 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Act Robustly with View-Invariant Latent Actions
Jan 06, 2026Vision-based robotic policies often struggle with even minor viewpoint changes, underscoring the need for view-invariant visual representations. This challenge becomes more pronounced in real-world settings, where viewpoint variability is unavoidable and can significantly disrupt policy performance. Existing methods typically learn invariance from multi-view observations at the scene level, but such approaches rely on visual appearance and fail to incorporate the physical dynamics essential for robust generalization. We propose View-Invariant Latent Action (VILA), which models a latent action capturing transition patterns across trajectories to learn view-invariant representations grounded in physical dynamics. VILA aligns these latent actions across viewpoints using an action-guided objective based on ground-truth action sequences. Experiments in both simulation and the real world show that VILA-based policies generalize effectively to unseen viewpoints and transfer well to new tasks, establishing VILA as a strong pretraining framework that improves robustness and downstream learning performance.
Object-Centric World Model for Language-Guided Manipulation
Mar 08, 2025A world model is essential for an agent to predict the future and plan in domains such as autonomous driving and robotics. To achieve this, recent advancements have focused on video generation, which has gained significant attention due to the impressive success of diffusion models. However, these models require substantial computational resources. To address these challenges, we propose a world model leveraging object-centric representation space using slot attention, guided by language instructions. Our model perceives the current state as an object-centric representation and predicts future states in this representation space conditioned on natural language instructions. This approach results in a more compact and computationally efficient model compared to diffusion-based generative alternatives. Furthermore, it flexibly predicts future states based on language instructions, and offers a significant advantage in manipulation tasks where object recognition is crucial. In this paper, we demonstrate that our latent predictive world model surpasses generative world models in visuo-linguo-motor control tasks, achieving superior sample and computation efficiency. We also investigate the generalization performance of the proposed method and explore various strategies for predicting actions using object-centric representations.
Spatial Semantic Embedding Network: Fast 3D Instance Segmentation with Deep Metric Learning
Jul 07, 2020
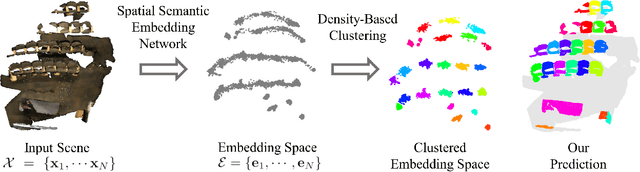


We propose spatial semantic embedding network (SSEN), a simple, yet efficient algorithm for 3D instance segmentation using deep metric learning. The raw 3D reconstruction of an indoor environment suffers from occlusions, noise, and is produced without any meaningful distinction between individual entities. For high-level intelligent tasks from a large scale scene, 3D instance segmentation recognizes individual instances of objects. We approach the instance segmentation by simply learning the correct embedding space that maps individual instances of objects into distinct clusters that reflect both spatial and semantic information. Unlike previous approaches that require complex pre-processing or post-processing, our implementation is compact and fast with competitive performance, maintaining scalability on large scenes with high resolution voxels. We demonstrate the state-of-the-art performance of our algorithm in the ScanNet 3D instance segmentation benchmark on AP score.