 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bibliographic View on Constrained Clustering
Sep 22, 2022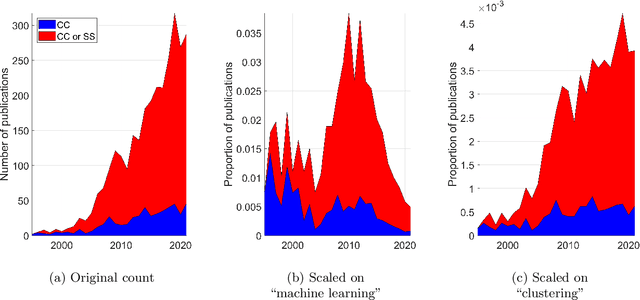
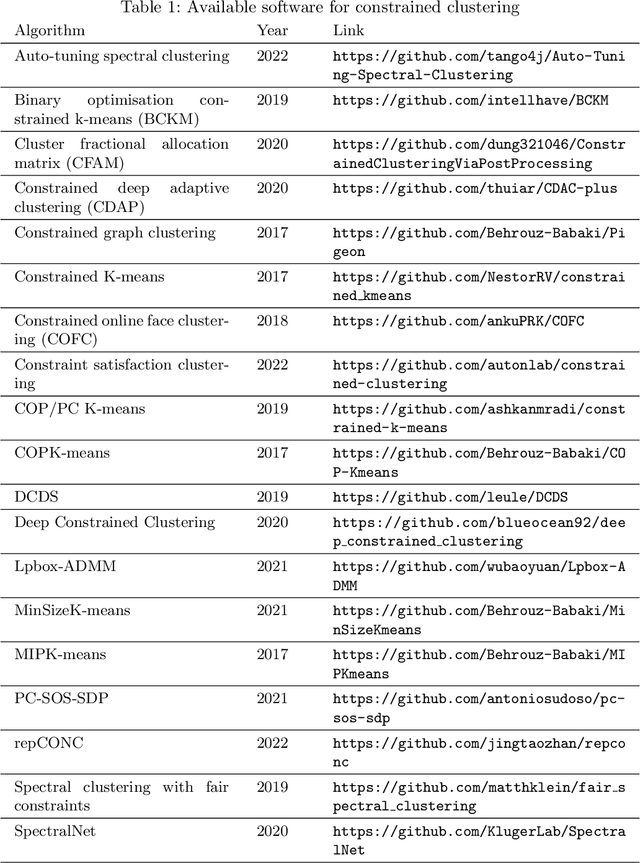
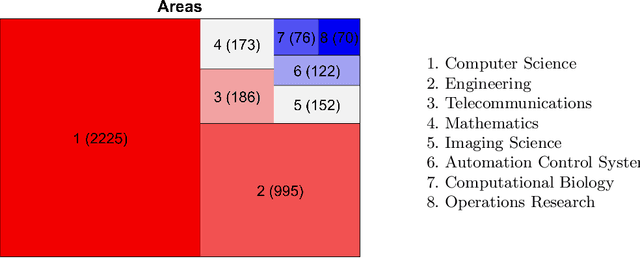
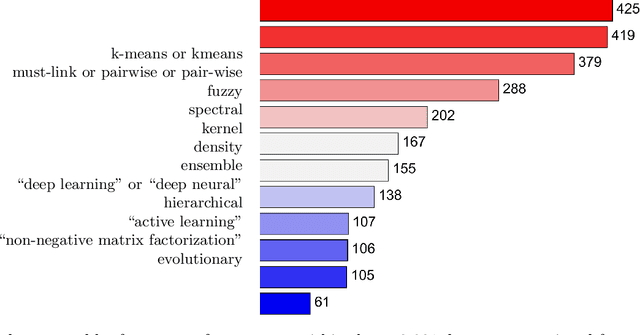
A keyword search on constrained clustering on Web-of-Science returned just under 3,000 documents. We ran automatic analyses of those, and compiled our own bibliography of 183 papers which we analysed in more detail based on their topic and experimental study, if any. This paper presents general trends of the area and its sub-topics by Pareto analysis, using citation count and year of publication. We list available software and analyse the experimental sections of our reference collection. We found a notable lack of large comparison experiments. Among the topics we reviewed, applications studies were most abundant recently, alongside deep learning, active learning and ensemble learning.
