 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Remixer: Learning to Remix Music with Interactive Control
Paper and Code
Jul 28, 2021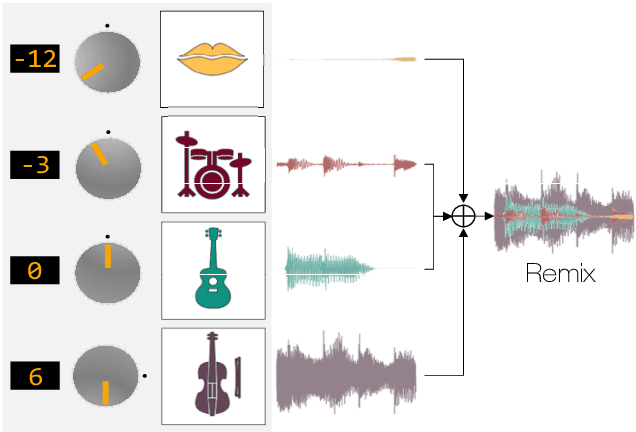
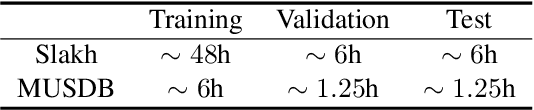
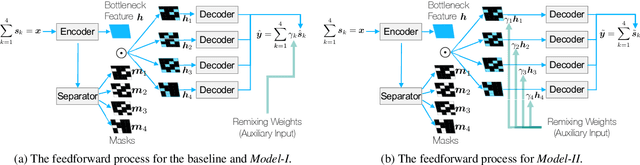
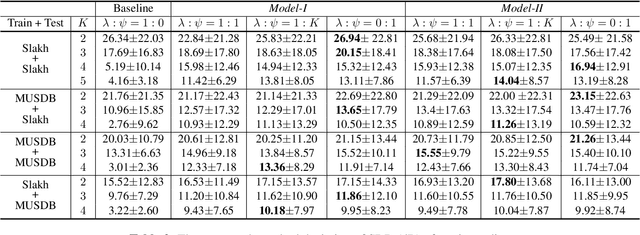
The task of manipulating the level and/or effects of individual instruments to recompose a mixture of recording, or remixing, is common across a variety of applications such as music production, audio-visual post-production, podcasts, and more. This process, however, traditionally requires access to individual source recordings, restricting the creative process. To work around this, source separation algorithms can separate a mixture into its respective components. Then, a user can adjust their levels and mix them back together. This two-step approach, however, still suffers from audible artifacts and motivates further work. In this work, we seek to learn to remix music directly. To do this, we propose two neural remixing architectures that extend Conv-TasNet to either remix via a) source estimates directly or b) their latent representations. Both methods leverage a remixing data augmentation scheme as well as a mixture reconstruction loss to achieve an end-to-end separation and remixing process. We evaluate our methods using the Slakh and MUSDB datasets and report both source separation performance and the remixing quality. Our results suggest learning-to-remix significantly outperforms a strong separation baseline, is particularly useful for small changes, and can provide interactive user-controls.