 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Source-Private Bias in Extreme Universal Domain Adaptation
Oct 15, 2024Universal Domain Adaptation (UniDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain without assuming how much the label-sets of the two domains intersect. The goal of UniDA is to achieve robust performance on the target domain across different intersection levels. However, existing literature has not sufficiently explored performance under extreme intersection levels. Our experiments reveal that state-of-the-art methods struggle when the source domain has significantly more non-overlapping classes than overlapping ones, a setting we refer to as Extreme UniDA. In this paper, we demonstrate that classical partial domain alignment, which focuses on aligning only overlapping-class data between domains, is limited in mitigating the bias of feature extractors toward source-private classes in extreme UniDA scenarios. We argue that feature extractors trained with source supervised loss distort the intrinsic structure of the target data due to the inherent differences between source-private classes and the target data. To mitigate this bias, we propose using self-supervised learning to preserve the structure of the target data. Our approach can be easily integrated into existing frameworks. We apply the proposed approach to two distinct training paradigms-adversarial-based and optimal-transport-based-and show consistent improvements across various intersection levels, with significant gains in extreme UniDA settings.
Defending Text-to-image Diffusion Models: Surprising Efficacy of Textual Perturbations Against Backdoor Attacks
Aug 28, 2024Text-to-image diffusion models have been widely adopted in real-world applications due to their ability to generate realistic images from textual descriptions. However, recent studies have shown that these methods are vulnerable to backdoor attacks. Despite the significant threat posed by backdoor attacks on text-to-image diffusion models, countermeasures remain under-explored. In this paper, we address this research gap by demonstrating that state-of-the-art backdoor attacks against text-to-image diffusion models can be effectively mitigated by a surprisingly simple defense strategy - textual perturbation. Experiments show that textual perturbations are effective in defending against state-of-the-art backdoor attacks with minimal sacrifice to generation quality. We analyze the efficacy of textual perturbation from two angles: text embedding space and cross-attention maps. They further explain how backdoor attacks have compromised text-to-image diffusion models, providing insights for studying future attack and defense strategies. Our code is available at https://github.com/oscarchew/t2i-backdoor-defense.
Re-Benchmarking Pool-Based Active Learning for Binary Classification
Jun 15, 2023
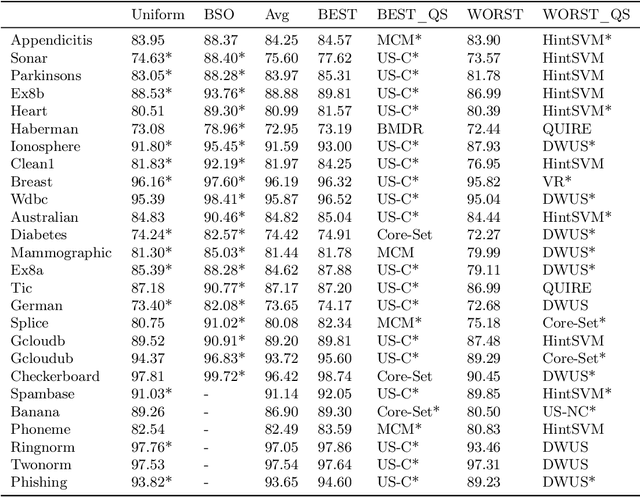
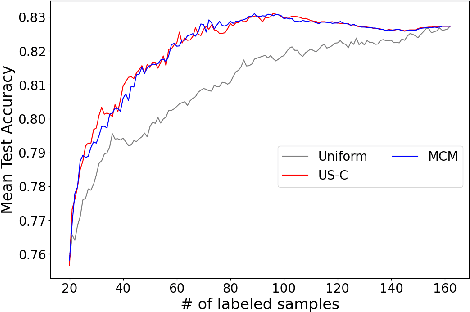

Active learning is a paradigm that significantly enhances the performance of machine learning models when acquiring labeled data is expensive. While several benchmarks exist for evaluating active learning strategies, their findings exhibit some misalignment. This discrepancy motivates us to develop a transparent and reproducible benchmark for the community. Our efforts result in an open-sourced implementation (https://github.com/ariapoy/active-learning-benchmark) that is reliable and extensible for future research. By conducting thorough re-benchmarking experiments, we have not only rectified misconfigurations in existing benchmark but also shed light on the under-explored issue of model compatibility, which directly causes the observed discrepancy. Resolving the discrepancy reassures that the uncertainty sampling strategy of active learning remains an effective and preferred choice for most datasets. Our experience highlights the importance of dedicating research efforts towards re-benchmarking existing benchmarks to produce more credible results and gain deeper insights.