 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs CLIP Cross-Eyed? Revealing and Mitigating Center Bias in the CLIP Family
Apr 07, 2026Recent research has shown that contrastive vision-language models such as CLIP often lack fine-grained understanding of visual content. While a growing body of work has sought to address this limitation, we identify a distinct failure mode in the CLIP family, which we term center bias, that persists even in recent model variants. Specifically, CLIP tends to disproportionately focus on the central region of an image, overlooking important objects located near the boundaries. This limitation is fundamental as failure to recognize relevant objects makes it difficult to perform any sophisticated tasks that depend on those objects. To understand the underlying causes of the limitation, we conduct analyses from both representation and attention perspectives. Using interpretability methods, i.e., embedding decomposition and attention map analysis, we find that relevant concepts especially those associated with off-center objects vanish from the model's embedding in the final representation due to information loss during the aggregation of visual embeddings, particularly the reliance on pooling mechanisms. Finally, we show that this bias can be alleviated with training-free strategies such as visual prompting and attention redistribution by redirecting models' attention to off-center regions.
The Role of Exploration Modules in Small Language Models for Knowledge Graph Question Answering
Sep 09, 2025Integrating knowledge graphs (KGs) into the reasoning processes of large language models (LLMs) has emerged as a promising approach to mitigate hallucination. However, existing work in this area often relies on proprietary or extremely large models, limiting accessibility and scalability. In this study, we investigate the capabilities of existing integration methods for small language models (SLMs) in KG-based question answering and observe that their performance is often constrained by their limited ability to traverse and reason over knowledge graphs. To address this limitation, we propose leveraging simple and efficient exploration modules to handle knowledge graph traversal in place of the language model itself. Experiment results demonstrate that these lightweight modules effectively improve the performance of small language models on knowledge graph question answering tasks. Source code: https://github.com/yijie-cheng/SLM-ToG/.
Defending Text-to-image Diffusion Models: Surprising Efficacy of Textual Perturbations Against Backdoor Attacks
Aug 28, 2024Text-to-image diffusion models have been widely adopted in real-world applications due to their ability to generate realistic images from textual descriptions. However, recent studies have shown that these methods are vulnerable to backdoor attacks. Despite the significant threat posed by backdoor attacks on text-to-image diffusion models, countermeasures remain under-explored. In this paper, we address this research gap by demonstrating that state-of-the-art backdoor attacks against text-to-image diffusion models can be effectively mitigated by a surprisingly simple defense strategy - textual perturbation. Experiments show that textual perturbations are effective in defending against state-of-the-art backdoor attacks with minimal sacrifice to generation quality. We analyze the efficacy of textual perturbation from two angles: text embedding space and cross-attention maps. They further explain how backdoor attacks have compromised text-to-image diffusion models, providing insights for studying future attack and defense strategies. Our code is available at https://github.com/oscarchew/t2i-backdoor-defense.
Understanding and Mitigating Spurious Correlations in Text Classification
May 23, 2023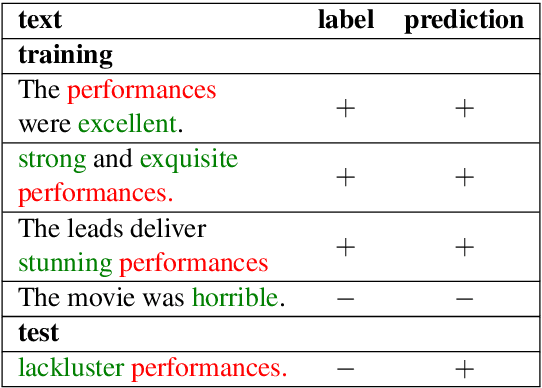
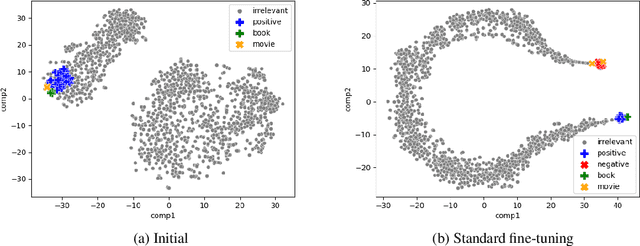

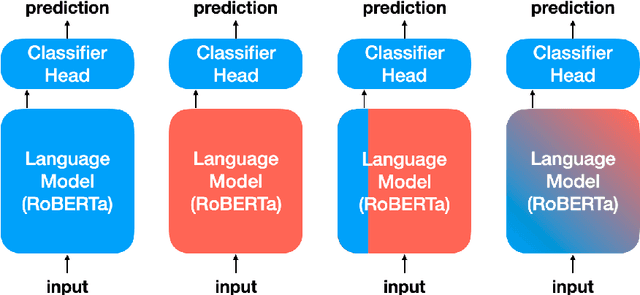
Recent work has shown that deep learning models are prone to exploit spurious correlations that are present in the training set, yet may not hold true in general. A sentiment classifier may erroneously learn that the token spielberg is always tied to positive movie reviews. Relying on spurious correlations may lead to significant degradation in generalizability and should be avoided. In this paper, we propose a neighborhood analysis framework to explain how exactly language models exploit spurious correlations. Driven by the analysis, we propose a family of regularization methods, NFL (do Not Forget your Language) to prevent the situation. Experiments on two text classification tasks show that NFL brings a significant improvement over standard fine-tuning in terms of robustness without sacrificing in-distribution accuracy.