 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint System Latency and Data Freshness Optimization for Cache-enabled Mobile Crowdsensing Networks
Jan 24, 2025



Mobile crowdsensing (MCS) networks enable large-scale data collection by leveraging the ubiquity of mobile devices. However, frequent sensing and data transmission can lead to significant resource consumption. To mitigate this issue, edge caching has been proposed as a solution for storing recently collected data. Nonetheless, this approach may compromise data freshness. In this paper, we investigate the trade-off between re-using cached task results and re-sensing tasks in cache-enabled MCS networks, aiming to minimize system latency while maintaining information freshness. To this end, we formulate a weighted delay and age of information (AoI) minimization problem, jointly optimizing sensing decisions, user selection, channel selection, task allocation, and caching strategies. The problem is a mixed-integer non-convex programming problem which is intractable. Therefore, we decompose the long-term problem into sequential one-shot sub-problems and design a framework that optimizes system latency, task sensing decision, and caching strategy subproblems. When one task is re-sensing, the one-shot problem simplifies to the system latency minimization problem, which can be solved optimally. The task sensing decision is then made by comparing the system latency and AoI. Additionally, a Bayesian update strategy is developed to manage the cached task results. Building upon this framework, we propose a lightweight and time-efficient algorithm that makes real-time decisions for the long-term optimization problem. Extensive simulation results validate the effectiveness of our approach.
Q-Distribution guided Q-learning for offline reinforcement learning: Uncertainty penalized Q-value via consistency model
Oct 27, 2024



``Distribution shift'' is the main obstacle to the success of offline reinforcement learning. A learning policy may take actions beyond the behavior policy's knowledge, referred to as Out-of-Distribution (OOD) actions. The Q-values for these OOD actions can be easily overestimated. As a result, the learning policy is biased by using incorrect Q-value estimates. One common approach to avoid Q-value overestimation is to make a pessimistic adjustment. Our key idea is to penalize the Q-values of OOD actions associated with high uncertainty. In this work, we propose Q-Distribution Guided Q-Learning (QDQ), which applies a pessimistic adjustment to Q-values in OOD regions based on uncertainty estimation. This uncertainty measure relies on the conditional Q-value distribution, learned through a high-fidelity and efficient consistency model. Additionally, to prevent overly conservative estimates, we introduce an uncertainty-aware optimization objective for updating the Q-value function. The proposed QDQ demonstrates solid theoretical guarantees for the accuracy of Q-value distribution learning and uncertainty measurement, as well as the performance of the learning policy. QDQ consistently shows strong performance on the D4RL benchmark and achieves significant improvements across many tasks.
Global-Local Convolution with Spiking Neural Networks for Energy-efficient Keyword Spotting
Jun 19, 2024



Thanks to Deep Neural Networks (DNNs), the accuracy of Keyword Spotting (KWS) has made substantial progress. However, as KWS systems are usually implemented on edge devices, energy efficiency becomes a critical requirement besides performance. Here, we take advantage of spiking neural networks' energy efficiency and propose an end-to-end lightweight KWS model. The model consists of two innovative modules: 1) Global-Local Spiking Convolution (GLSC) module and 2) Bottleneck-PLIF module. Compared to the hand-crafted feature extraction methods, the GLSC module achieves speech feature extraction that is sparser, more energy-efficient, and yields better performance. The Bottleneck-PLIF module further processes the signals from GLSC with the aim to achieve higher accuracy with fewer parameters. Extensive experiments are conducted on the Google Speech Commands Dataset (V1 and V2). The results show our method achieves competitive performance among SNN-based KWS models with fewer parameters.
Enhanced Bayesian Personalized Ranking for Robust Hard Negative Sampling in Recommender Systems
Mar 28, 2024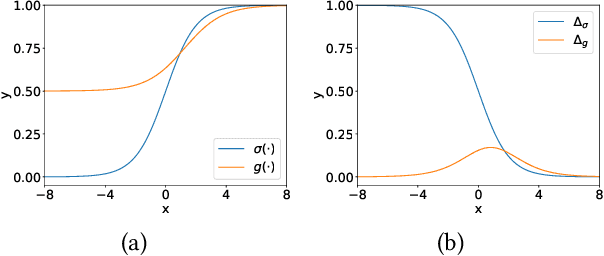
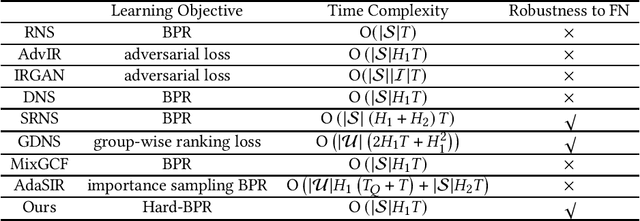

