 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Perceptual Quality by Phone-Fortified Perceptual Loss for Speech Enhancement
Paper and Code
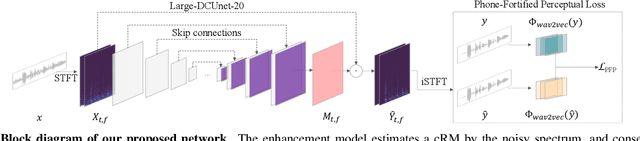
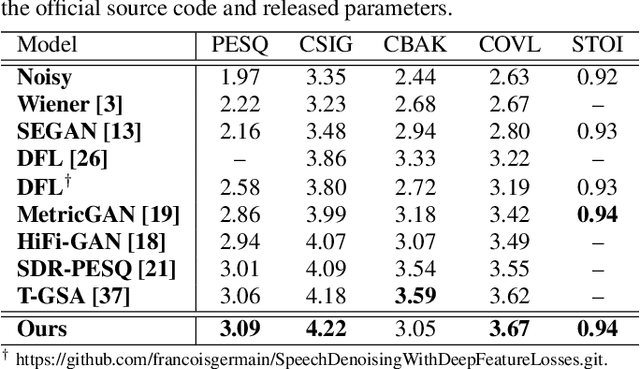
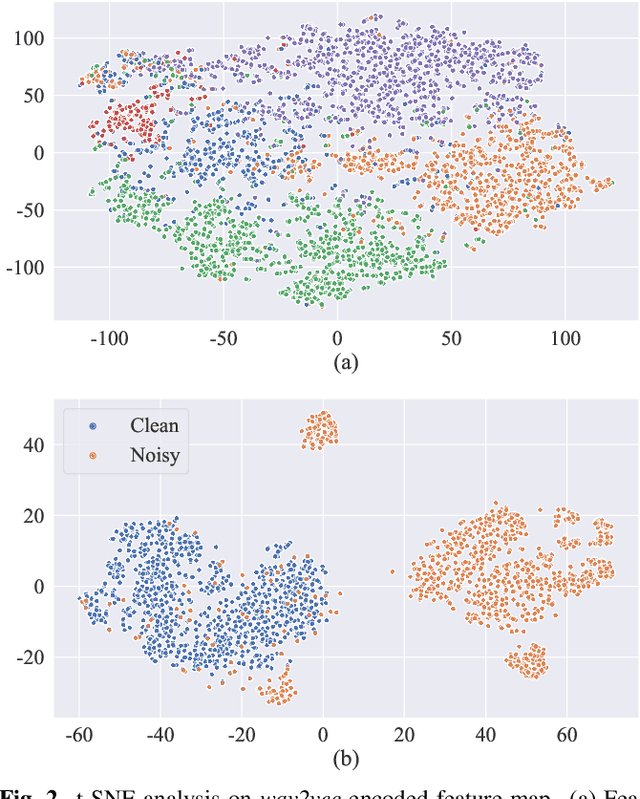
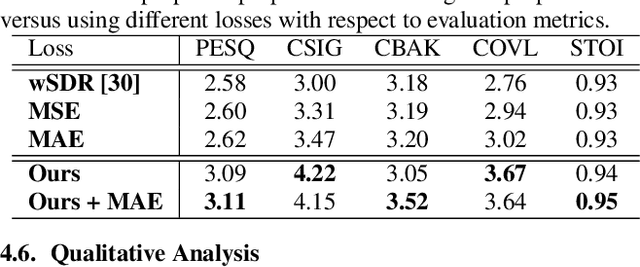
Speech enhancement (SE) aims to improve speech quality and intelligibility, which are both related to a smooth transition in speech segments that may carry linguistic information, e.g. phones and syllables. In this study, we took phonetic characteristics into account in the SE training process. Hence, we designed a phone-fortified perceptual (PFP) loss, and the training of our SE model was guided by PFP loss. In PFP loss, phonetic characteristics are extracted by wav2vec, an unsupervised learning model based on the contrastive predictive coding (CPC) criterion. Different from previous deep-feature-based approaches, the proposed approach explicitly uses the phonetic information in the deep feature extraction process to guide the SE model training. To test the proposed approach, we first confirmed that the wav2vec representations carried clear phonetic information using a t-distributed stochastic neighbor embedding (t-SNE) analysis. Next, we observed that the proposed PFP loss was more strongly correlated with the perceptual evaluation metrics than point-wise and signal-level losses, thus achieving higher scores for standardized quality and intelligibility evaluation metrics in the Voice Bank-DEMAND dataset.