 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in Emails using Machine Learning and Header Information
Mar 19, 2022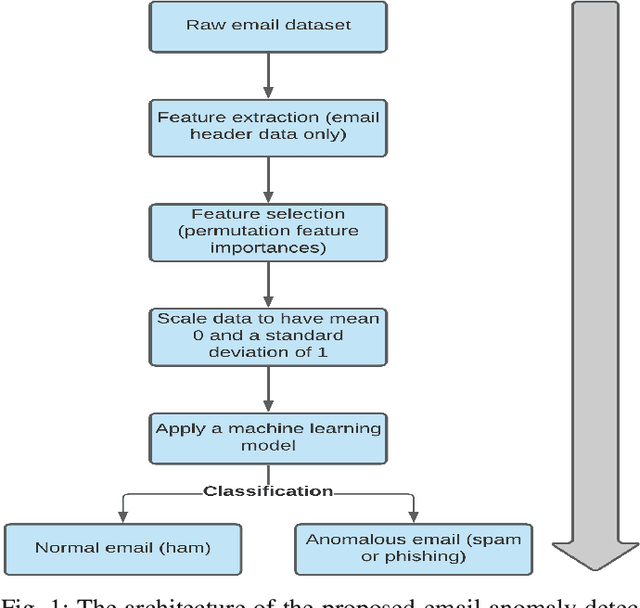
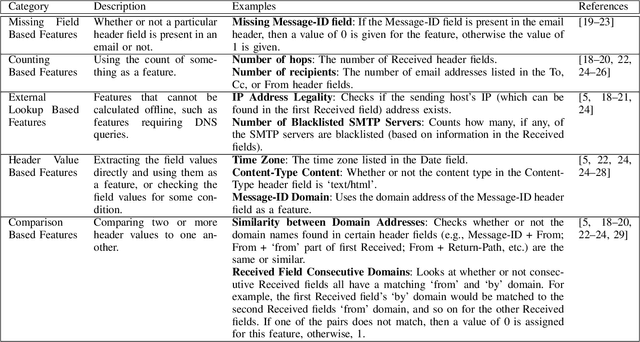
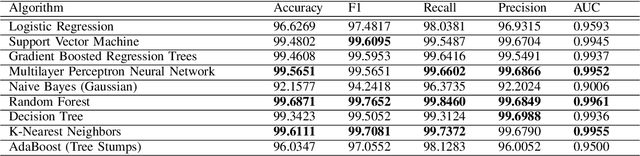
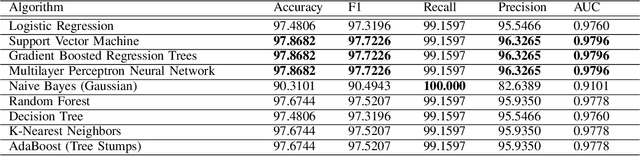
Anomalies in emails such as phishing and spam present major security risks such as the loss of privacy, money, and brand reputation to both individuals and organizations. Previous studies on email anomaly detection relied on a single type of anomaly and the analysis of the email body and subject content. A drawback of this approach is that it takes into account the written language of the email content. To overcome this deficit, this study conducted feature extraction and selection on email header datasets and leveraged both multi and one-class anomaly detection approaches. Experimental analysis results obtained demonstrate that email header information only is enough to reliably detect spam and phishing emails. Supervised learning algorithms such as Random Forest, SVM, MLP, KNN, and their stacked ensembles were found to be very successful, achieving high accuracy scores of 97% for phishing and 99% for spam emails. One-class classification with One-Class SVM achieved accuracy scores of 87% and 89% with spam and phishing emails, respectively. Real-world email filtering applications will benefit from the use of only the header information in terms of resources utilization and efficiency.