 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Synthesis with Sparse and Flexible Keyjoint Control
Mar 18, 2025Creating expressive character animations is labor-intensive, requiring intricate manual adjustment of animators across space and time. Previous works on controllable motion generation often rely on a predefined set of dense spatio-temporal specifications (e.g., dense pelvis trajectories with exact per-frame timing), limiting practicality for animators. To process high-level intent and intuitive control in diverse scenarios, we propose a practical controllable motions synthesis framework that respects sparse and flexible keyjoint signals. Our approach employs a decomposed diffusion-based motion synthesis framework that first synthesizes keyjoint movements from sparse input control signals and then synthesizes full-body motion based on the completed keyjoint trajectories. The low-dimensional keyjoint movements can easily adapt to various control signal types, such as end-effector position for diverse goal-driven motion synthesis, or incorporate functional constraints on a subset of keyjoints. Additionally, we introduce a time-agnostic control formulation, eliminating the need for frame-specific timing annotations and enhancing control flexibility. Then, the shared second stage can synthesize a natural whole-body motion that precisely satisfies the task requirement from dense keyjoint movements. We demonstrate the effectiveness of sparse and flexible keyjoint control through comprehensive experiments on diverse datasets and scenarios.
Versatile Physics-based Character Control with Hybrid Latent Representation
Mar 17, 2025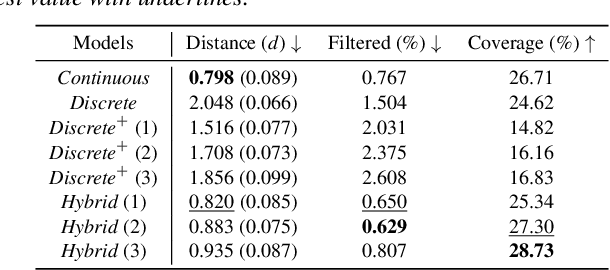
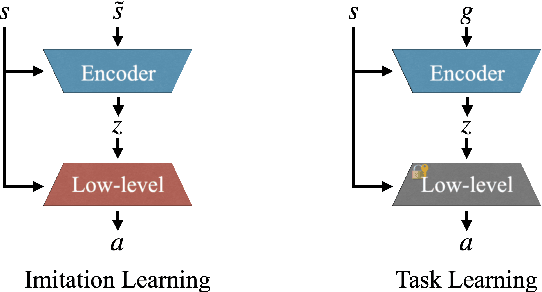

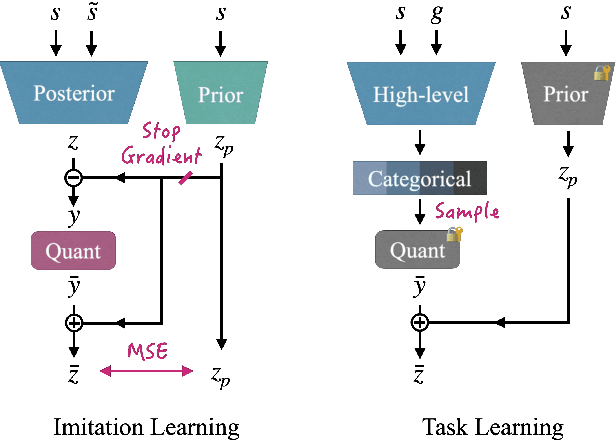
We present a versatile latent representation that enables physically simulated character to efficiently utilize motion priors. To build a powerful motion embedding that is shared across multiple tasks, the physics controller should employ rich latent space that is easily explored and capable of generating high-quality motion. We propose integrating continuous and discrete latent representations to build a versatile motion prior that can be adapted to a wide range of challenging control tasks. Specifically, we build a discrete latent model to capture distinctive posterior distribution without collapse, and simultaneously augment the sampled vector with the continuous residuals to generate high-quality, smooth motion without jittering. We further incorporate Residual Vector Quantization, which not only maximizes the capacity of the discrete motion prior, but also efficiently abstracts the action space during the task learning phase. We demonstrate that our agent can produce diverse yet smooth motions simply by traversing the learned motion prior through unconditional motion generation. Furthermore, our model robustly satisfies sparse goal conditions with highly expressive natural motions, including head-mounted device tracking and motion in-betweening at irregular intervals, which could not be achieved with existing latent representations.
PMP: Learning to Physically Interact with Environments using Part-wise Motion Priors
May 05, 2023We present a method to animate a character incorporating multiple part-wise motion priors (PMP). While previous works allow creating realistic articulated motions from reference data, the range of motion is largely limited by the available samples. Especially for the interaction-rich scenarios, it is impractical to attempt acquiring every possible interacting motion, as the combination of physical parameters increases exponentially. The proposed PMP allows us to assemble multiple part skills to animate a character, creating a diverse set of motions with different combinations of existing data. In our pipeline, we can train an agent with a wide range of part-wise priors. Therefore, each body part can obtain a kinematic insight of the style from the motion captures, or at the same time extract dynamics-related information from the additional part-specific simulation. For example, we can first train a general interaction skill, e.g. grasping, only for the dexterous part, and then combine the expert trajectories from the pre-trained agent with the kinematic priors of other limbs. Eventually, our whole-body agent learns a novel physical interaction skill even with the absence of the object trajectories in the reference motion sequence.