 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks
Paper and Code
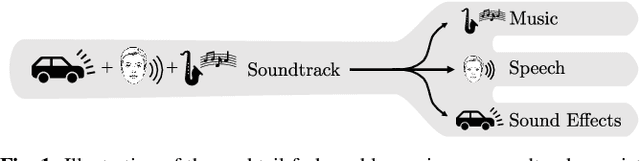


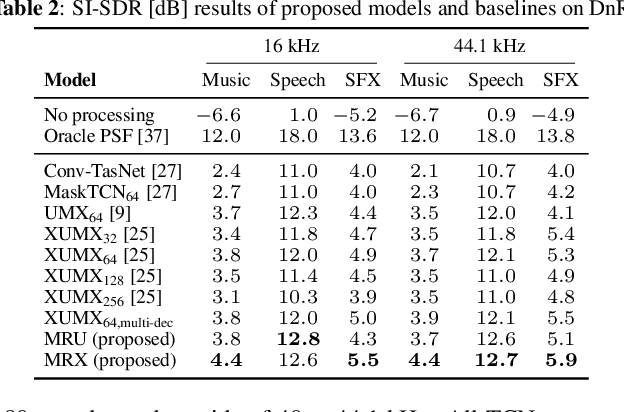
The cocktail party problem aims at isolating any source of interest within a complex acoustic scene, and has long inspired audio source separation research. Recent efforts have mainly focused on separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. However, separating an audio mixture (e.g., movie soundtrack) into the three broad categories of speech, music, and sound effects (here understood to include ambient noise and natural sound events) has been left largely unexplored, despite a wide range of potential applications. This paper formalizes this task as the cocktail fork problem, and presents the Divide and Remaster (DnR) dataset to foster research on this topic. DnR is built from three well-established audio datasets (LibriVox, FMA, FSD50k), taking care to reproduce conditions similar to professionally produced content in terms of source overlap and relative loudness, and made available at CD quality. We benchmark standard source separation algorithms on DnR, and further introduce a new mixed-STFT-resolution model to better address the variety of acoustic characteristics of the three source types. Our best model produces SI-SDR improvements over the mixture of 11.3 dB for music, 11.8 dB for speech, and 10.9 dB for sound effects.