anchor box generation, and the feature generation of the backbone network. We applied simple methods to improve these aspects of the Cascade R-CNN model, achieved state-of-the-art performance, and improved the baseline Cascade R-CNN model by 19.32%, 11.56% and 14.77% regarding the structure-only TEDS on SciTSR, FinTabNet, and PubTables1M datasets.
Table Detection for Visually Rich Document Images
May 30, 2023



Table Detection (TD) is a fundamental task towards visually rich document understanding. Current studies usually formulate the TD problem as an object detection problem, then leverage Intersection over Union (IoU) based metrics to evaluate the model performance and IoU-based loss functions to optimize the model. TD applications usually require the prediction results to cover all the table contents and avoid information loss. However, IoU and IoU-based loss functions cannot directly reflect the degree of information loss for the prediction results. Therefore, we propose to decouple IoU into a ground truth coverage term and a prediction coverage term, in which the former can be used to measure the information loss of the prediction results. Besides, tables in the documents are usually large, sparsely distributed, and have no overlaps because they are designed to summarize essential information to make it easy to read and interpret for human readers. Therefore, in this study, we use SparseR-CNN as the base model, and further improve the model by using Gaussian Noise Augmented Image Size region proposals and many-to-one label assignments. To demonstrate the effectiveness of proposed method and compare with state-of-the-art methods fairly, we conduct experiments and use IoU-based evaluation metrics to evaluate the model performance. The experimental results show that the proposed method can consistently outperform state-of-the-art methods under different IoU-based metric on a variety of datasets. We conduct further experiments to show the superiority of the proposed decoupled IoU for the TD applications by replacing the IoU-based loss functions and evaluation metrics with proposed decoupled IoU counterparts. The experimental results show that our proposed decoupled IoU loss can encourage the model to alleviate information loss.
Revisiting Table Detection Datasets for Visually Rich Documents
May 04, 2023
Table Detection has become a fundamental task for visually rich document understanding with the surging number of electronic documents. There have been some open datasets widely used in many studies. However, popular available datasets have some inherent limitations, including the noisy and inconsistent samples, and the limit number of training samples, and the limit number of data-sources. These limitations make these datasets unreliable to evaluate the model performance and cannot reflect the actual capacity of models. Therefore, in this paper, we revisit some open datasets with high quality of annotations, identify and clean the noise, and align the annotation definitions of these datasets to merge a larger dataset, termed with Open-Tables. Moreover, to enrich the data sources, we propose a new dataset, termed with ICT-TD, using the PDF files of Information and communication technologies (ICT) commodities which is a different domain containing unique samples that hardly appear in open datasets. To ensure the label quality of the dataset, we annotated the dataset manually following the guidance of a domain expert. The proposed dataset has a larger intra-variance and smaller inter-variance, making it more challenging and can be a sample of actual cases in the business context. We built strong baselines using various state-of-the-art object detection models and also built the baselines in the cross-domain setting. Our experimental results show that the domain difference among existing open datasets are small, even they have different data-sources. Our proposed Open-tables and ICT-TD are more suitable for the cross domain setting, and can provide more reliable evaluation for model because of their high quality and consistent annotations.
Efficient Information Sharing in ICT Supply Chain Social Network via Table Structure Recognition
Nov 03, 2022

