 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neuro-Symbolic Architecture for Image-to-Image Reasoning Tasks
Paper and Code
Jun 06, 2021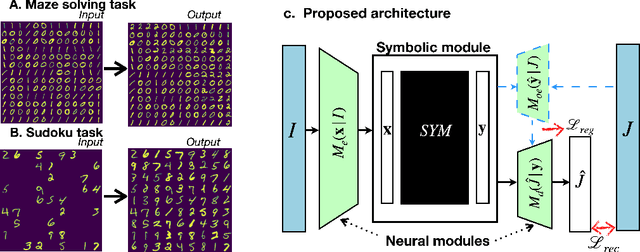
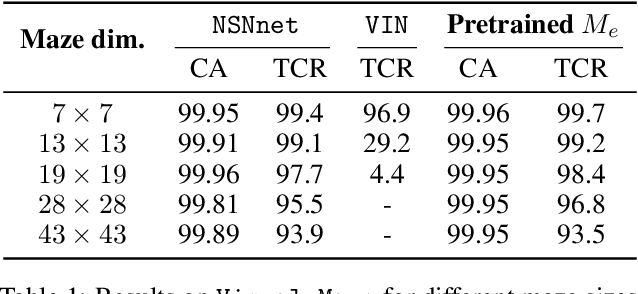

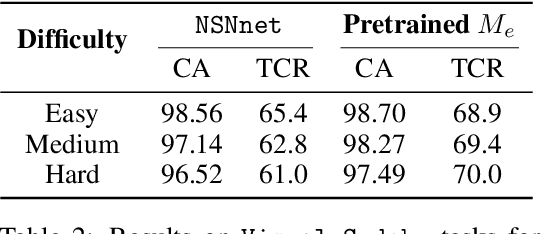
Neural models and symbolic algorithms have recently been combined for tasks requiring both perception and reasoning. Neural models ground perceptual input into a conceptual vocabulary, on which a classical reasoning algorithm is applied to generate output. A key limitation is that such neural-to-symbolic models can only be trained end-to-end for tasks where the output space is symbolic. In this paper, we study neural-symbolic-neural models for reasoning tasks that require a conversion from an image input (e.g., a partially filled sudoku) to an image output (e.g., the image of the completed sudoku). While designing such a three-step hybrid architecture may be straightforward, the key technical challenge is end-to-end training -- how to backpropagate without intermediate supervision through the symbolic component. We propose NSNnet, an architecture that combines an image reconstruction loss with a novel output encoder to generate a supervisory signal, develops update algorithms that leverage policy gradient methods for supervision, and optimizes loss using a novel subsampling heuristic. We experiment on problem settings where symbolic algorithms are easily specified: a visual maze solving task and a visual Sudoku solver where the supervision is in image form. Experiments show high accuracy with significantly less data compared to purely neural approaches.