 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Intermediate Representation for LLM-based optimization problem formulation and code generation
Feb 02, 2026Automatically formulating optimization models from natural language descriptions is a growing focus in operations research, yet current LLM-based approaches struggle with the composite constraints and appropriate modeling paradigms required by complex operational rules. To address this, we introduce the Canonical Intermediate Representation (CIR): a schema that LLMs explicitly generate between problem descriptions and optimization models. CIR encodes the semantics of operational rules through constraint archetypes and candidate modeling paradigms, thereby decoupling rule logic from its mathematical instantiation. Upon a newly generated CIR knowledge base, we develop the rule-to-constraint (R2C) framework, a multi-agent pipeline that parses problem texts, synthesizes CIR implementations by retrieving domain knowledge, and instantiates optimization models. To systematically evaluate rule-to-constraint reasoning, we test R2C on our newly constructed benchmark featuring rich operational rules, and benchmarks from prior work. Extensive experiments show that R2C achieves state-of-the-art accuracy on the proposed benchmark (47.2% Accuracy Rate). On established benchmarks from the literature, R2C delivers highly competitive results, approaching the performance of proprietary models (e.g., GPT-5). Moreover, with a reflection mechanism, R2C achieves further gains and sets new best-reported results on some benchmarks.
Adaptive Transfer Clustering: A Unified Framework
Oct 28, 2024
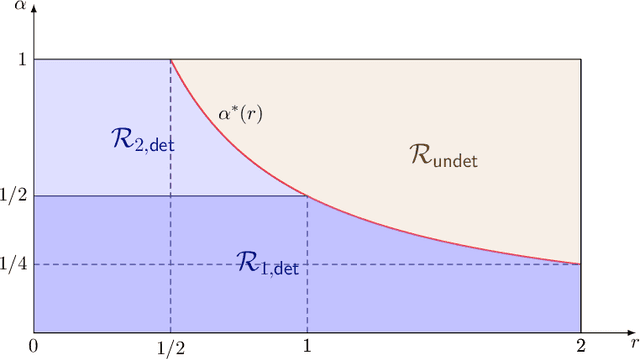
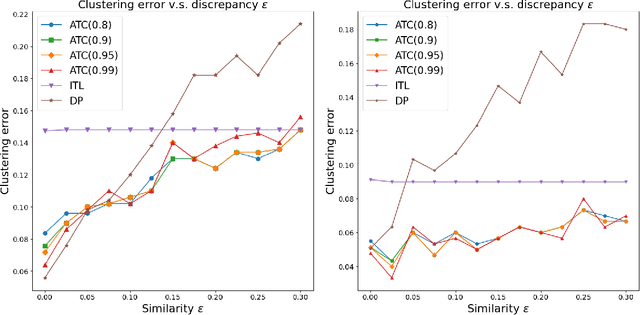
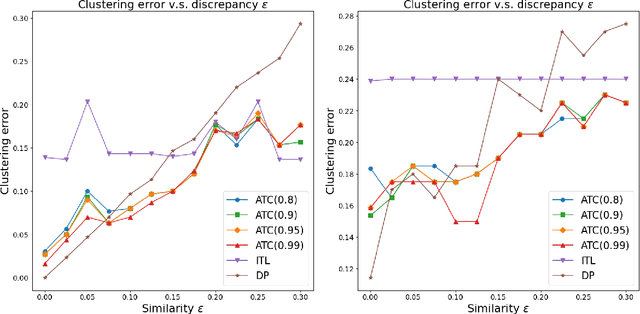
We propose a general transfer learning framework for clustering given a main dataset and an auxiliary one about the same subjects. The two datasets may reflect similar but different latent grouping structures of the subjects. We propose an adaptive transfer clustering (ATC) algorithm that automatically leverages the commonality in the presence of unknown discrepancy, by optimizing an estimated bias-variance decomposition. It applies to a broad class of statistical models including Gaussian mixture models, stochastic block models, and latent class models. A theoretical analysis proves the optimality of ATC under the Gaussian mixture model and explicitly quantifies the benefit of transfer. Extensive simulations and real data experiments confirm our method's effectiveness in various scenarios.
Optimal Clustering of Discrete Mixtures: Binomial, Poisson, Block Models, and Multi-layer Networks
Nov 27, 2023In this paper, we first study the fundamental limit of clustering networks when a multi-layer network is present. Under the mixture multi-layer stochastic block model (MMSBM), we show that the minimax optimal network clustering error rate, which takes an exponential form and is characterized by the Renyi divergence between the edge probability distributions of the component networks. We propose a novel two-stage network clustering method including a tensor-based initialization algorithm involving both node and sample splitting and a refinement procedure by likelihood-based Lloyd algorithm. Network clustering must be accompanied by node community detection. Our proposed algorithm achieves the minimax optimal network clustering error rate and allows extreme network sparsity under MMSBM. Numerical simulations and real data experiments both validate that our method outperforms existing methods. Oftentimes, the edges of networks carry count-type weights. We then extend our methodology and analysis framework to study the minimax optimal clustering error rate for mixture of discrete distributions including Binomial, Poisson, and multi-layer Poisson networks. The minimax optimal clustering error rates in these discrete mixtures all take the same exponential form characterized by the Renyi divergences. These optimal clustering error rates in discrete mixtures can also be achieved by our proposed two-stage clustering algorithm.
rMultiNet: An R Package For Multilayer Networks Analysis
Feb 09, 2023This paper develops an R package rMultiNet to analyze multilayer network data. We provide two general frameworks from recent literature, e.g. mixture multilayer stochastic block model(MMSBM) and mixture multilayer latent space model(MMLSM) to generate the multilayer network. We also provide several methods to reveal the embedding of both nodes and layers followed by further data analysis methods, such as clustering. Three real data examples are processed in the package. The source code of rMultiNet is available at https://github.com/ChenyuzZZ73/rMultiNet.
Optimal Clustering by Lloyd Algorithm for Low-Rank Mixture Model
Jul 11, 2022

