 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-way Node Popularity Model for Directed and Bipartite Networks
Dec 11, 2024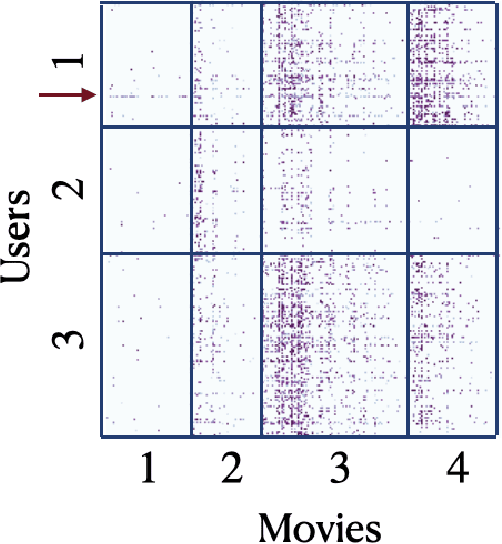
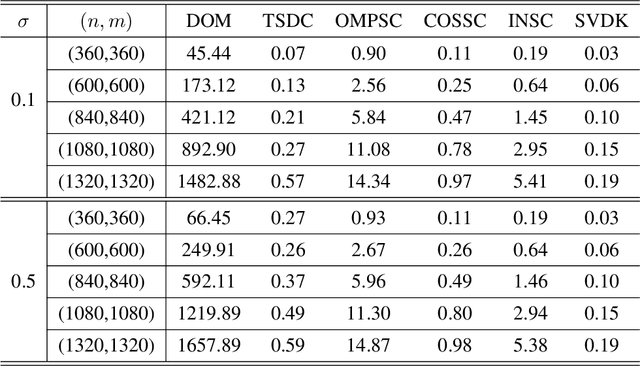
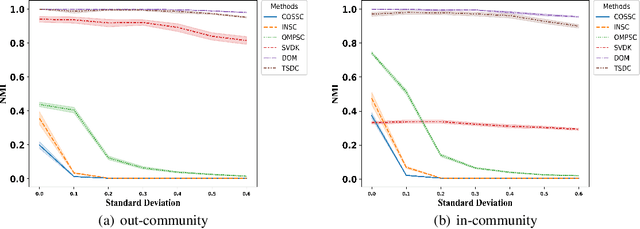
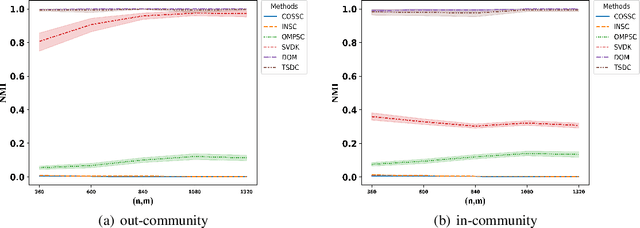
There has been extensive research on community detection in directed and bipartite networks. However, these studies often fail to consider the popularity of nodes in different communities, which is a common phenomenon in real-world networks. To address this issue, we propose a new probabilistic framework called the Two-Way Node Popularity Model (TNPM). The TNPM also accommodates edges from different distributions within a general sub-Gaussian family. We introduce the Delete-One-Method (DOM) for model fitting and community structure identification, and provide a comprehensive theoretical analysis with novel technical skills dealing with sub-Gaussian generalization. Additionally, we propose the Two-Stage Divided Cosine Algorithm (TSDC) to handle large-scale networks more efficiently. Our proposed methods offer multi-folded advantages in terms of estimation accuracy and computational efficiency, as demonstrated through extensive numerical studies. We apply our methods to two real-world applications, uncovering interesting findings.
