 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ByteDance Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Paper and Code
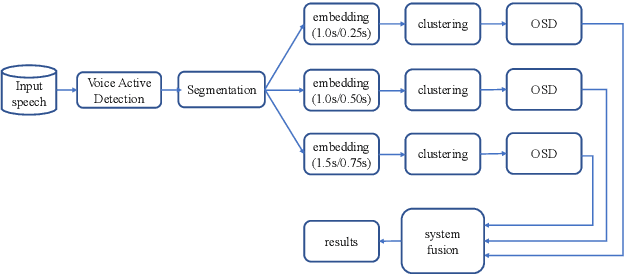

This paper describes the ByteDance speaker diarization system for the fourth track of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). The VoxSRC-21 provides both the dev set and test set of VoxConverse for use in validation and a standalone test set for evaluation. We first collect the duration and signal-to-noise ratio (SNR) of all audio and find that the distribution of the VoxConverse's test set and the VoxSRC-21's test set is more closer. Our system consists of voice active detection (VAD), speaker embedding extraction, spectral clustering followed by a re-clustering step based on agglomerative hierarchical clustering (AHC) and overlapped speech detection and handling. Finally, we integrate systems with different time scales using DOVER-Lap. Our best system achieves 5.15\% of the diarization error rate (DER) on evaluation set, ranking the second at the diarization track of the challenge.