 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoLlama: Generating Endless and Coherent Panoramas with Next-Token-Prediction LLMs
Nov 24, 2024



Panoramic Image Generation has emerged as an important task in image generation, driven by growing demands for large-scale visuals in creative and technical applications. While diffusion models have dominated this field, they face inherent limitations, including the multilevel-coherence challenge and implementation complexity, leading to suboptimal outcomes. In this paper, we introduce PanoLlama, a novel framework that redefines panoramic image generation as a next-token prediction task. Building on the pre-trained LlamaGen architecture, we generate images in an autoregressive manner and develop an expansion strategy to handle size limitations. This method aligns with the image token structure in a crop-wise and training-free manner, resulting in high-quality panoramas with minimal seams and maximum scalability. PanoLlama demonstrates its effectiveness and versatility in our experiments, achieving the best overall performance while offering flexibility for multi-scale, multi-layout, and multi-guidance generation. It overcomes the challenges that diffusion-based methods fail to address, setting a new paradigm for panoramic image generation tasks. Code is available at https://github.com/0606zt/PanoLlama.
Multi-Scale Diffusion: Enhancing Spatial Layout in High-Resolution Panoramic Image Generation
Oct 24, 2024
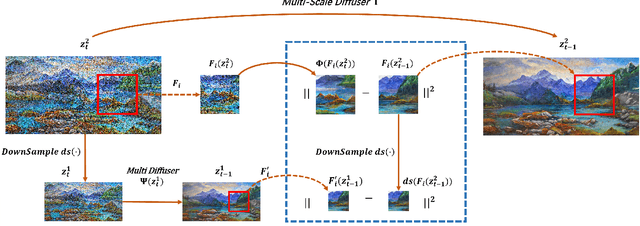

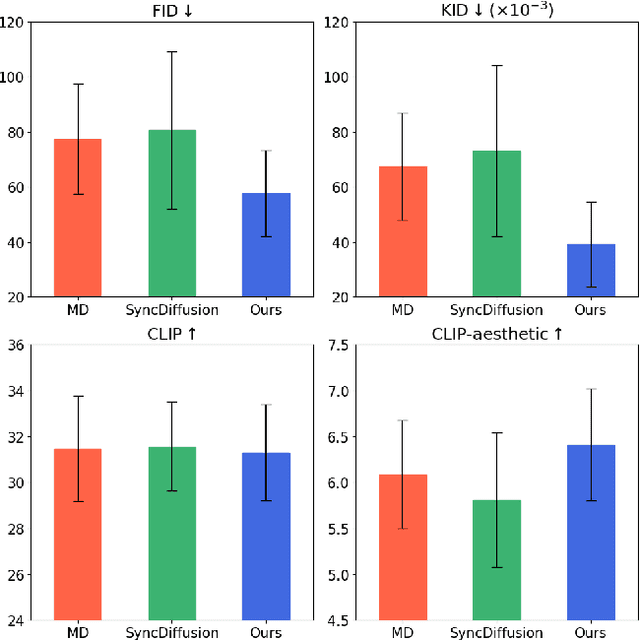
Diffusion models have recently gained recognition for generating diverse and high-quality content, especially in the domain of image synthesis. These models excel not only in creating fixed-size images but also in producing panoramic images. However, existing methods often struggle with spatial layout consistency when producing high-resolution panoramas, due to the lack of guidance of the global image layout. In this paper, we introduce the Multi-Scale Diffusion (MSD) framework, a plug-and-play module that extends the existing panoramic image generation framework to multiple resolution levels. By utilizing gradient descent techniques, our method effectively incorporates structural information from low-resolution images into high-resolution outputs. A comprehensive evaluation of the proposed method was conducted, comparing it with the prior works in qualitative and quantitative dimensions. The evaluation results demonstrate that our method significantly outperforms others in generating coherent high-resolution panoramas.
TwinDiffusion: Enhancing Coherence and Efficiency in Panoramic Image Generation with Diffusion Models
Apr 30, 2024Diffusion models have emerged as effective tools for generating diverse and high-quality content. However, their capability in high-resolution image generation, particularly for panoramic images, still faces challenges such as visible seams and incoherent transitions. In this paper, we propose TwinDiffusion, an optimized framework designed to address these challenges through two key innovations: Crop Fusion for quality enhancement and Cross Sampling for efficiency optimization. We introduce a training-free optimizing stage to refine the similarity of the adjacent image areas, as well as an interleaving sampling strategy to yield dynamic patches during the cropping process. A comprehensive evaluation is conducted to compare TwinDiffusion with the existing methods, considering factors including coherence, fidelity, compatibility, and efficiency. The results demonstrate the superior performance of our approach in generating seamless and coherent panoramas, setting a new standard in quality and efficiency for panoramic image generation.
The negation of permutation mass function
Mar 13, 2024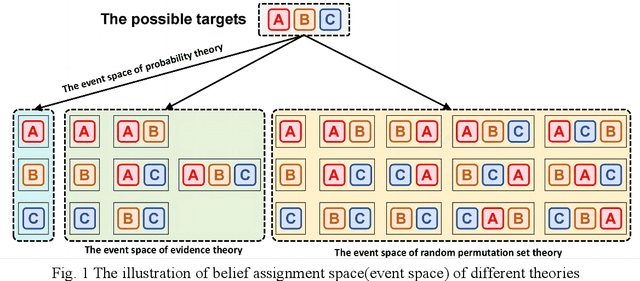