Q-Distribution guided Q-learning for offline reinforcement learning: Uncertainty penalized Q-value via consistency model
Oct 27, 2024



``Distribution shift'' is the main obstacle to the success of offline reinforcement learning. A learning policy may take actions beyond the behavior policy's knowledge, referred to as Out-of-Distribution (OOD) actions. The Q-values for these OOD actions can be easily overestimated. As a result, the learning policy is biased by using incorrect Q-value estimates. One common approach to avoid Q-value overestimation is to make a pessimistic adjustment. Our key idea is to penalize the Q-values of OOD actions associated with high uncertainty. In this work, we propose Q-Distribution Guided Q-Learning (QDQ), which applies a pessimistic adjustment to Q-values in OOD regions based on uncertainty estimation. This uncertainty measure relies on the conditional Q-value distribution, learned through a high-fidelity and efficient consistency model. Additionally, to prevent overly conservative estimates, we introduce an uncertainty-aware optimization objective for updating the Q-value function. The proposed QDQ demonstrates solid theoretical guarantees for the accuracy of Q-value distribution learning and uncertainty measurement, as well as the performance of the learning policy. QDQ consistently shows strong performance on the D4RL benchmark and achieves significant improvements across many tasks.
Diffusion Actor-Critic: Formulating Constrained Policy Iteration as Diffusion Noise Regression for Offline Reinforcement Learning
May 31, 2024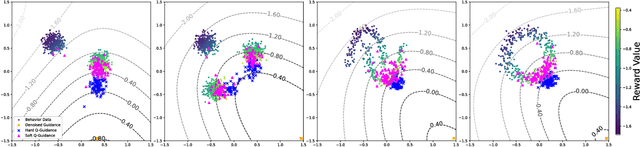
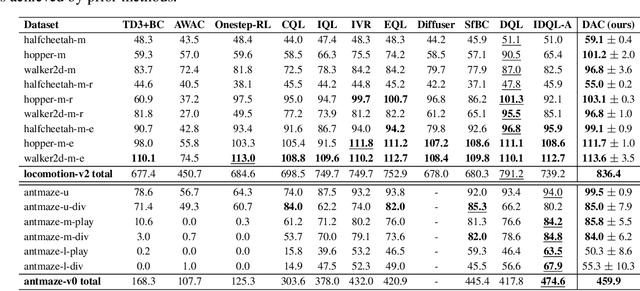

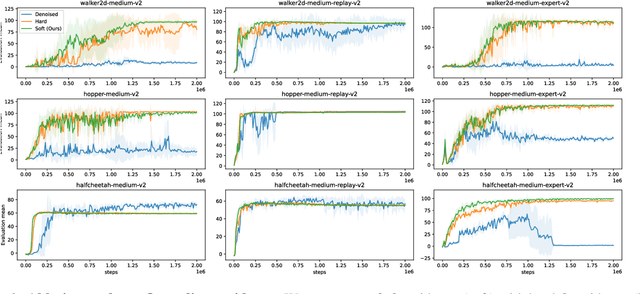
In offline reinforcement learning (RL), it is necessary to manage out-of-distribution actions to prevent overestimation of value functions. Policy-regularized methods address this problem by constraining the target policy to stay close to the behavior policy. Although several approaches suggest representing the behavior policy as an expressive diffusion model to boost performance, it remains unclear how to regularize the target policy given a diffusion-modeled behavior sampler. In this paper, we propose Diffusion Actor-Critic (DAC) that formulates the Kullback-Leibler (KL) constraint policy iteration as a diffusion noise regression problem, enabling direct representation of target policies as diffusion models. Our approach follows the actor-critic learning paradigm that we alternatively train a diffusion-modeled target policy and a critic network. The actor training loss includes a soft Q-guidance term from the Q-gradient. The soft Q-guidance grounds on the theoretical solution of the KL constraint policy iteration, which prevents the learned policy from taking out-of-distribution actions. For critic training, we train a Q-ensemble to stabilize the estimation of Q-gradient. Additionally, DAC employs lower confidence bound (LCB) to address the overestimation and underestimation of value targets due to function approximation error. Our approach is evaluated on the D4RL benchmarks and outperforms the state-of-the-art in almost all environments. Code is available at \href{https://github.com/Fang-Lin93/DAC}{\texttt{github.com/Fang-Lin93/DAC}}.
