 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaultExplainer: Leveraging Large Language Models for Interpretable Fault Detection and Diagnosis
Dec 19, 2024Machine learning algorithms are increasingly being applied to fault detection and diagnosis (FDD) in chemical processes. However, existing data-driven FDD platforms often lack interpretability for process operators and struggle to identify root causes of previously unseen faults. This paper presents FaultExplainer, an interactive tool designed to improve fault detection, diagnosis, and explanation in the Tennessee Eastman Process (TEP). FaultExplainer integrates real-time sensor data visualization, Principal Component Analysis (PCA)-based fault detection, and identification of top contributing variables within an interactive user interface powered by large language models (LLMs). We evaluate the LLMs' reasoning capabilities in two scenarios: one where historical root causes are provided, and one where they are not to mimic the challenge of previously unseen faults. Experimental results using GPT-4o and o1-preview models demonstrate the system's strengths in generating plausible and actionable explanations, while also highlighting its limitations, including reliance on PCA-selected features and occasional hallucinations.
Untangling Braids with Multi-agent Q-Learning
Sep 29, 2021
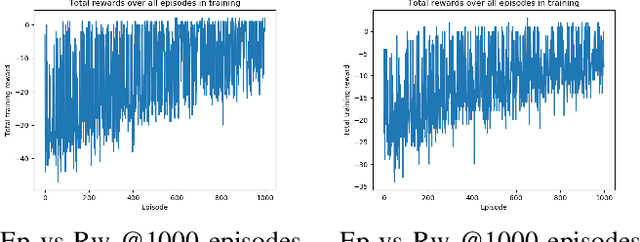

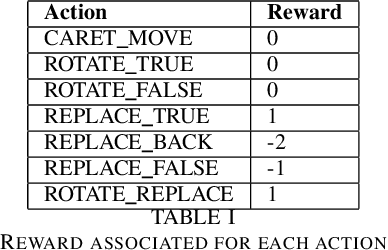
We use reinforcement learning to tackle the problem of untangling braids. We experiment with braids with 2 and 3 strands. Two competing players learn to tangle and untangle a braid. We interface the braid untangling problem with the OpenAI Gym environment, a widely used way of connecting agents to reinforcement learning problems. The results provide evidence that the more we train the system, the better the untangling player gets at untangling braids. At the same time, our tangling player produces good examples of tangled braids.