 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiable Bayesian Deep Generative Copulas with Unknown Layer Widths for Data with Arbitrary Marginal Distributions
May 26, 2026Deep generative models offer powerful tools for multivariate data analysis, but their black-box architectures are often unidentified and difficult to interpret. We introduce the Deep Discrete Encoder (DDE) Copula, an identifiable and interpretable generative model for multivariate data with arbitrary marginal distributions. The model places a hierarchical directed network of binary latent variables inside a copula framework, enabling flexible dependence modeling for mixed discrete and continuous data. Estimation is based on rank likelihoods, which decouple marginal modeling from posterior inference on the DDE parameters and avoid specifying the marginal distributions. We establish conditions for identification of the DDE copula parameters, ensuring that layer-specific parameters provide meaningful summaries of multivariate dependence. We also prove quotient-space posterior consistency for continuous margins under the exact rank likelihood and treat the extended rank likelihood for tied or mixed margins as a generalized likelihood, with concentration under an additional contrast condition. For computation, we propose a stochastic expectation-maximization algorithm for \emph{maximum a posteriori} estimation, together with initialization strategies that improve convergence. To learn network dimension adaptively, we extend Bayesian rank-selection priors to infer layer-specific widths. Simulations show strong finite-sample performance, and a personality-survey analysis reveals interpretable hierarchical latent structure in complex multivariate data.
BridgeACT: Bridging Human Demonstrations to Robot Actions via Unified Tool-Target Affordances
Apr 25, 2026Learning robot manipulation from human videos is appealing due to the scale and diversity of human demonstrations, but transferring such demonstrations to executable robot behavior remains challenging. Prior work either relies on robot data for downstream adaptation or learns affordance representations that remain at the perception level and do not directly support real-world execution. We present BridgeACT, an affordance-driven framework that learns robotic manipulation directly from human videos without requiring any robot demonstration data. Our key idea is to model affordance as an embodiment-agnostic intermediate representation that bridges human demonstrations and robot actions. BridgeACT decomposes manipulation into two complementary problems: where to grasp and how to move. To this end, BridgeACT first grounds task-relevant affordance regions in the current scene, and then predicts task-conditioned 3D motion affordances from human demonstrations. The resulting affordances are mapped to robot actions through a grasping module and a lightweight closed-loop motion controller, enabling direct deployment on real robots. In addition, we represent complex manipulation tasks as compositions of affordance operations, which allows a unified treatment of diverse tasks and object-to-object interactions. Experiments on real-world manipulation tasks show that BridgeACT outperforms prior baselines and generalizes to unseen objects, scenes, and viewpoints.
Discrete Causal Representation Learning
Mar 26, 2026Causal representation learning seeks to uncover causal relationships among high-level latent variables from low-level, entangled, and noisy observations. Existing approaches often either rely on deep neural networks, which lack interpretability and formal guarantees, or impose restrictive assumptions like linearity, continuous-only observations, and strong structural priors. These limitations particularly challenge applications with a large number of discrete latent variables and mixed-type observations. To address these challenges, we propose discrete causal representation learning (DCRL), a generative framework that models a directed acyclic graph among discrete latent variables, along with a sparse bipartite graph linking latent and observed layers. This design accommodates continuous, count, and binary responses through flexible measurement models while maintaining interpretability. Under mild conditions, we prove that both the bipartite measurement graph and the latent causal graph are identifiable from the observed data distribution alone. We further propose a three-stage estimate-resample-discovery pipeline: penalized estimation of the generative model parameters, resampling of latent configurations from the fitted model, and score-based causal discovery on the resampled latents. We establish the consistency of this procedure, ensuring reliable recovery of the latent causal structure. Empirical studies on educational assessment and synthetic image data demonstrate that DCRL recovers sparse and interpretable latent causal structures.
Scalable Text-Embedding-informed Cognitive Diagnosis of Large Language Models
Mar 16, 2026Large language models (LLMs) have achieved remarkable performance on diverse benchmarks, yet existing evaluation practices largely rely on coarse summary metrics that obscure underlying reasoning abilities. In this work, we propose novel methodologies to adapt cognitive diagnosis models (CDMs) in psychometrics to LLM evaluation, enabling fine-grained diagnosis via multidimensional discrete capability profiles and interpretable characterizations of LLM strengths and weaknesses. First, to enable CDM-based evaluation at benchmark scale (more than 1000 items), we propose a scalable method that jointly estimates LLM mastery profiles and the item-attribute Q-matrix, addressing key challenges posed by high-dimensional latent attributes (K > 20), large item pools, and the prohibitive computational cost of existing marginal maximum likelihood-based estimation. Second, we incorporate item-level textual information to construct AI-embedding-informed priors for the Q-matrix, stabilizing high-dimensional estimation while reducing reliance on costly human specification. We develop an efficient stochastic-approximation algorithm to jointly estimate LLM mastery profiles and the Q-matrix that balances data fit with text-embedding-informed priors. Simulation studies demonstrate accurate parameter recovery. An application to the MATH Level 5 benchmark illustrates the practical utility of our method for LLM evaluation and uncovers useful insights into LLMs' fine-grained capabilities.