APAC: Authorized Probability-controlled Actor-Critic For Offline Reinforcement Learning
Jan 28, 2023



Due to the inability to interact with the environment, offline reinforcement learning (RL) methods face the challenge of estimating the Out-of-Distribution (OOD) points. Most existing methods exclude the OOD areas or restrict the value of $Q$ function. However, these methods either are over-conservative or suffer from model uncertainty prediction. In this paper, we propose an authorized probabilistic-control policy learning (APAC) method. The proposed method learns the distribution characteristics of the feasible states/actions by utilizing the flow-GAN model. Specifically, APAC avoids taking action in the low probability density region of behavior policy, while allows exploration in the authorized high probability density region. Theoretical proofs are provided to justify the advantage of APAC. Empirically, APAC outperforms existing alternatives on a variety of simulated tasks, and yields higher expected returns.
Community Detection on Mixture Multi-layer Networks via Regularized Tensor Decomposition
Feb 10, 2020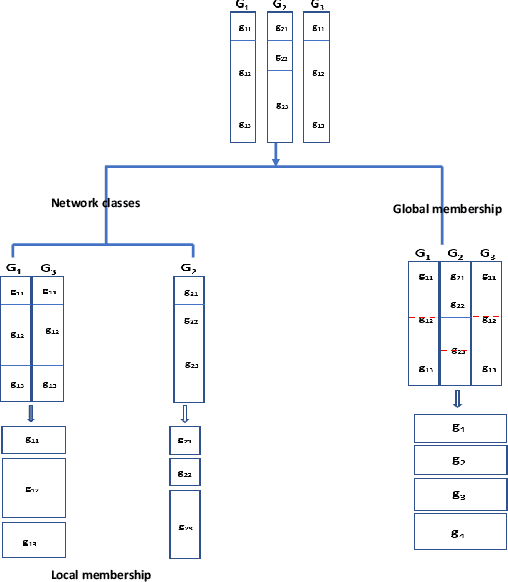

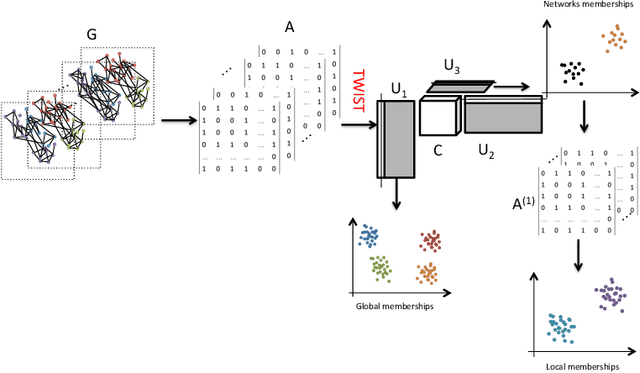

We study the problem of community detection in multi-layer networks, where pairs of nodes can be related in multiple modalities. We introduce a general framework, i.e., mixture multi-layer stochastic block model (MMSBM), which includes many earlier models as special cases. We propose a tensor-based algorithm (TWIST) to reveal both global/local memberships of nodes, and memberships of layers. We show that the TWIST procedure can accurately detect the communities with small misclassification error as the number of nodes and/or the number of layers increases. Numerical studies confirm our theoretical findings. To our best knowledge, this is the first systematic study on the mixture multi-layer networks using tensor decomposition. The method is applied to two real datasets: worldwide trading networks and malaria parasite genes networks, yielding new and interesting findings.