Learning from Exemplars and Prototypes in Machine Learning and Psychology
Jun 04, 2018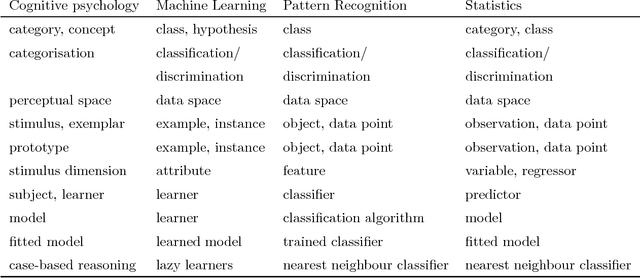
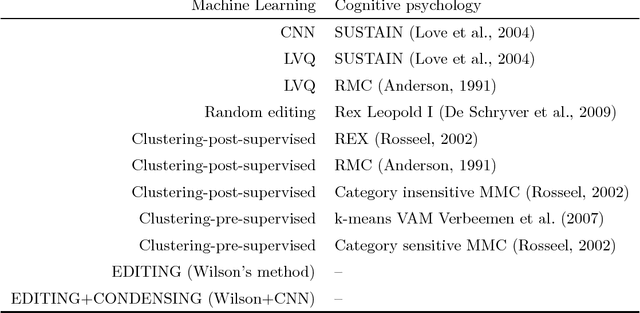
This paper draws a parallel between similarity-based categorisation models developed in cognitive psychology and the nearest neighbour classifier (1-NN) in machine learning. Conceived as a result of the historical rivalry between prototype theories (abstraction) and exemplar theories (memorisation), recent models of human categorisation seek a compromise in-between. Regarding the stimuli (entities to be categorised) as points in a metric space, machine learning offers a large collection of methods to select a small, representative and discriminative point set. These methods are known under various names: instance selection, data editing, prototype selection, prototype generation or prototype replacement. The nearest neighbour classifier is used with the selected reference set. Such a set can be interpreted as a data-driven categorisation model. We juxtapose the models from the two fields to enable cross-referencing. We believe that both machine learning and cognitive psychology can draw inspiration from the comparison and enrich their repertoire of similarity-based models.
Pre-Selection of Independent Binary Features: An Application to Diagnosing Scrapie in Sheep
Jul 11, 2012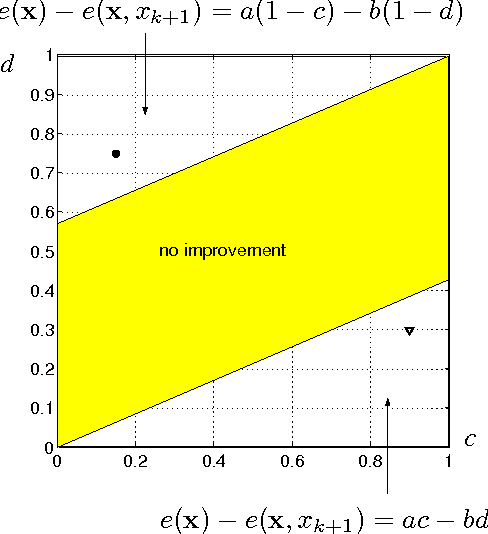
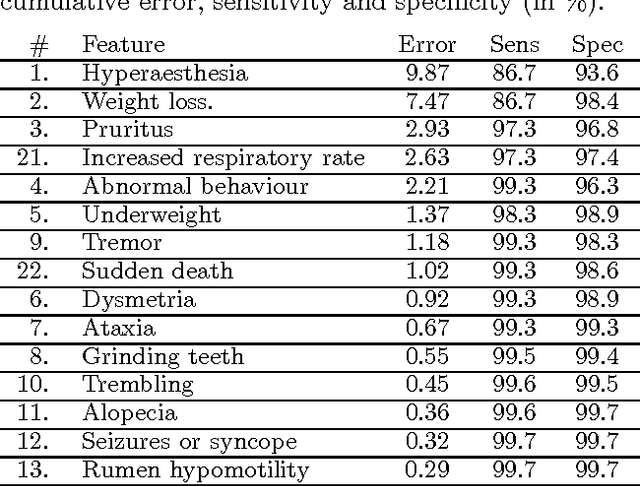
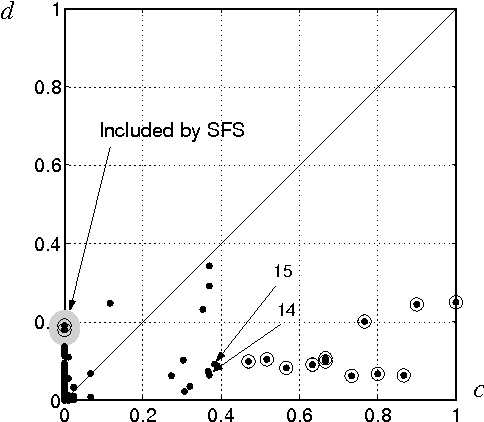
Suppose that the only available information in a multi-class problem are expert estimates of the conditional probabilities of occurrence for a set of binary features. The aim is to select a subset of features to be measured in subsequent data collection experiments. In the lack of any information about the dependencies between the features, we assume that all features are conditionally independent and hence choose the Naive Bayes classifier as the optimal classifier for the problem. Even in this (seemingly trivial) case of complete knowledge of the distributions, choosing an optimal feature subset is not straightforward. We discuss the properties and implementation details of Sequential Forward Selection (SFS) as a feature selection procedure for the current problem. A sensitivity analysis was carried out to investigate whether the same features are selected when the probabilities vary around the estimated values. The procedure is illustrated with a set of probability estimates for Scrapie in sheep.