 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Simulation-Based Inference in Generalized Bayes via Neural Posterior Estimation
Jan 29, 2026Generalized Bayesian Inference (GBI) tempers a loss with a temperature $β>0$ to mitigate overconfidence and improve robustness under model misspecification, but existing GBI methods typically rely on costly MCMC or SDE-based samplers and must be re-run for each new dataset and each $β$ value. We give the first fully amortized variational approximation to the tempered posterior family $p_β(θ\mid x) \propto π(θ)\,p(x \mid θ)^β$ by training a single $(x,β)$-conditioned neural posterior estimator $q_φ(θ\mid x,β)$ that enables sampling in a single forward pass, without simulator calls or inference-time MCMC. We introduce two complementary training routes: (i) synthesize off-manifold samples $(θ,x) \sim π(θ)\,p(x \mid θ)^β$ and (ii) reweight a fixed base dataset $π(θ)\,p(x \mid θ)$ using self-normalized importance sampling (SNIS). We show that the SNIS-weighted objective provides a consistent forward-KL fit to the tempered posterior with finite weight variance. Across four standard simulation-based inference (SBI) benchmarks, including the chaotic Lorenz-96 system, our $β$-amortized estimator achieves competitive posterior approximations in standard two-sample metrics, matching non-amortized MCMC-based power-posterior samplers over a wide range of temperatures.
Read Like a Radiologist: Efficient Vision-Language Model for 3D Medical Imaging Interpretation
Dec 18, 2024



Recent medical vision-language models (VLMs) have shown promise in 2D medical image interpretation. However extending them to 3D medical imaging has been challenging due to computational complexities and data scarcity. Although a few recent VLMs specified for 3D medical imaging have emerged, all are limited to learning volumetric representation of a 3D medical image as a set of sub-volumetric features. Such process introduces overly correlated representations along the z-axis that neglect slice-specific clinical details, particularly for 3D medical images where adjacent slices have low redundancy. To address this limitation, we introduce MS-VLM that mimic radiologists' workflow in 3D medical image interpretation. Specifically, radiologists analyze 3D medical images by examining individual slices sequentially and synthesizing information across slices and views. Likewise, MS-VLM leverages self-supervised 2D transformer encoders to learn a volumetric representation that capture inter-slice dependencies from a sequence of slice-specific features. Unbound by sub-volumetric patchification, MS-VLM is capable of obtaining useful volumetric representations from 3D medical images with any slice length and from multiple images acquired from different planes and phases. We evaluate MS-VLM on publicly available chest CT dataset CT-RATE and in-house rectal MRI dataset. In both scenarios, MS-VLM surpasses existing methods in radiology report generation, producing more coherent and clinically relevant reports. These findings highlight the potential of MS-VLM to advance 3D medical image interpretation and improve the robustness of medical VLMs.
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Feb 27, 2023



Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by transcribing spoken words into text. In the medical field, STT has the potential to significantly reduce the workload of clinicians who rely on typists to transcribe their voice recordings. However, developing an STT model for the medical domain is challenging due to the lack of sufficient speech and text datasets. To address this issue, we propose a medical-domain text correction method that modifies the output text of a general STT system using the Vision Language Pre-training (VLP) method. VLP combines textual and visual information to correct text based on image knowledge. Our extensive experiments demonstrate that the proposed method offers quantitatively and clinically significant improvements in STT performance in the medical field. We further show that multi-modal understanding of image and text information outperforms single-modal understanding using only text information.
Annealed Score-Based Diffusion Model for MR Motion Artifact Reduction
Jan 08, 2023Motion artifact reduction is one of the important research topics in MR imaging, as the motion artifact degrades image quality and makes diagnosis difficult. Recently, many deep learning approaches have been studied for motion artifact reduction. Unfortunately, most existing models are trained in a supervised manner, requiring paired motion-corrupted and motion-free images, or are based on a strict motion-corruption model, which limits their use for real-world situations. To address this issue, here we present an annealed score-based diffusion model for MRI motion artifact reduction. Specifically, we train a score-based model using only motion-free images, and then motion artifacts are removed by applying forward and reverse diffusion processes repeatedly to gradually impose a low-frequency data consistency. Experimental results verify that the proposed method successfully reduces both simulated and in vivo motion artifacts, outperforming the state-of-the-art deep learning methods.
