 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Perception-Aware Agile Flight in Cluttered Environments
Paper and Code
Oct 04, 2022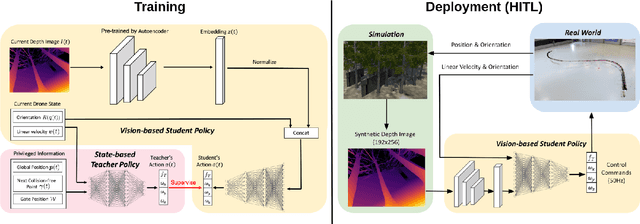

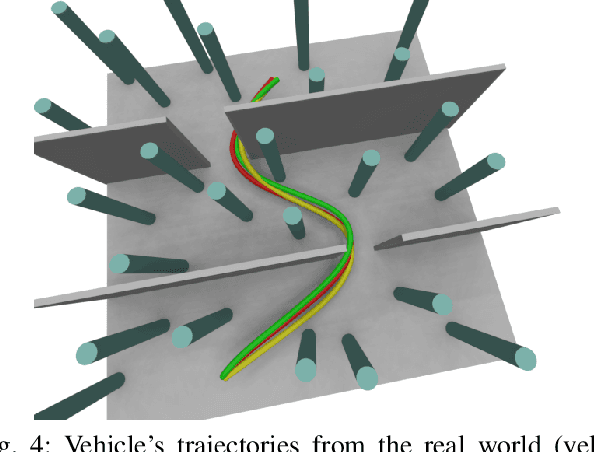
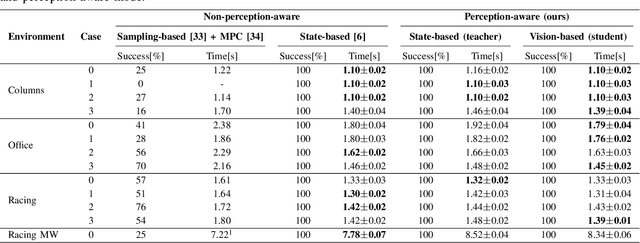
Recently, neural control policies have outperformed existing model-based planning-and-control methods for autonomously navigating quadrotors through cluttered environments in minimum time. However, they are not perception aware, a crucial requirement in vision-based navigation due to the camera's limited field of view and the underactuated nature of a quadrotor. We propose a method to learn neural network policies that achieve perception-aware, minimum-time flight in cluttered environments. Our method combines imitation learning and reinforcement learning (RL) by leveraging a privileged learning-by-cheating framework. Using RL, we first train a perception-aware teacher policy with full-state information to fly in minimum time through cluttered environments. Then, we use imitation learning to distill its knowledge into a vision-based student policy that only perceives the environment via a camera. Our approach tightly couples perception and control, showing a significant advantage in computation speed (10x faster) and success rate. We demonstrate the closed-loop control performance using a physical quadrotor and hardware-in-the-loop simulation at speeds up to 50km/h.