 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduction from Complementary-Label Learning to Probability Estimates
Paper and Code
Sep 20, 2022
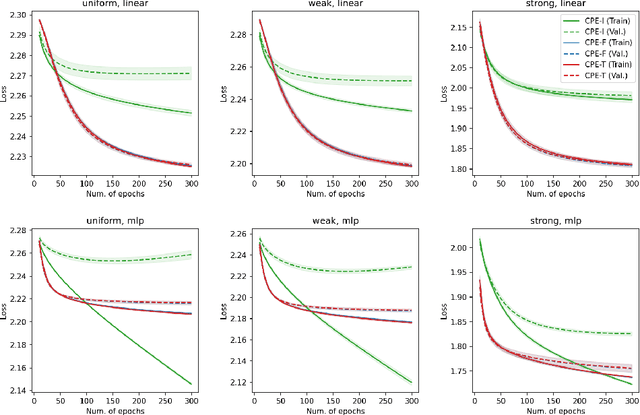

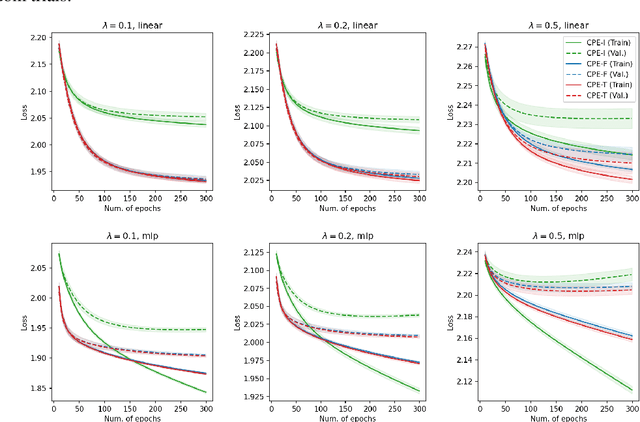
Complementary-Label Learning (CLL) is a weakly-supervised learning problem that aims to learn a multi-class classifier from only complementary labels, which indicate a class to which an instance does not belong. Existing approaches mainly adopt the paradigm of reduction to ordinary classification, which applies specific transformations and surrogate losses to connect CLL back to ordinary classification. Those approaches, however, face several limitations, such as the tendency to overfit or be hooked on deep models. In this paper, we sidestep those limitations with a novel perspective--reduction to probability estimates of complementary classes. We prove that accurate probability estimates of complementary labels lead to good classifiers through a simple decoding step. The proof establishes a reduction framework from CLL to probability estimates. The framework offers explanations of several key CLL approaches as its special cases and allows us to design an improved algorithm that is more robust in noisy environments. The framework also suggests a validation procedure based on the quality of probability estimates, leading to an alternative way to validate models with only complementary labels. The flexible framework opens a wide range of unexplored opportunities in using deep and non-deep models for probability estimates to solve the CLL problem. Empirical experiments further verified the framework's efficacy and robustness in various settings.