 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVDD 2024: The Inaugural Singing Voice Deepfake Detection Challenge
Paper and Code
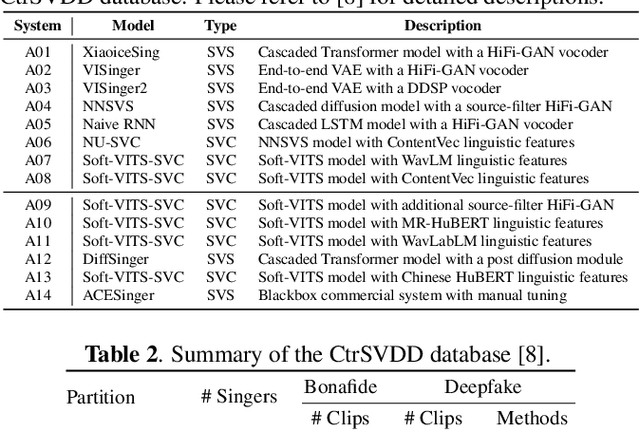
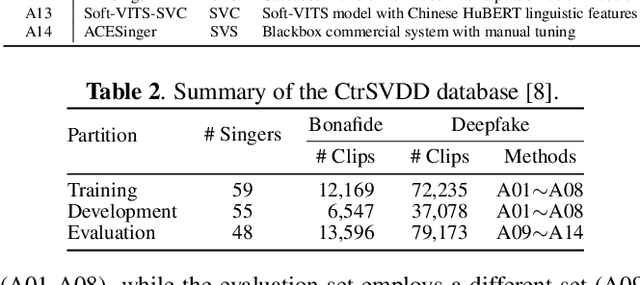
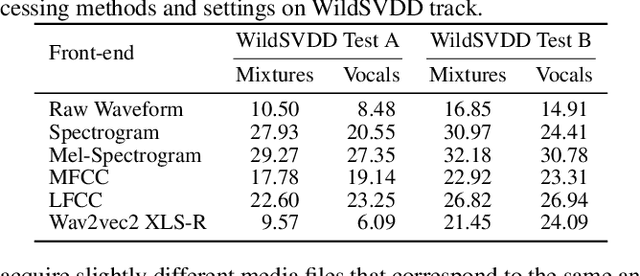
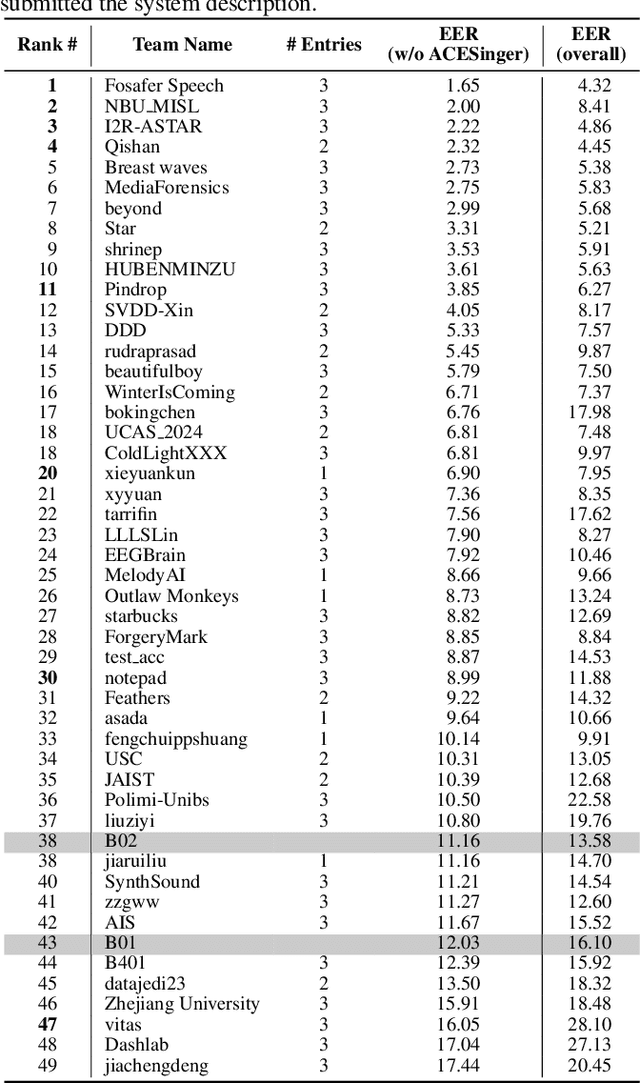
With the advancements in singing voice generation and the growing presence of AI singers on media platforms, the inaugural Singing Voice Deepfake Detection (SVDD) Challenge aims to advance research in identifying AI-generated singing voices from authentic singers. This challenge features two tracks: a controlled setting track (CtrSVDD) and an in-the-wild scenario track (WildSVDD). The CtrSVDD track utilizes publicly available singing vocal data to generate deepfakes using state-of-the-art singing voice synthesis and conversion systems. Meanwhile, the WildSVDD track expands upon the existing SingFake dataset, which includes data sourced from popular user-generated content websites. For the CtrSVDD track, we received submissions from 47 teams, with 37 surpassing our baselines and the top team achieving a 1.65% equal error rate. For the WildSVDD track, we benchmarked the baselines. This paper reviews these results, discusses key findings, and outlines future directions for SVDD research.