 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneMI: Motion In-betweening for Modeling Human-Scene Interactions
Paper and Code
Mar 20, 2025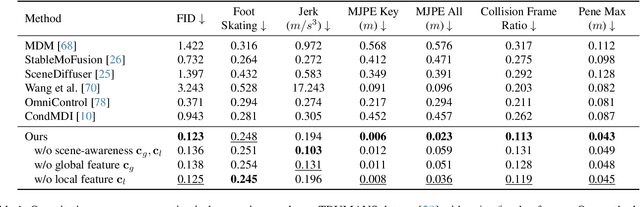
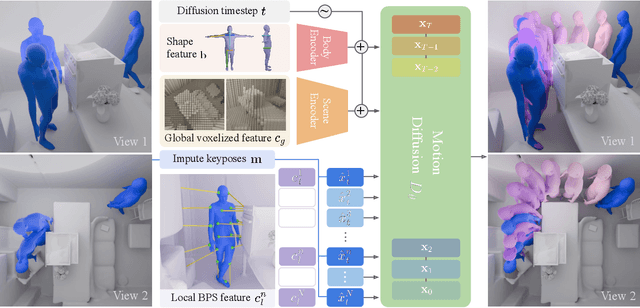

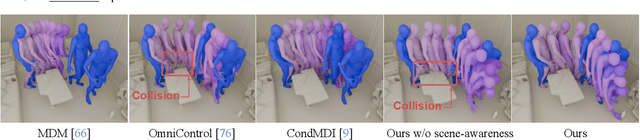
Modeling human-scene interactions (HSI) is essential for understanding and simulating everyday human behaviors. Recent approaches utilizing generative modeling have made progress in this domain; however, they are limited in controllability and flexibility for real-world applications. To address these challenges, we propose reformulating the HSI modeling problem as Scene-aware Motion In-betweening -- a more tractable and practical task. We introduce SceneMI, a framework that supports several practical applications, including keyframe-guided character animation in 3D scenes and enhancing the motion quality of imperfect HSI data. SceneMI employs dual scene descriptors to comprehensively encode global and local scene context. Furthermore, our framework leverages the inherent denoising nature of diffusion models to generalize on noisy keyframes. Experimental results demonstrate SceneMI's effectiveness in scene-aware keyframe in-betweening and generalization to the real-world GIMO dataset, where motions and scenes are acquired by noisy IMU sensors and smartphones. We further showcase SceneMI's applicability in HSI reconstruction from monocular videos.