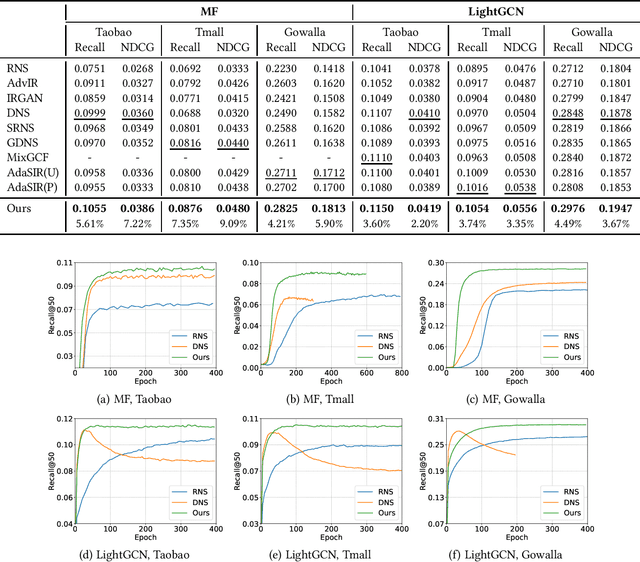
In implicit collaborative filtering, hard negative mining techniques are developed to accelerate and enhance the recommendation model learning. However, the inadvertent selection of false negatives remains a major concern in hard negative sampling, as these false negatives can provide incorrect information and mislead the model learning. To date, only a small number of studies have been committed to solve the false negative problem, primarily focusing on designing sophisticated sampling algorithms to filter false negatives. In contrast, this paper shifts its focus to refining the loss function. We find that the original Bayesian Personalized Ranking (BPR), initially designed for uniform negative sampling, is inadequate in adapting to hard sampling scenarios. Hence, we introduce an enhanced Bayesian Personalized Ranking objective, named as Hard-BPR, which is specifically crafted for dynamic hard negative sampling to mitigate the influence of false negatives. This method is simple yet efficient for real-world deployment. Extensive experiments conducted on three real-world datasets demonstrate the effectiveness and robustness of our approach, along with the enhanced ability to distinguish false negatives.
Extreme Parkour with Legged Robots
Sep 25, 2023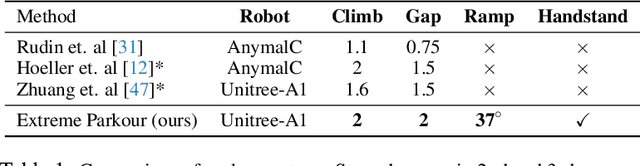
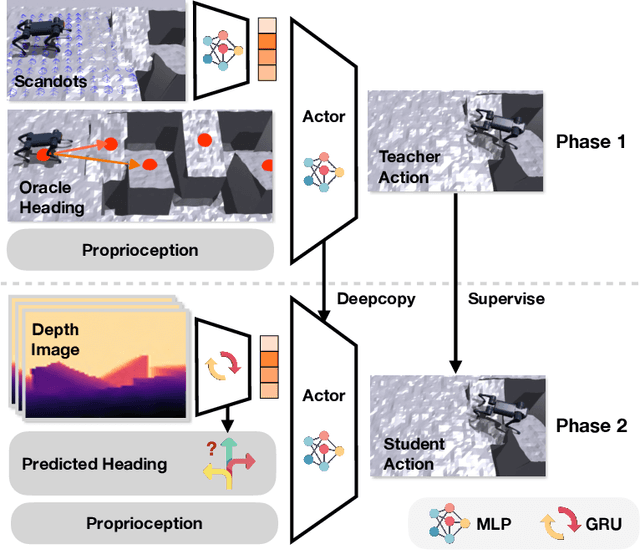