Covariate-assisted Grade of Membership Models via Shared Latent Geometry
Jan 24, 2026The grade of membership model is a flexible latent variable model for analyzing multivariate categorical data through individual-level mixed membership scores. In many modern applications, auxiliary covariates are collected alongside responses and encode information about the same latent structure. Traditional approaches to incorporating such covariates typically rely on fully specified joint likelihoods, which are computationally intensive and sensitive to misspecification. We introduce a covariate-assisted grade of membership model that integrates response and covariate information by exploiting their shared low-rank simplex geometry, rather than modeling their joint distribution. We propose a likelihood-free spectral estimation procedure that combines heterogeneous data sources through a balance parameter controlling their relative contribution. To accommodate high-dimensional and heteroskedastic noise, we employ heteroskedastic principal component analysis before performing simplex-based geometric recovery. Our theoretical analysis establishes weaker identifiability conditions than those required in the covariate-free model, and further derives finite-sample, entrywise error bounds for both mixed membership scores and item parameters. These results demonstrate that auxiliary covariates can provably improve latent structure recovery, yielding faster convergence rates in high-dimensional regimes. Simulation studies and an application to educational assessment data illustrate the computational efficiency, statistical accuracy, and interpretability gains of the proposed method. The code for reproducing these results is open-source and available at \texttt{https://github.com/Toby-X/Covariate-Assisted-GoM}
Identifiability of latent causal graphical models without pure children
May 23, 2025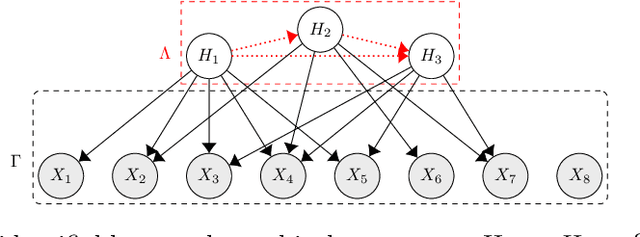

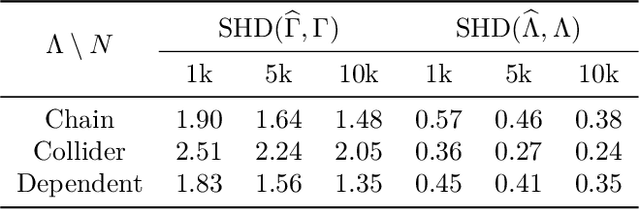

This paper considers a challenging problem of identifying a causal graphical model under the presence of latent variables. While various identifiability conditions have been proposed in the literature, they often require multiple pure children per latent variable or restrictions on the latent causal graph. Furthermore, it is common for all observed variables to exhibit the same modality. Consequently, the existing identifiability conditions are often too stringent for complex real-world data. We consider a general nonparametric measurement model with arbitrary observed variable types and binary latent variables, and propose a double triangular graphical condition that guarantees identifiability of the entire causal graphical model. The proposed condition significantly relaxes the popular pure children condition. We also establish necessary conditions for identifiability and provide valuable insights into fundamental limits of identifiability. Simulation studies verify that latent structures satisfying our conditions can be accurately estimated from data.
Minimax-Optimal Dimension-Reduced Clustering for High-Dimensional Nonspherical Mixtures
Feb 05, 2025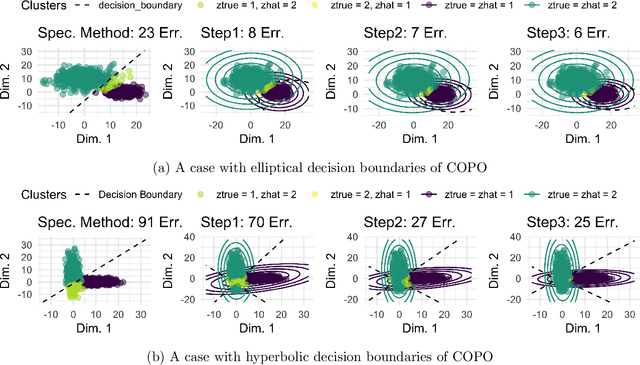
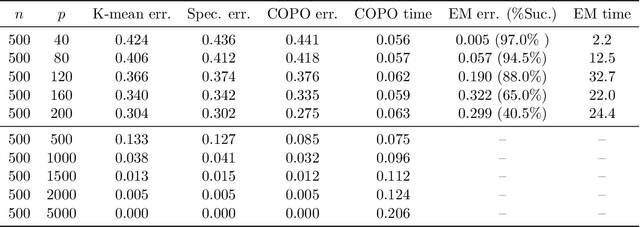
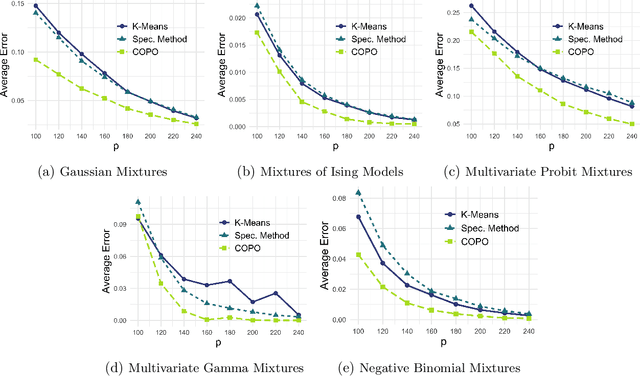
In mixture models, nonspherical (anisotropic) noise within each cluster is widely present in real-world data. We study both the minimax rate and optimal statistical procedure for clustering under high-dimensional nonspherical mixture models. In high-dimensional settings, we first establish the information-theoretic limits for clustering under Gaussian mixtures. The minimax lower bound unveils an intriguing informational dimension-reduction phenomenon: there exists a substantial gap between the minimax rate and the oracle clustering risk, with the former determined solely by the projected centers and projected covariance matrices in a low-dimensional space. Motivated by the lower bound, we propose a novel computationally efficient clustering method: Covariance Projected Spectral Clustering (COPO). Its key step is to project the high-dimensional data onto the low-dimensional space spanned by the cluster centers and then use the projected covariance matrices in this space to enhance clustering. We establish tight algorithmic upper bounds for COPO, both for Gaussian noise with flexible covariance and general noise with local dependence. Our theory indicates the minimax-optimality of COPO in the Gaussian case and highlights its adaptivity to a broad spectrum of dependent noise. Extensive simulation studies under various noise structures and real data analysis demonstrate our method's superior performance.
