 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgelibcll: an Extendable Python Toolkit for Complementary-Label Learning
Nov 19, 2024
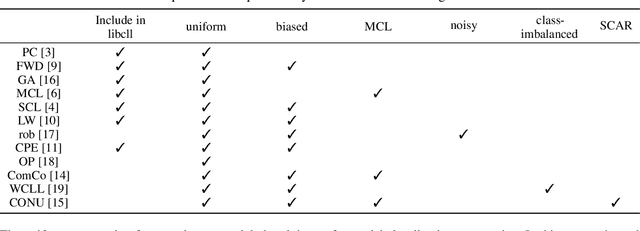


Complementary-label learning (CLL) is a weakly supervised learning paradigm for multiclass classification, where only complementary labels -- indicating classes an instance does not belong to -- are provided to the learning algorithm. Despite CLL's increasing popularity, previous studies highlight two main challenges: (1) inconsistent results arising from varied assumptions on complementary label generation, and (2) high barriers to entry due to the lack of a standardized evaluation platform across datasets and algorithms. To address these challenges, we introduce \texttt{libcll}, an extensible Python toolkit for CLL research. \texttt{libcll} provides a universal interface that supports a wide range of generation assumptions, both synthetic and real-world datasets, and key CLL algorithms. The toolkit is designed to mitigate inconsistencies and streamline the research process, with easy installation, comprehensive usage guides, and quickstart tutorials that facilitate efficient adoption and implementation of CLL techniques. Extensive ablation studies conducted with \texttt{libcll} demonstrate its utility in generating valuable insights to advance future CLL research.
From SMOTE to Mixup for Deep Imbalanced Classification
Aug 29, 2023Given imbalanced data, it is hard to train a good classifier using deep learning because of the poor generalization of minority classes. Traditionally, the well-known synthetic minority oversampling technique (SMOTE) for data augmentation, a data mining approach for imbalanced learning, has been used to improve this generalization. However, it is unclear whether SMOTE also benefits deep learning. In this work, we study why the original SMOTE is insufficient for deep learning, and enhance SMOTE using soft labels. Connecting the resulting soft SMOTE with Mixup, a modern data augmentation technique, leads to a unified framework that puts traditional and modern data augmentation techniques under the same umbrella. A careful study within this framework shows that Mixup improves generalization by implicitly achieving uneven margins between majority and minority classes. We then propose a novel margin-aware Mixup technique that more explicitly achieves uneven margins. Extensive experimental results demonstrate that our proposed technique yields state-of-the-art performance on deep imbalanced classification while achieving superior performance on extremely imbalanced data. The code is open-sourced in our developed package https://github.com/ntucllab/imbalanced-DL to foster future research in this direction.