 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead Like a Radiologist: Efficient Vision-Language Model for 3D Medical Imaging Interpretation
Dec 18, 2024



Recent medical vision-language models (VLMs) have shown promise in 2D medical image interpretation. However extending them to 3D medical imaging has been challenging due to computational complexities and data scarcity. Although a few recent VLMs specified for 3D medical imaging have emerged, all are limited to learning volumetric representation of a 3D medical image as a set of sub-volumetric features. Such process introduces overly correlated representations along the z-axis that neglect slice-specific clinical details, particularly for 3D medical images where adjacent slices have low redundancy. To address this limitation, we introduce MS-VLM that mimic radiologists' workflow in 3D medical image interpretation. Specifically, radiologists analyze 3D medical images by examining individual slices sequentially and synthesizing information across slices and views. Likewise, MS-VLM leverages self-supervised 2D transformer encoders to learn a volumetric representation that capture inter-slice dependencies from a sequence of slice-specific features. Unbound by sub-volumetric patchification, MS-VLM is capable of obtaining useful volumetric representations from 3D medical images with any slice length and from multiple images acquired from different planes and phases. We evaluate MS-VLM on publicly available chest CT dataset CT-RATE and in-house rectal MRI dataset. In both scenarios, MS-VLM surpasses existing methods in radiology report generation, producing more coherent and clinically relevant reports. These findings highlight the potential of MS-VLM to advance 3D medical image interpretation and improve the robustness of medical VLMs.
Breast Ultrasound Report Generation using LangChain
Dec 05, 2023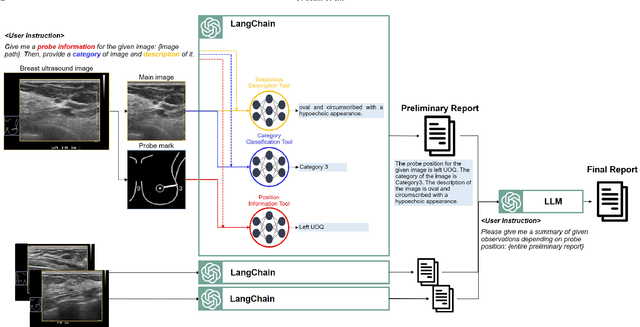
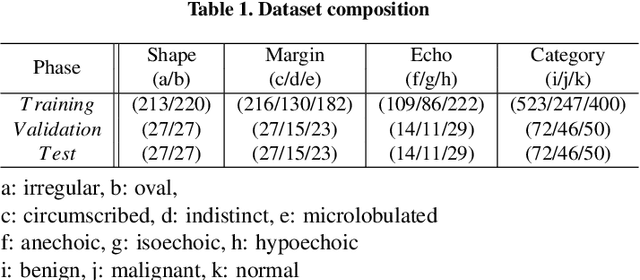
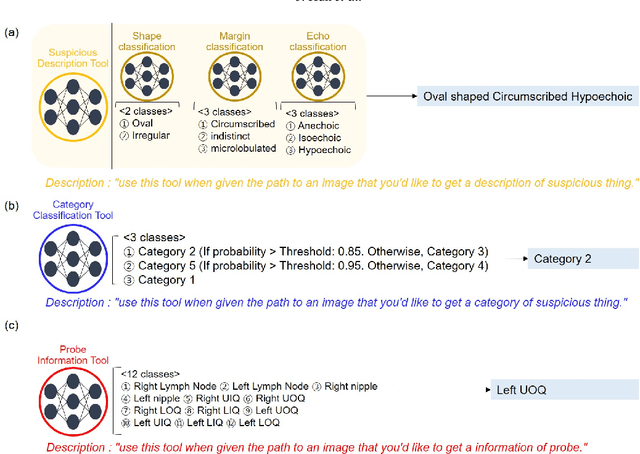
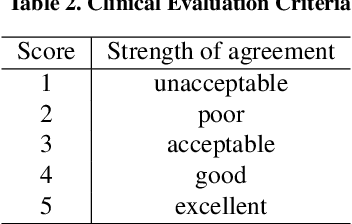
Breast ultrasound (BUS) is a critical diagnostic tool in the field of breast imaging, aiding in the early detection and characterization of breast abnormalities. Interpreting breast ultrasound images commonly involves creating comprehensive medical reports, containing vital information to promptly assess the patient's condition. However, the ultrasound imaging system necessitates capturing multiple images of various parts to compile a single report, presenting a time-consuming challenge. To address this problem, we propose the integration of multiple image analysis tools through a LangChain using Large Language Models (LLM), into the breast reporting process. Through a combination of designated tools and text generation through LangChain, our method can accurately extract relevant features from ultrasound images, interpret them in a clinical context, and produce comprehensive and standardized reports. This approach not only reduces the burden on radiologists and healthcare professionals but also enhances the consistency and quality of reports. The extensive experiments shows that each tools involved in the proposed method can offer qualitatively and quantitatively significant results. Furthermore, clinical evaluation on the generated reports demonstrates that the proposed method can make report in clinically meaningful way.