Minimax-Optimal Covariance Projected Spectral Clustering for High-Dimensional Nonspherical Mixtures
Feb 04, 2025In mixture models, nonspherical (anisotropic) noise within each cluster is widely present in real-world data. We study both the minimax rate and optimal statistical procedure for clustering under high-dimensional nonspherical mixture models. In high-dimensional settings, we first establish the information-theoretic limits for clustering under Gaussian mixtures. The minimax lower bound unveils an intriguing informational dimension-reduction phenomenon: there exists a substantial gap between the minimax rate and the oracle clustering risk, with the former determined solely by the projected centers and projected covariance matrices in a low-dimensional space. Motivated by the lower bound, we propose a novel computationally efficient clustering method: Covariance Projected Spectral Clustering (COPO). Its key step is to project the high-dimensional data onto the low-dimensional space spanned by the cluster centers and then use the projected covariance matrices in this space to enhance clustering. We establish tight algorithmic upper bounds for COPO, both for Gaussian noise with flexible covariance and general noise with local dependence. Our theory indicates the minimax-optimality of COPO in the Gaussian case and highlights its adaptivity to a broad spectrum of dependent noise. Extensive simulation studies under various noise structures and real data analysis demonstrate our method's superior performance.
Unfolding Tensors to Identify the Graph in Discrete Latent Bipartite Graphical Models
Jan 18, 2025We use a tensor unfolding technique to prove a new identifiability result for discrete bipartite graphical models, which have a bipartite graph between an observed and a latent layer. This model family includes popular models such as Noisy-Or Bayesian networks for medical diagnosis and Restricted Boltzmann Machines in machine learning. These models are also building blocks for deep generative models. Our result on identifying the graph structure enjoys the following nice properties. First, our identifiability proof is constructive, in which we innovatively unfold the population tensor under the model into matrices and inspect the rank properties of the resulting matrices to uncover the graph. This proof itself gives a population-level structure learning algorithm that outputs both the number of latent variables and the bipartite graph. Second, we allow various forms of nonlinear dependence among the variables, unlike many continuous latent variable graphical models that rely on linearity to show identifiability. Third, our identifiability condition is interpretable, only requiring each latent variable to connect to at least two "pure" observed variables in the bipartite graph. The new result not only brings novel advances in algebraic statistics, but also has useful implications for these models' trustworthy applications in scientific disciplines and interpretable machine learning.
Deep Discrete Encoders: Identifiable Deep Generative Models for Rich Data with Discrete Latent Layers
Jan 02, 2025



In the era of generative AI, deep generative models (DGMs) with latent representations have gained tremendous popularity. Despite their impressive empirical performance, the statistical properties of these models remain underexplored. DGMs are often overparametrized, non-identifiable, and uninterpretable black boxes, raising serious concerns when deploying them in high-stakes applications. Motivated by this, we propose an interpretable deep generative modeling framework for rich data types with discrete latent layers, called Deep Discrete Encoders (DDEs). A DDE is a directed graphical model with multiple binary latent layers. Theoretically, we propose transparent identifiability conditions for DDEs, which imply progressively smaller sizes of the latent layers as they go deeper. Identifiability ensures consistent parameter estimation and inspires an interpretable design of the deep architecture. Computationally, we propose a scalable estimation pipeline of a layerwise nonlinear spectral initialization followed by a penalized stochastic approximation EM algorithm. This procedure can efficiently estimate models with exponentially many latent components. Extensive simulation studies validate our theoretical results and demonstrate the proposed algorithms' excellent performance. We apply DDEs to three diverse real datasets for hierarchical topic modeling, image representation learning, response time modeling in educational testing, and obtain interpretable findings.