 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAPG: Split and Aggregate Policy Gradients
Jul 29, 2024Despite extreme sample inefficiency, on-policy reinforcement learning, aka policy gradients, has become a fundamental tool in decision-making problems. With the recent advances in GPU-driven simulation, the ability to collect large amounts of data for RL training has scaled exponentially. However, we show that current RL methods, e.g. PPO, fail to ingest the benefit of parallelized environments beyond a certain point and their performance saturates. To address this, we propose a new on-policy RL algorithm that can effectively leverage large-scale environments by splitting them into chunks and fusing them back together via importance sampling. Our algorithm, termed SAPG, shows significantly higher performance across a variety of challenging environments where vanilla PPO and other strong baselines fail to achieve high performance. Website at https://sapg-rl.github.io/
SPIN: Simultaneous Perception, Interaction and Navigation
May 13, 2024While there has been remarkable progress recently in the fields of manipulation and locomotion, mobile manipulation remains a long-standing challenge. Compared to locomotion or static manipulation, a mobile system must make a diverse range of long-horizon tasks feasible in unstructured and dynamic environments. While the applications are broad and interesting, there are a plethora of challenges in developing these systems such as coordination between the base and arm, reliance on onboard perception for perceiving and interacting with the environment, and most importantly, simultaneously integrating all these parts together. Prior works approach the problem using disentangled modular skills for mobility and manipulation that are trivially tied together. This causes several limitations such as compounding errors, delays in decision-making, and no whole-body coordination. In this work, we present a reactive mobile manipulation framework that uses an active visual system to consciously perceive and react to its environment. Similar to how humans leverage whole-body and hand-eye coordination, we develop a mobile manipulator that exploits its ability to move and see, more specifically -- to move in order to see and to see in order to move. This allows it to not only move around and interact with its environment but also, choose "when" to perceive "what" using an active visual system. We observe that such an agent learns to navigate around complex cluttered scenarios while displaying agile whole-body coordination using only ego-vision without needing to create environment maps. Results visualizations and videos at https://spin-robot.github.io/
Dexterous Functional Grasping
Dec 05, 2023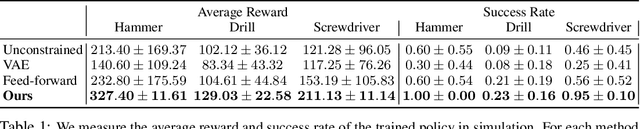

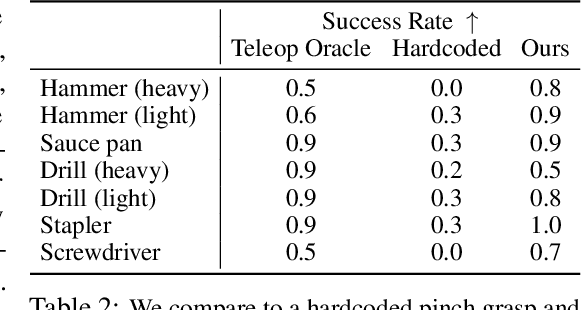
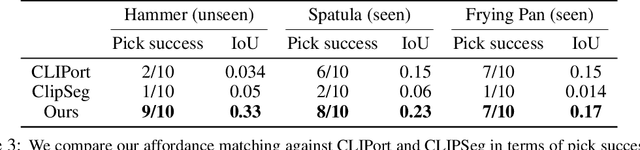
While there have been significant strides in dexterous manipulation, most of it is limited to benchmark tasks like in-hand reorientation which are of limited utility in the real world. The main benefit of dexterous hands over two-fingered ones is their ability to pickup tools and other objects (including thin ones) and grasp them firmly to apply force. However, this task requires both a complex understanding of functional affordances as well as precise low-level control. While prior work obtains affordances from human data this approach doesn't scale to low-level control. Similarly, simulation training cannot give the robot an understanding of real-world semantics. In this paper, we aim to combine the best of both worlds to accomplish functional grasping for in-the-wild objects. We use a modular approach. First, affordances are obtained by matching corresponding regions of different objects and then a low-level policy trained in sim is run to grasp it. We propose a novel application of eigengrasps to reduce the search space of RL using a small amount of human data and find that it leads to more stable and physically realistic motion. We find that eigengrasp action space beats baselines in simulation and outperforms hardcoded grasping in real and matches or outperforms a trained human teleoperator. Results visualizations and videos at https://dexfunc.github.io/
Extreme Parkour with Legged Robots
Sep 25, 2023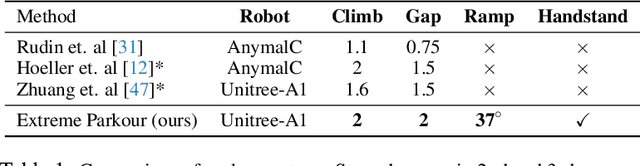
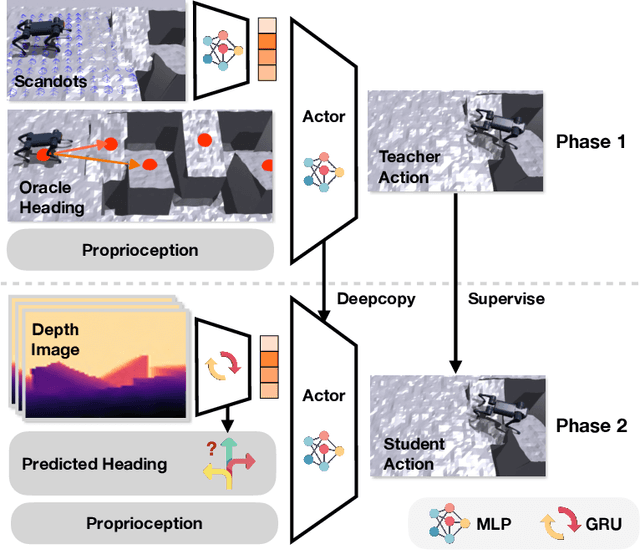
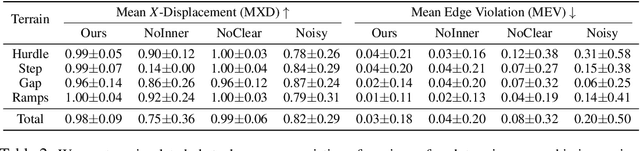