Negation is an important perspective of knowledge representation. Existing negation methods are mainly applied in probability theory, evidence theory and complex evidence theory. As a generalization of evidence theory, random permutation sets theory may represent information more precisely. However, how to apply the concept of negation to random permutation sets theory has not been studied. In this paper, the negation of permutation mass function is proposed. Moreover, in the negation process, the convergence of proposed negation method is verified. The trends of uncertainty and dissimilarity after each negation operation are investigated. Numerical examples are used to demonstrate the rationality of the proposed method.
Combination of interval-valued belief structures based on belief entropy
Nov 27, 2020
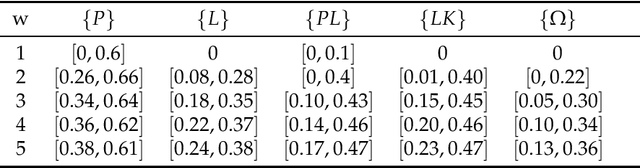


This paper investigates the issues of combination and normalization of interval-valued belief structures within the framework of Dempster-Shafer theory of evidence. Existing approaches are reviewed and thoroughly analyzed. The advantages and drawbacks of previous approach are presented. A new optimality approach based on uncertainty measure is developed, where the problem of combining interval-valued belief structures degenerates into combining basic probability assignments. Numerical examples are provided to illustrate the rationality of the proposed approach.
A new approach for generation of generalized basic probability assignment in the evidence theory
Apr 06, 2020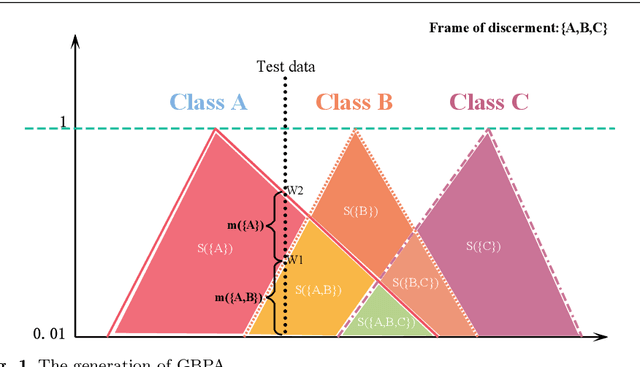


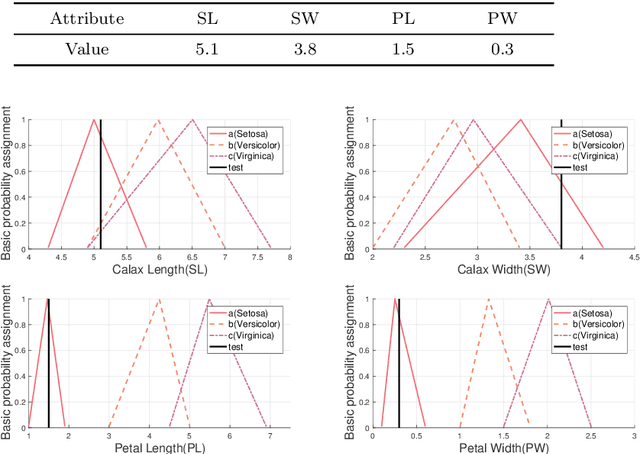
The process of information fusion needs to deal with a large number of uncertain information with multi-source, heterogeneity, inaccuracy, unreliability, and incompleteness. In practical engineering applications, Dempster-Shafer evidence theory is widely used in multi-source information fusion owing to its effectiveness in data fusion. Information sources have an important impact on multi-source information fusion in an environment of complex, unstable, uncertain, and incomplete characteristics. To address multi-source information fusion problem, this paper considers the situation of uncertain information modeling from the closed world to the open world assumption and studies the generation of basic probability assignment (BPA) with incomplete information. In this paper, a new method is proposed to generate generalized basic probability assignment (GBPA) based on the triangular fuzzy number model under the open world assumption. The proposed method can not only be used in different complex environments simply and flexibly, but also have less information loss in information processing. Finally, a series of comprehensive experiments basing on the UCI data sets are used to verify the rationality and superiority of the proposed method.
Unsupervised Disentangled Representation Learning with Analogical Relations
Apr 25, 2018


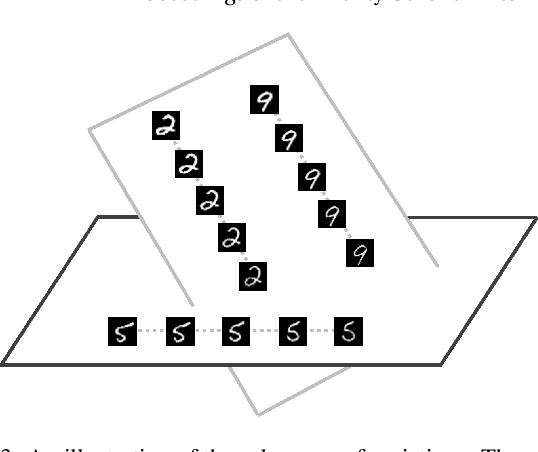
Learning the disentangled representation of interpretable generative factors of data is one of the foundations to allow artificial intelligence to think like people. In this paper, we propose the analogical training strategy for the unsupervised disentangled representation learning in generative models. The analogy is one of the typical cognitive processes, and our proposed strategy is based on the observation that sample pairs in which one is different from the other in one specific generative factor show the same analogical relation. Thus, the generator is trained to generate sample pairs from which a designed classifier can identify the underlying analogical relation. In addition, we propose a disentanglement metric called the subspace score, which is inspired by subspace learning methods and does not require supervised information. Experiments show that our proposed training strategy allows the generative models to find the disentangled factors, and that our methods can give competitive performances as compared with the state-of-the-art methods.