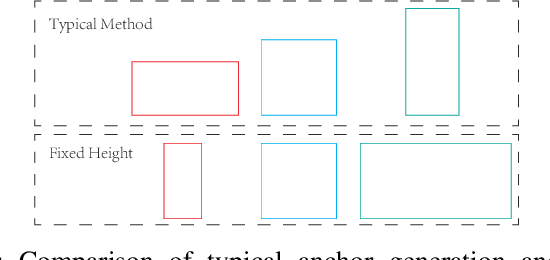

The global Information and Communications Technology (ICT) supply chain is a complex network consisting of all types of participants. It is often formulated as a Social Network to discuss the supply chain network's relations, properties, and development in supply chain management. Information sharing plays a crucial role in improving the efficiency of the supply chain, and datasheets are the most common data format to describe e-component commodities in the ICT supply chain because of human readability. However, with the surging number of electronic documents, it has been far beyond the capacity of human readers, and it is also challenging to process tabular data automatically because of the complex table structures and heterogeneous layouts. Table Structure Recognition (TSR) aims to represent tables with complex structures in a machine-interpretable format so that the tabular data can be processed automatically. In this paper, we formulate TSR as an object detection problem and propose to generate an intuitive representation of a complex table structure to enable structuring of the tabular data related to the commodities. To cope with border-less and small layouts, we propose a cost-sensitive loss function by considering the detection difficulty of each class. Besides, we propose a novel anchor generation method using the character of tables that columns in a table should share an identical height, and rows in a table should share the same width. We implement our proposed method based on Faster-RCNN and achieve 94.79% on mean Average Precision (AP), and consistently improve more than 1.5% AP for different benchmark models.
Handling big tabular data of ICT supply chains: a multi-task, machine-interpretable approach
Aug 11, 2022
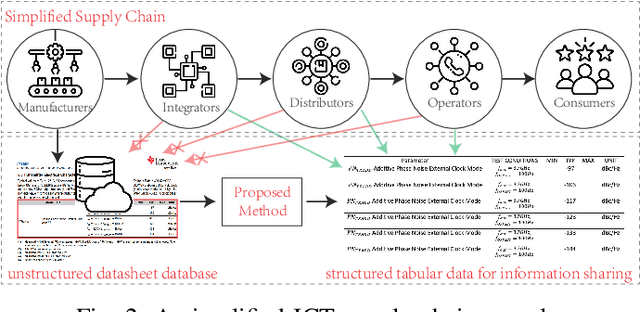
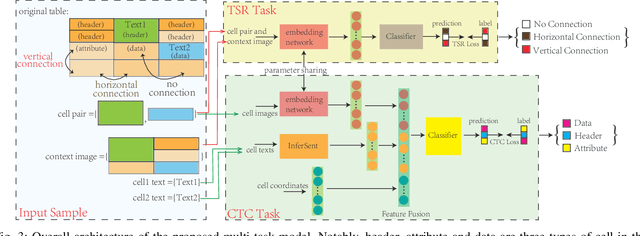
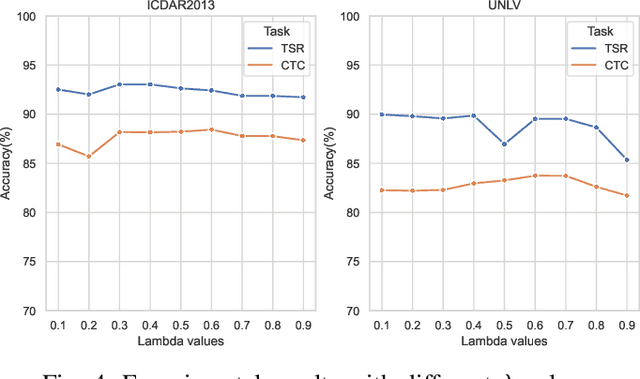
Due to the characteristics of Information and Communications Technology (ICT) products, the critical information of ICT devices is often summarized in big tabular data shared across supply chains. Therefore, it is critical to automatically interpret tabular structures with the surging amount of electronic assets. To transform the tabular data in electronic documents into a machine-interpretable format and provide layout and semantic information for information extraction and interpretation, we define a Table Structure Recognition (TSR) task and a Table Cell Type Classification (CTC) task. We use a graph to represent complex table structures for the TSR task. Meanwhile, table cells are categorized into three groups based on their functional roles for the CTC task, namely Header, Attribute, and Data. Subsequently, we propose a multi-task model to solve the defined two tasks simultaneously by using the text modal and image modal features. Our experimental results show that our proposed method can outperform state-of-the-art methods on ICDAR2013 and UNLV datasets.
Table Structure Recognition with Conditional Attention
Mar 08, 2022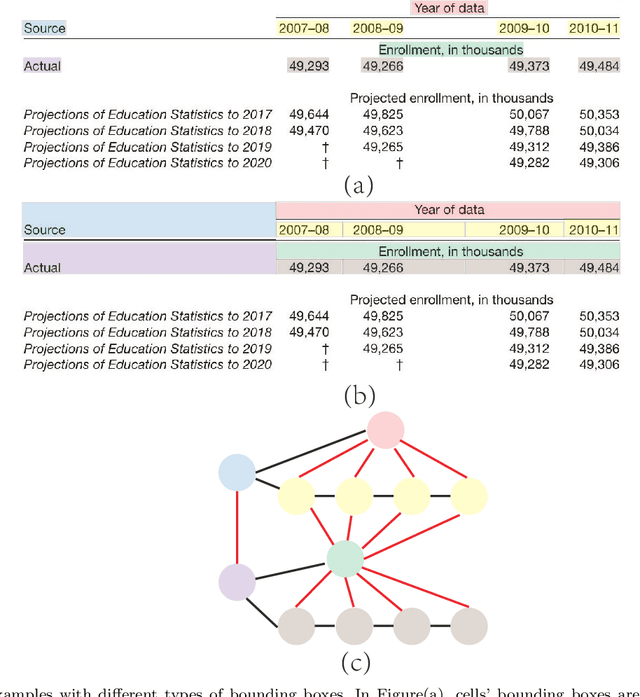



Tabular data in digital documents is widely used to express compact and important information for readers. However, it is challenging to parse tables from unstructured digital documents, such as PDFs and images, into machine-readable format because of the complexity of table structures and the missing of meta-information. Table Structure Recognition (TSR) problem aims to recognize the structure of a table and transform the unstructured tables into a structured and machine-readable format so that the tabular data can be further analysed by the down-stream tasks, such as semantic modeling and information retrieval. In this study, we hypothesize that a complicated table structure can be represented by a graph whose vertices and edges represent the cells and association between cells, respectively. Then we define the table structure recognition problem as a cell association classification problem and propose a conditional attention network (CATT-Net). The experimental results demonstrate the superiority of our proposed method over the state-of-the-art methods on various datasets. Besides, we investigate whether the alignment of a cell bounding box or a text-focused approach has more impact on the model performance. Due to the lack of public dataset annotations based on these two approaches, we further annotate the ICDAR2013 dataset providing both types of bounding boxes, which can be a new benchmark dataset for evaluating the methods in this field. Experimental results show that the alignment of a cell bounding box can help improve the Micro-averaged F1 score from 0.915 to 0.963, and the Macro-average F1 score from 0.787 to 0.923.