Humans can perform parkour by traversing obstacles in a highly dynamic fashion requiring precise eye-muscle coordination and movement. Getting robots to do the same task requires overcoming similar challenges. Classically, this is done by independently engineering perception, actuation, and control systems to very low tolerances. This restricts them to tightly controlled settings such as a predetermined obstacle course in labs. In contrast, humans are able to learn parkour through practice without significantly changing their underlying biology. In this paper, we take a similar approach to developing robot parkour on a small low-cost robot with imprecise actuation and a single front-facing depth camera for perception which is low-frequency, jittery, and prone to artifacts. We show how a single neural net policy operating directly from a camera image, trained in simulation with large-scale RL, can overcome imprecise sensing and actuation to output highly precise control behavior end-to-end. We show our robot can perform a high jump on obstacles 2x its height, long jump across gaps 2x its length, do a handstand and run across tilted ramps, and generalize to novel obstacle courses with different physical properties. Parkour videos at https://extreme-parkour.github.io/
LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning
Sep 12, 2023


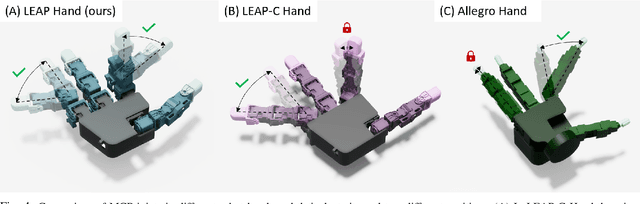
Dexterous manipulation has been a long-standing challenge in robotics. While machine learning techniques have shown some promise, results have largely been currently limited to simulation. This can be mostly attributed to the lack of suitable hardware. In this paper, we present LEAP Hand, a low-cost dexterous and anthropomorphic hand for machine learning research. In contrast to previous hands, LEAP Hand has a novel kinematic structure that allows maximal dexterity regardless of finger pose. LEAP Hand is low-cost and can be assembled in 4 hours at a cost of 2000 USD from readily available parts. It is capable of consistently exerting large torques over long durations of time. We show that LEAP Hand can be used to perform several manipulation tasks in the real world -- from visual teleoperation to learning from passive video data and sim2real. LEAP Hand significantly outperforms its closest competitor Allegro Hand in all our experiments while being 1/8th of the cost. We release detailed assembly instructions, the Sim2Real pipeline and a development platform with useful APIs on our website at https://leap-hand.github.io/
Legged Locomotion in Challenging Terrains using Egocentric Vision
Nov 14, 2022



Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world and is able to run in real-time on the limited compute of the robot. It can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain. Videos are at https://vision-locomotion.github.io
Coupling Vision and Proprioception for Navigation of Legged Robots
Dec 03, 2021
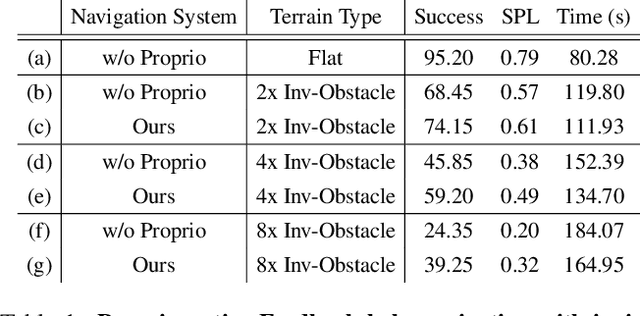
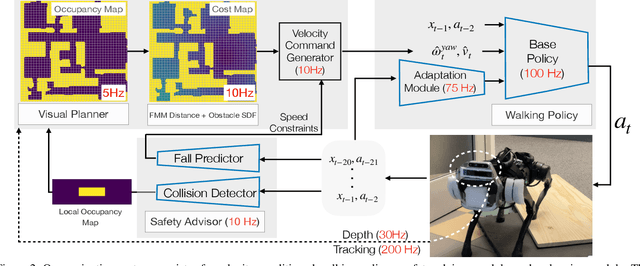
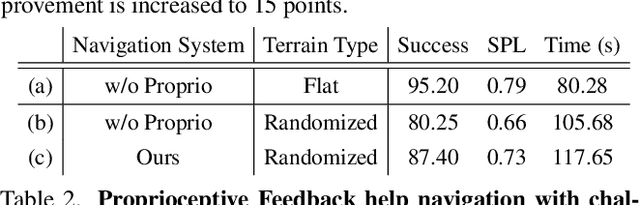
We exploit the complementary strengths of vision and proprioception to achieve point goal navigation in a legged robot. Legged systems are capable of traversing more complex terrain than wheeled robots, but to fully exploit this capability, we need the high-level path planner in the navigation system to be aware of the walking capabilities of the low-level locomotion policy on varying terrains. We achieve this by using proprioceptive feedback to estimate the safe operating limits of the walking policy, and to sense unexpected obstacles and terrain properties like smoothness or softness of the ground that may be missed by vision. The navigation system uses onboard cameras to generate an occupancy map and a corresponding cost map to reach the goal. The FMM (Fast Marching Method) planner then generates a target path. The velocity command generator takes this as input to generate the desired velocity for the locomotion policy using as input additional constraints, from the safety advisor, of unexpected obstacles and terrain determined speed limits. We show superior performance compared to wheeled robot (LoCoBot) baselines, and other baselines which have disjoint high-level planning and low-level control. We also show the real-world deployment of our system on a quadruped robot with onboard sensors and compute. Videos at https://navigation-locomotion.github.io/camera-ready
End-to-End Neuro-Symbolic Architecture for Image-to-Image Reasoning Tasks
Jun 06, 2021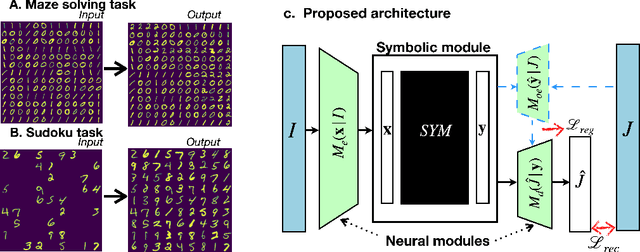
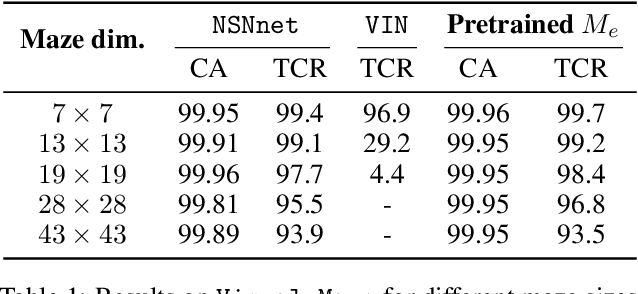

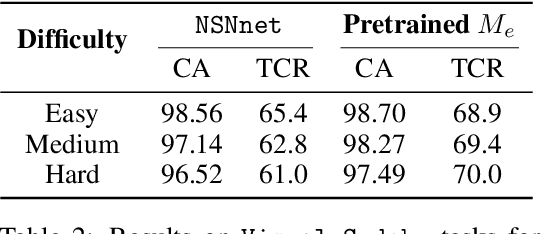
Neural models and symbolic algorithms have recently been combined for tasks requiring both perception and reasoning. Neural models ground perceptual input into a conceptual vocabulary, on which a classical reasoning algorithm is applied to generate output. A key limitation is that such neural-to-symbolic models can only be trained end-to-end for tasks where the output space is symbolic. In this paper, we study neural-symbolic-neural models for reasoning tasks that require a conversion from an image input (e.g., a partially filled sudoku) to an image output (e.g., the image of the completed sudoku). While designing such a three-step hybrid architecture may be straightforward, the key technical challenge is end-to-end training -- how to backpropagate without intermediate supervision through the symbolic component. We propose NSNnet, an architecture that combines an image reconstruction loss with a novel output encoder to generate a supervisory signal, develops update algorithms that leverage policy gradient methods for supervision, and optimizes loss using a novel subsampling heuristic. We experiment on problem settings where symbolic algorithms are easily specified: a visual maze solving task and a visual Sudoku solver where the supervision is in image form. Experiments show high accuracy with significantly less data compared to purely neural approaches.