 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025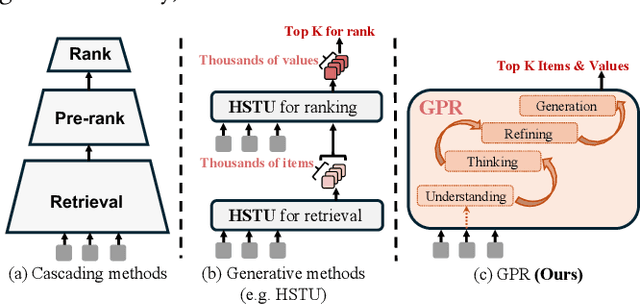
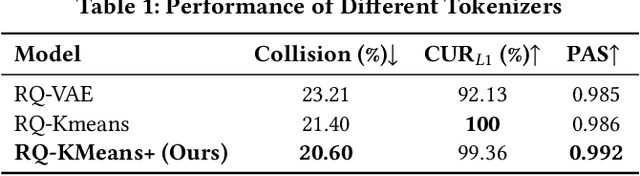
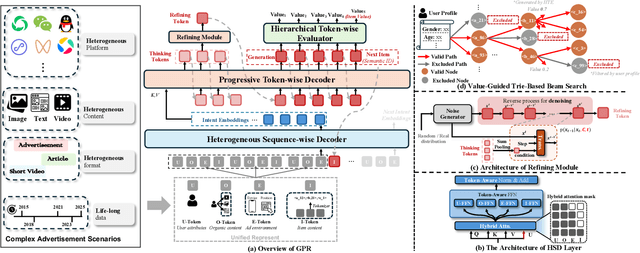
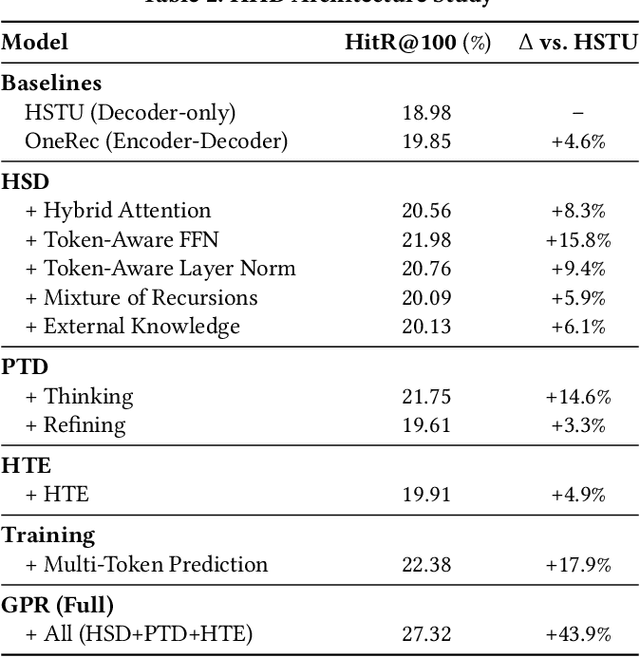
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
A Big Data Lake for Multilevel Streaming Analytics
Sep 25, 2020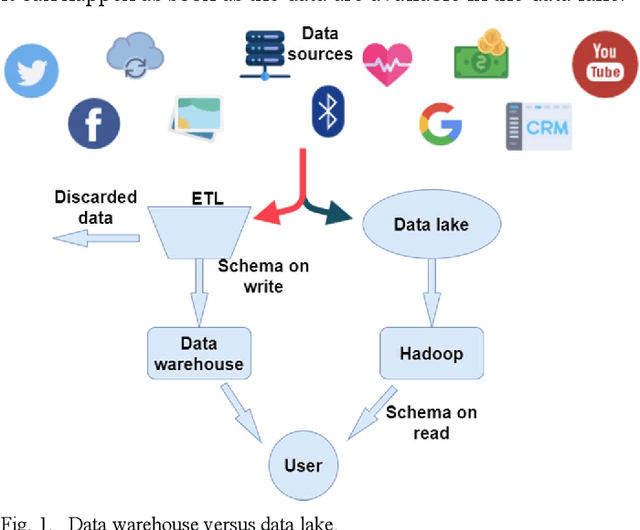
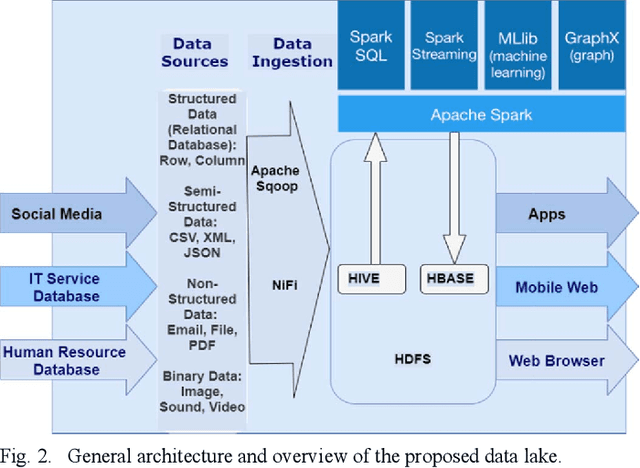
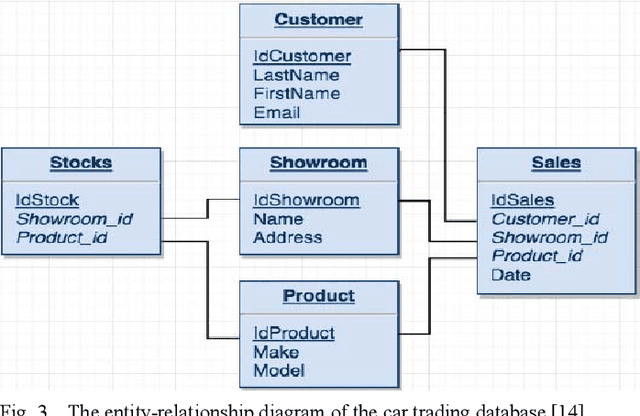
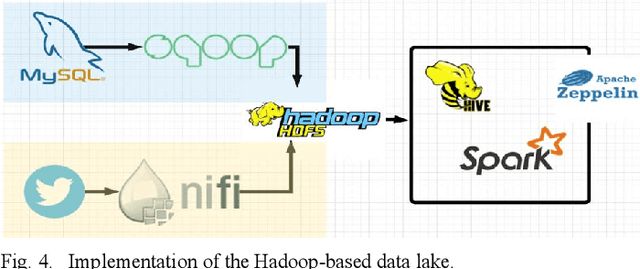
Large organizations are seeking to create new architectures and scalable platforms to effectively handle data management challenges due to the explosive nature of data rarely seen in the past. These data management challenges are largely posed by the availability of streaming data at high velocity from various sources in multiple formats. The changes in data paradigm have led to the emergence of new data analytics and management architecture. This paper focuses on storing high volume, velocity and variety data in the raw formats in a data storage architecture called a data lake. First, we present our study on the limitations of traditional data warehouses in handling recent changes in data paradigms. We discuss and compare different open source and commercial platforms that can be used to develop a data lake. We then describe our end-to-end data lake design and implementation approach using the Hadoop Distributed File System (HDFS) on the Hadoop Data Platform (HDP). Finally, we present a real-world data lake development use case for data stream ingestion, staging, and multilevel streaming analytics which combines structured and unstructured data. This study can serve as a guide for individuals or organizations planning to implement a data lake solution for their use cases.