 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Mitigating Spurious Correlations in Text Classification
Paper and Code
May 23, 2023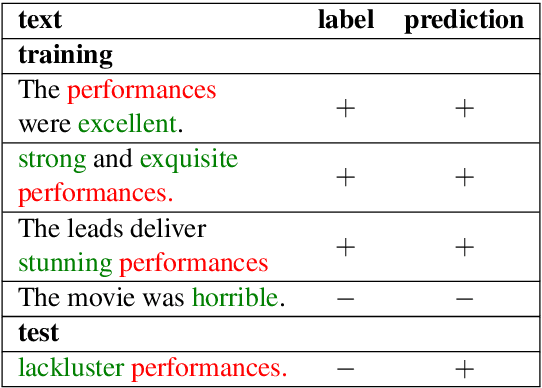
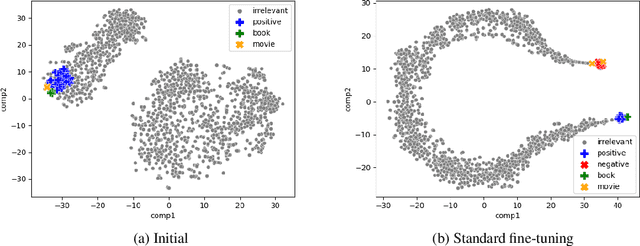

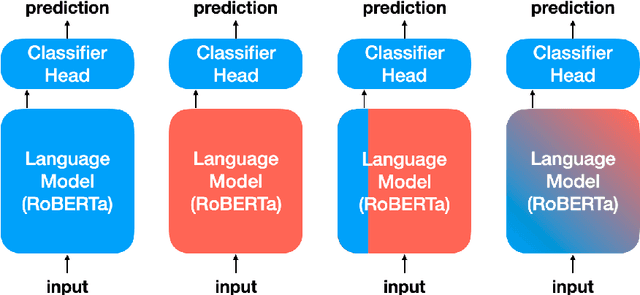
Recent work has shown that deep learning models are prone to exploit spurious correlations that are present in the training set, yet may not hold true in general. A sentiment classifier may erroneously learn that the token spielberg is always tied to positive movie reviews. Relying on spurious correlations may lead to significant degradation in generalizability and should be avoided. In this paper, we propose a neighborhood analysis framework to explain how exactly language models exploit spurious correlations. Driven by the analysis, we propose a family of regularization methods, NFL (do Not Forget your Language) to prevent the situation. Experiments on two text classification tasks show that NFL brings a significant improvement over standard fine-tuning in terms of robustness without sacrificing in-distribution accuracy.