Regularized maximum correntropy machine
Jan 18, 2015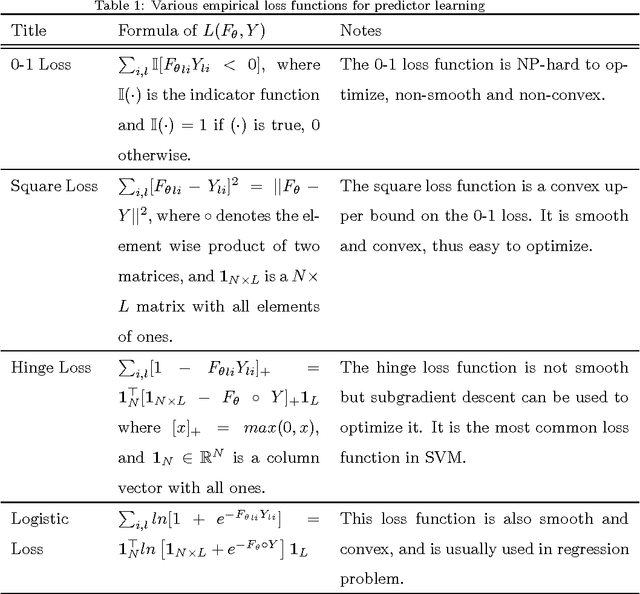
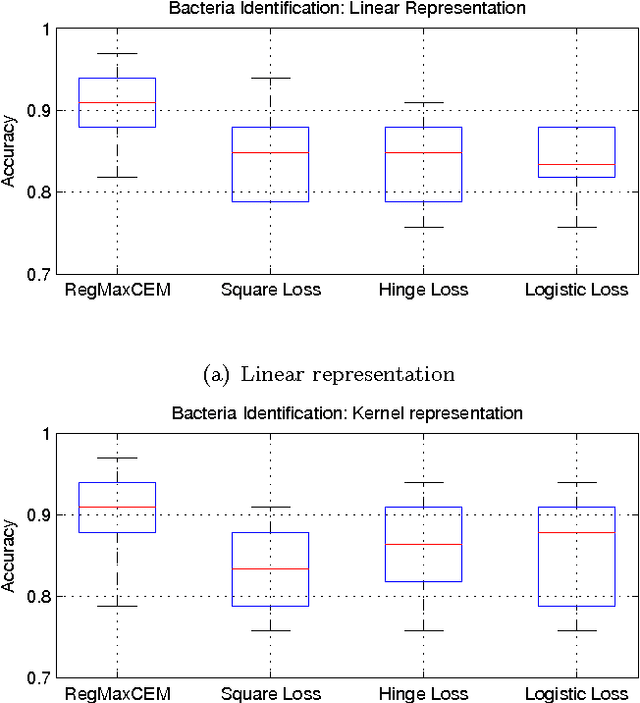
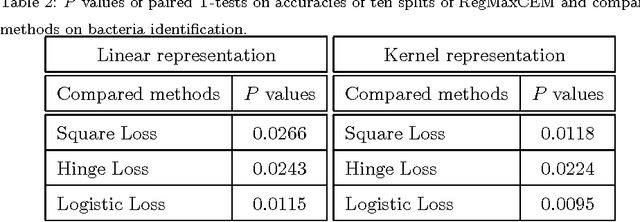
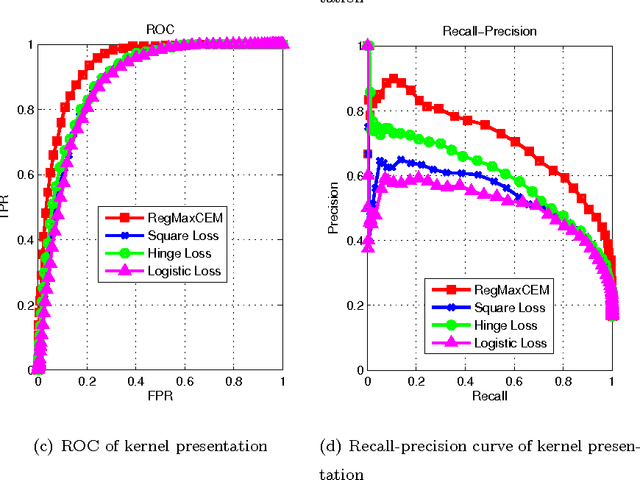
In this paper we investigate the usage of regularized correntropy framework for learning of classifiers from noisy labels. The class label predictors learned by minimizing transitional loss functions are sensitive to the noisy and outlying labels of training samples, because the transitional loss functions are equally applied to all the samples. To solve this problem, we propose to learn the class label predictors by maximizing the correntropy between the predicted labels and the true labels of the training samples, under the regularized Maximum Correntropy Criteria (MCC) framework. Moreover, we regularize the predictor parameter to control the complexity of the predictor. The learning problem is formulated by an objective function considering the parameter regularization and MCC simultaneously. By optimizing the objective function alternately, we develop a novel predictor learning algorithm. The experiments on two chal- lenging pattern classification tasks show that it significantly outperforms the machines with transitional loss functions.