 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax-Optimal Dimension-Reduced Clustering for High-Dimensional Nonspherical Mixtures
Feb 05, 2025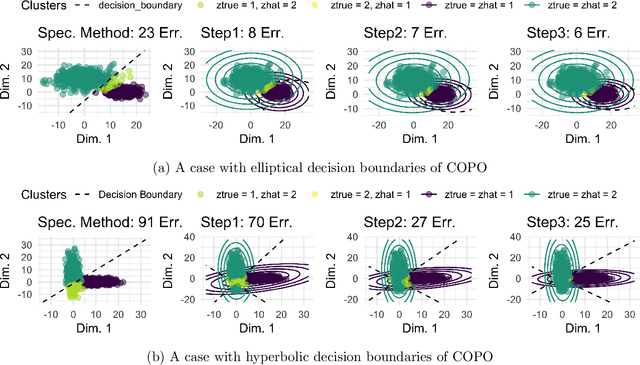
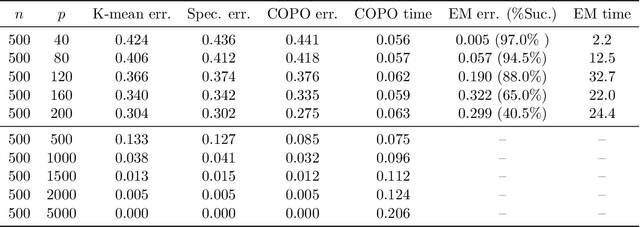
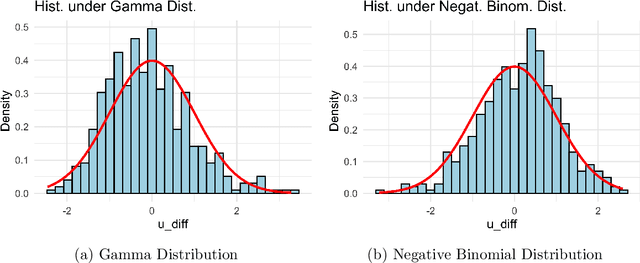
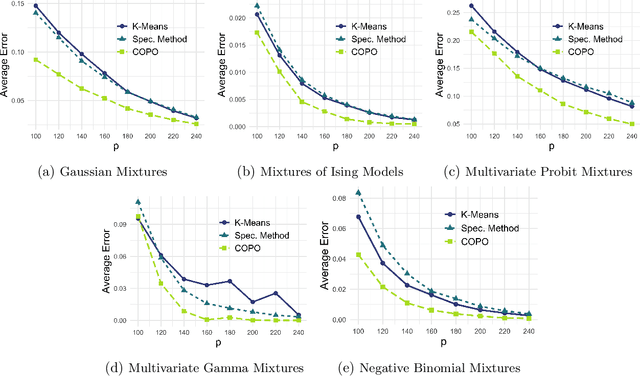
In mixture models, nonspherical (anisotropic) noise within each cluster is widely present in real-world data. We study both the minimax rate and optimal statistical procedure for clustering under high-dimensional nonspherical mixture models. In high-dimensional settings, we first establish the information-theoretic limits for clustering under Gaussian mixtures. The minimax lower bound unveils an intriguing informational dimension-reduction phenomenon: there exists a substantial gap between the minimax rate and the oracle clustering risk, with the former determined solely by the projected centers and projected covariance matrices in a low-dimensional space. Motivated by the lower bound, we propose a novel computationally efficient clustering method: Covariance Projected Spectral Clustering (COPO). Its key step is to project the high-dimensional data onto the low-dimensional space spanned by the cluster centers and then use the projected covariance matrices in this space to enhance clustering. We establish tight algorithmic upper bounds for COPO, both for Gaussian noise with flexible covariance and general noise with local dependence. Our theory indicates the minimax-optimality of COPO in the Gaussian case and highlights its adaptivity to a broad spectrum of dependent noise. Extensive simulation studies under various noise structures and real data analysis demonstrate our method's superior performance.
Minimax-Optimal Covariance Projected Spectral Clustering for High-Dimensional Nonspherical Mixtures
Feb 04, 2025In mixture models, nonspherical (anisotropic) noise within each cluster is widely present in real-world data. We study both the minimax rate and optimal statistical procedure for clustering under high-dimensional nonspherical mixture models. In high-dimensional settings, we first establish the information-theoretic limits for clustering under Gaussian mixtures. The minimax lower bound unveils an intriguing informational dimension-reduction phenomenon: there exists a substantial gap between the minimax rate and the oracle clustering risk, with the former determined solely by the projected centers and projected covariance matrices in a low-dimensional space. Motivated by the lower bound, we propose a novel computationally efficient clustering method: Covariance Projected Spectral Clustering (COPO). Its key step is to project the high-dimensional data onto the low-dimensional space spanned by the cluster centers and then use the projected covariance matrices in this space to enhance clustering. We establish tight algorithmic upper bounds for COPO, both for Gaussian noise with flexible covariance and general noise with local dependence. Our theory indicates the minimax-optimality of COPO in the Gaussian case and highlights its adaptivity to a broad spectrum of dependent noise. Extensive simulation studies under various noise structures and real data analysis demonstrate our method's superior performance.
Generalized Grade-of-Membership Estimation for High-dimensional Locally Dependent Data
Dec 27, 2024This work focuses on the mixed membership models for multivariate categorical data widely used for analyzing survey responses and population genetics data. These grade of membership (GoM) models offer rich modeling power but present significant estimation challenges for high-dimensional polytomous data. Popular existing approaches, such as Bayesian MCMC inference, are not scalable and lack theoretical guarantees in high-dimensional settings. To address this, we first observe that data from this model can be reformulated as a three-way (quasi-)tensor, with many subjects responding to many items with varying numbers of categories. We introduce a novel and simple approach that flattens the three-way quasi-tensor into a "fat" matrix, and then perform a singular value decomposition of it to estimate parameters by exploiting the singular subspace geometry. Our fast spectral method can accommodate a broad range of data distributions with arbitrarily locally dependent noise, which we formalize as the generalized-GoM models. We establish finite-sample entrywise error bounds for the generalized-GoM model parameters. This is supported by a new sharp two-to-infinity singular subspace perturbation theory for locally dependent and flexibly distributed noise, a contribution of independent interest. Simulations and applications to data in political surveys, population genetics, and single-cell sequencing demonstrate our method's superior performance.