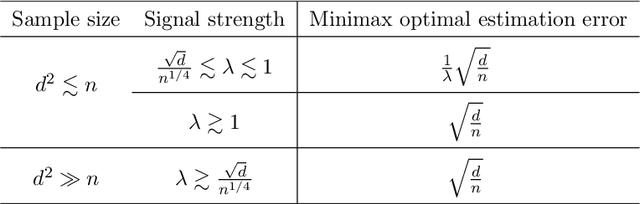
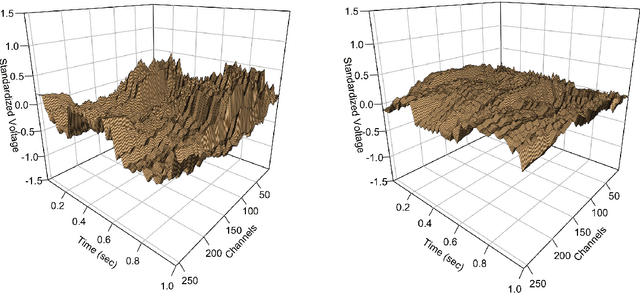
This paper investigates the computational and statistical limits in clustering matrix-valued observations. We propose a low-rank mixture model (LrMM), adapted from the classical Gaussian mixture model (GMM) to treat matrix-valued observations, which assumes low-rankness for population center matrices. A computationally efficient clustering method is designed by integrating Lloyd algorithm and low-rank approximation. Once well-initialized, the algorithm converges fast and achieves an exponential-type clustering error rate that is minimax optimal. Meanwhile, we show that a tensor-based spectral method delivers a good initial clustering. Comparable to GMM, the minimax optimal clustering error rate is decided by the separation strength, i.e, the minimal distance between population center matrices. By exploiting low-rankness, the proposed algorithm is blessed with a weaker requirement on separation strength. Unlike GMM, however, the statistical and computational difficulty of LrMM is characterized by the signal strength, i.e, the smallest non-zero singular values of population center matrices. Evidences are provided showing that no polynomial-time algorithm is consistent if the signal strength is not strong enough, even though the separation strength is strong. The performance of our low-rank Lloyd algorithm is further demonstrated under sub-Gaussian noise. Intriguing differences between estimation and clustering under LrMM are discussed. The merits of low-rank Lloyd algorithm are confirmed by comprehensive simulation experiments. Finally, our method outperforms others in the literature on real-world datasets.
Optimal Estimation and Computational Limit of Low-rank Gaussian Mixtures
Jan 22, 2022



Structural matrix-variate observations routinely arise in diverse fields such as multi-layer network analysis and brain image clustering. While data of this type have been extensively investigated with fruitful outcomes being delivered, the fundamental questions like its statistical optimality and computational limit are largely under-explored. In this paper, we propose a low-rank Gaussian mixture model (LrMM) assuming each matrix-valued observation has a planted low-rank structure. Minimax lower bounds for estimating the underlying low-rank matrix are established allowing a whole range of sample sizes and signal strength. Under a minimal condition on signal strength, referred to as the information-theoretical limit or statistical limit, we prove the minimax optimality of a maximum likelihood estimator which, in general, is computationally infeasible. If the signal is stronger than a certain threshold, called the computational limit, we design a computationally fast estimator based on spectral aggregation and demonstrate its minimax optimality. Moreover, when the signal strength is smaller than the computational limit, we provide evidences based on the low-degree likelihood ratio framework to claim that no polynomial-time algorithm can consistently recover the underlying low-rank matrix. Our results reveal multiple phase transitions in the minimax error rates and the statistical-to-computational gap. Numerical experiments confirm our theoretical findings. We further showcase the merit of our spectral aggregation method on the worldwide food trading dataset.
Latent Space Model for Higher-order Networks and Generalized Tensor Decomposition
Jun 30, 2021