Humans can perform parkour by traversing obstacles in a highly dynamic fashion requiring precise eye-muscle coordination and movement. Getting robots to do the same task requires overcoming similar challenges. Classically, this is done by independently engineering perception, actuation, and control systems to very low tolerances. This restricts them to tightly controlled settings such as a predetermined obstacle course in labs. In contrast, humans are able to learn parkour through practice without significantly changing their underlying biology. In this paper, we take a similar approach to developing robot parkour on a small low-cost robot with imprecise actuation and a single front-facing depth camera for perception which is low-frequency, jittery, and prone to artifacts. We show how a single neural net policy operating directly from a camera image, trained in simulation with large-scale RL, can overcome imprecise sensing and actuation to output highly precise control behavior end-to-end. We show our robot can perform a high jump on obstacles 2x its height, long jump across gaps 2x its length, do a handstand and run across tilted ramps, and generalize to novel obstacle courses with different physical properties. Parkour videos at https://extreme-parkour.github.io/
Soft BPR Loss for Dynamic Hard Negative Sampling in Recommender Systems
Nov 25, 2022In recommender systems, leveraging Graph Neural Networks (GNNs) to formulate the bipartite relation between users and items is a promising way. However, powerful negative sampling methods that is adapted to GNN-based recommenders still requires a lot of efforts. One critical gap is that it is rather tough to distinguish real negatives from massive unobserved items during hard negative sampling. Towards this problem, this paper develops a novel hard negative sampling method for GNN-based recommendation systems by simply reformulating the loss function. We conduct various experiments on three datasets, demonstrating that the method proposed outperforms a set of state-of-the-art benchmarks.
Learning Perception-Aware Agile Flight in Cluttered Environments
Oct 04, 2022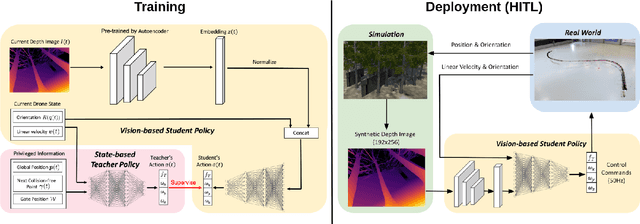

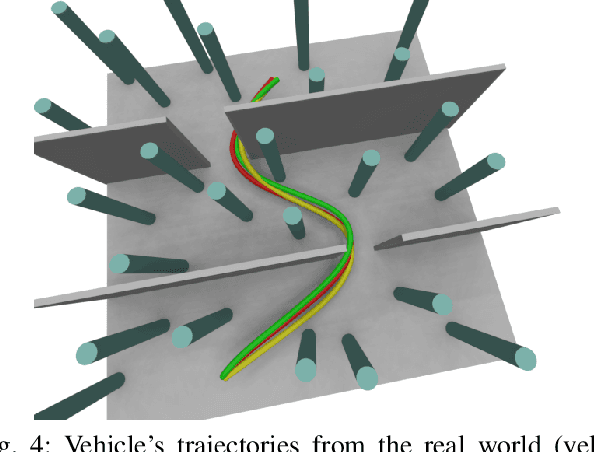
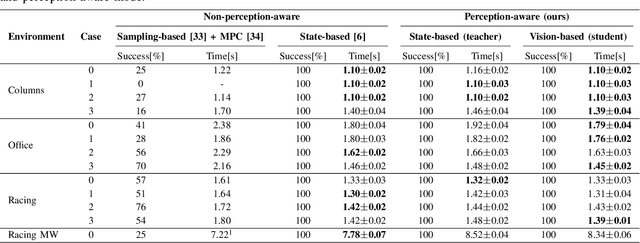
Recently, neural control policies have outperformed existing model-based planning-and-control methods for autonomously navigating quadrotors through cluttered environments in minimum time. However, they are not perception aware, a crucial requirement in vision-based navigation due to the camera's limited field of view and the underactuated nature of a quadrotor. We propose a method to learn neural network policies that achieve perception-aware, minimum-time flight in cluttered environments. Our method combines imitation learning and reinforcement learning (RL) by leveraging a privileged learning-by-cheating framework. Using RL, we first train a perception-aware teacher policy with full-state information to fly in minimum time through cluttered environments. Then, we use imitation learning to distill its knowledge into a vision-based student policy that only perceives the environment via a camera. Our approach tightly couples perception and control, showing a significant advantage in computation speed (10x faster) and success rate. We demonstrate the closed-loop control performance using a physical quadrotor and hardware-in-the-loop simulation at speeds up to 50km/h.