 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLCIFAR: CIFAR-Derived Benchmark Datasets with Human Annotated Complementary Labels
Paper and Code
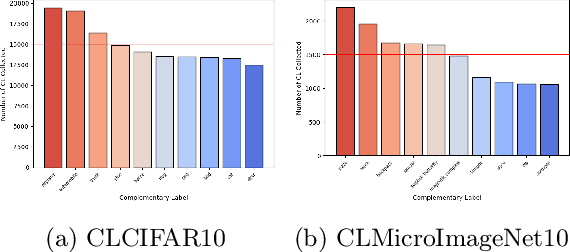
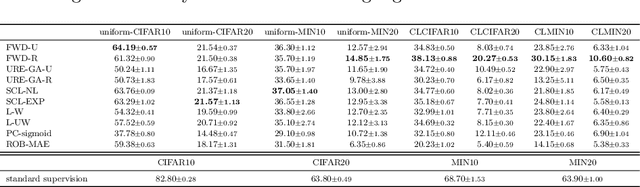
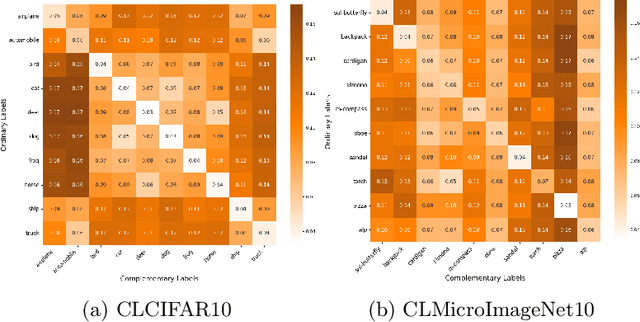
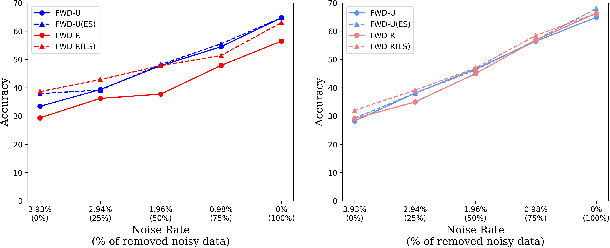
As a weakly-supervised learning paradigm, complementary label learning (CLL) aims to learn a multi-class classifier from only complementary labels, classes to which an instance does not belong. Despite various studies have addressed how to learn from CLL, those methods typically rely on some distributional assumptions on the complementary labels, and are benchmarked only on some synthetic datasets. It remains unclear how the noise or bias arising from the human annotation process would affect those CLL algorithms. To fill the gap, we design a protocol to collect complementary labels annotated by human. Two datasets, CLCIFAR10 and CLCIFAR20, based on CIFAR10 and CIFAR100, respectively, are collected. We analyzed the empirical transition matrices of the collected datasets, and observed that they are noisy and biased. We then performed extensive benchmark experiments on the collected datasets with various CLL algorithms to validate whether the existing algorithms can learn from the real-world complementary datasets. The dataset can be accessed with the following link: https://github.com/ntucllab/complementary_cifar.