Alternating Cross-attention Vision-Language Model for Efficient Learning with Medical Image and Report without Curation
Aug 10, 2022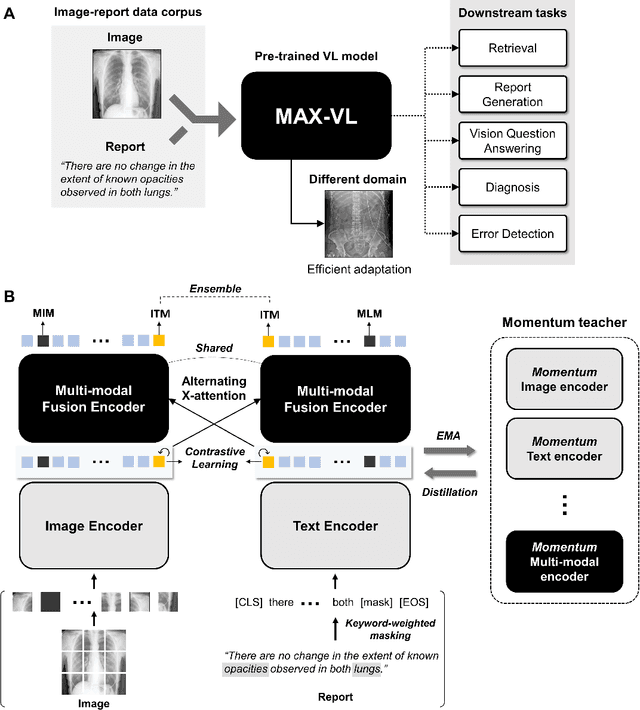
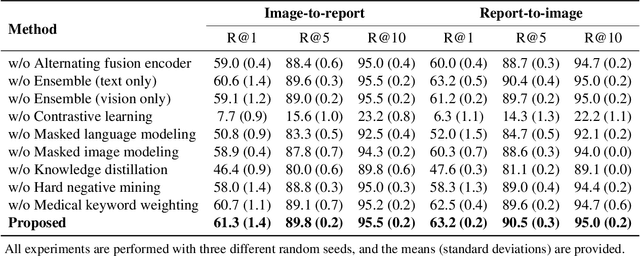
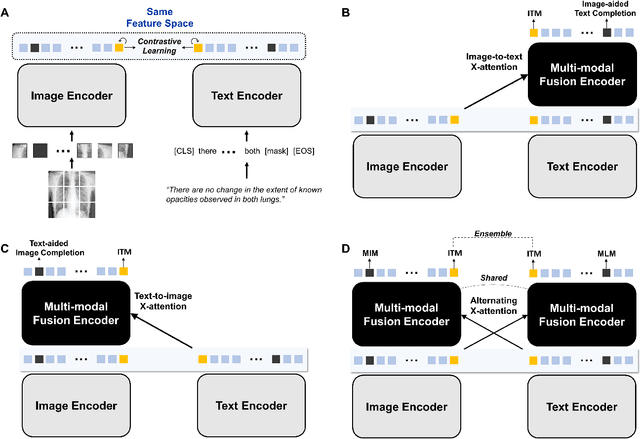
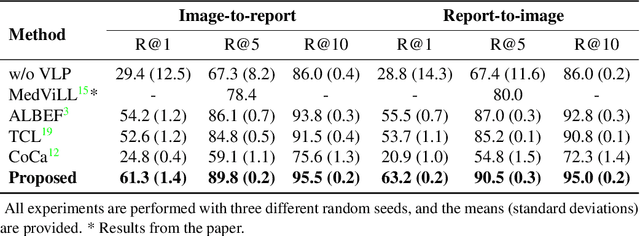
Recent advances in vision-language pre-training have demonstrated astounding performances in diverse vision-language tasks, shedding a light on the long-standing problems of a comprehensive understanding of both visual and textual concepts in artificial intelligence research. However, there has been limited success in the application of vision-language pre-training in the medical domain, as the current vision-language models and learning strategies for photographic images and captions are not optimal to process the medical data which are usually insufficient in the amount and the diversity, which impedes successful learning of joint vision-language concepts. In this study, we introduce MAX-VL, a model tailored for efficient vision-language pre-training in the medical domain. We experimentally demonstrated that the pre-trained MAX-VL model outperforms the current state-of-the-art vision language models in various vision-language tasks. We also suggested the clinical utility for the diagnosis of newly emerging diseases and human error detection as well as showed the widespread applicability of the model in different domain data.