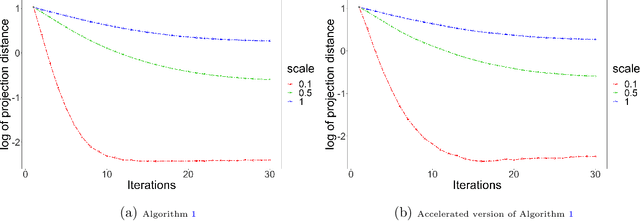

We introduce a unified framework, formulated as general latent space models, to study complex higher-order network interactions among multiple entities. Our framework covers several popular models in recent network analysis literature, including mixture multi-layer latent space model and hypergraph latent space model. We formulate the relationship between the latent positions and the observed data via a generalized multilinear kernel as the link function. While our model enjoys decent generality, its maximum likelihood parameter estimation is also convenient via a generalized tensor decomposition procedure.We propose a novel algorithm using projected gradient descent on Grassmannians. We also develop original theoretical guarantees for our algorithm. First, we show its linear convergence under mild conditions. Second, we establish finite-sample statistical error rates of latent position estimation, determined by the signal strength, degrees of freedom and the smoothness of link function, for both general and specific latent space models. We demonstrate the effectiveness of our method on synthetic data. We also showcase the merit of our method on two real-world datasets that are conventionally described by different specific models in producing meaningful and interpretable parameter estimations and accurate link prediction. We demonstrate the effectiveness of our method on synthetic data. We also showcase the merit of our method on two real-world datasets that are conventionally described by different specific models in producing meaningful and interpretable parameter estimations and accurate link prediction.
Community Detection on Mixture Multi-layer Networks via Regularized Tensor Decomposition
Feb 10, 2020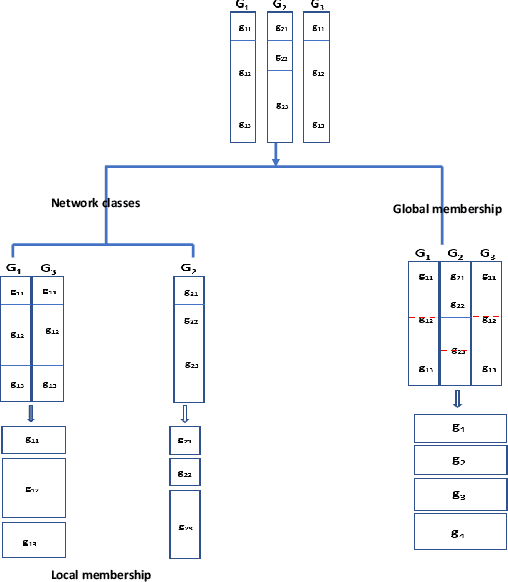

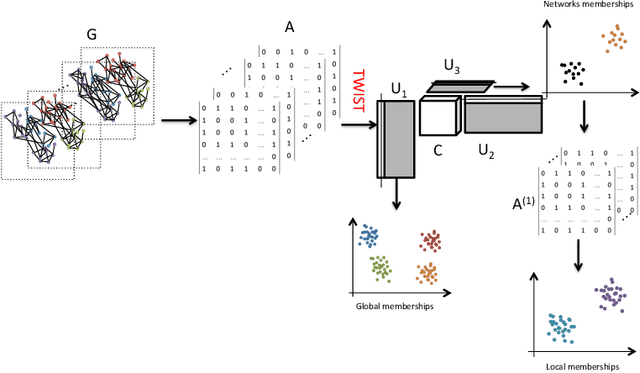

We study the problem of community detection in multi-layer networks, where pairs of nodes can be related in multiple modalities. We introduce a general framework, i.e., mixture multi-layer stochastic block model (MMSBM), which includes many earlier models as special cases. We propose a tensor-based algorithm (TWIST) to reveal both global/local memberships of nodes, and memberships of layers. We show that the TWIST procedure can accurately detect the communities with small misclassification error as the number of nodes and/or the number of layers increases. Numerical studies confirm our theoretical findings. To our best knowledge, this is the first systematic study on the mixture multi-layer networks using tensor decomposition. The method is applied to two real datasets: worldwide trading networks and malaria parasite genes networks, yielding new and interesting findings.