Unsupervised MR Motion Artifact Deep Learning using Outlier-Rejecting Bootstrap Aggregation
Nov 12, 2020
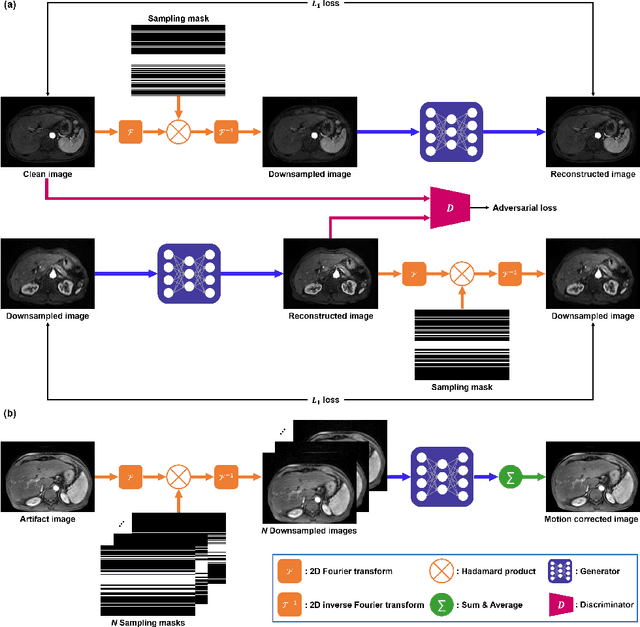
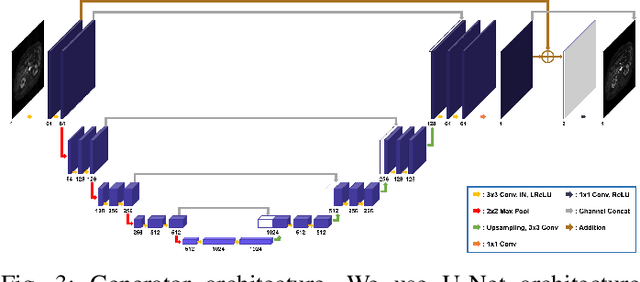
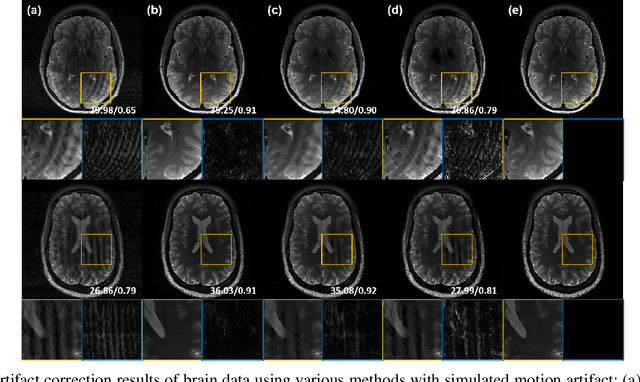
Recently, deep learning approaches for MR motion artifact correction have been extensively studied. Although these approaches have shown high performance and reduced computational complexity compared to classical methods, most of them require supervised training using paired artifact-free and artifact-corrupted images, which may prohibit its use in many important clinical applications. For example, transient severe motion (TSM) due to acute transient dyspnea in Gd-EOB-DTPA-enhanced MR is difficult to control and model for paired data generation. To address this issue, here we propose a novel unsupervised deep learning scheme through outlier-rejecting bootstrap subsampling and aggregation. This is inspired by the observation that motions usually cause sparse k-space outliers in the phase encoding direction, so k-space subsampling along the phase encoding direction can remove some outliers and the aggregation step can further improve the results from the reconstruction network. Our method does not require any paired data because the training step only requires artifact-free images. Furthermore, to address the smoothing from potential bias to the artifact-free images, the network is trained in an unsupervised manner using optimal transport driven cycleGAN. We verify that our method can be applied for artifact correction from simulated motion as well as real motion from TSM successfully, outperforming existing state-of-the-art deep learning methods.