 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINGREX: An Interactive Explanation Framework for Graph Neural Networks
Nov 03, 2022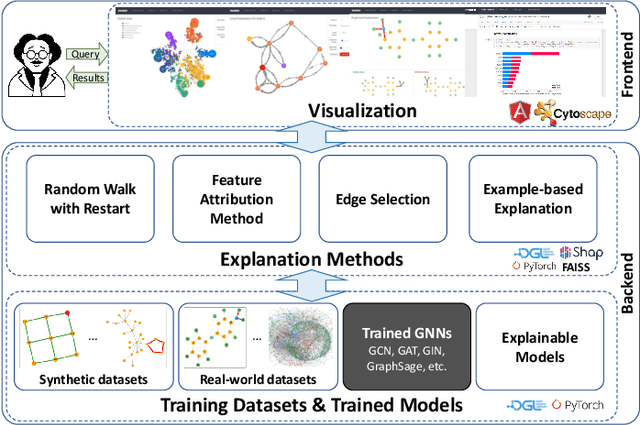
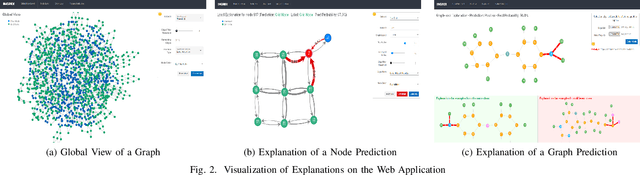
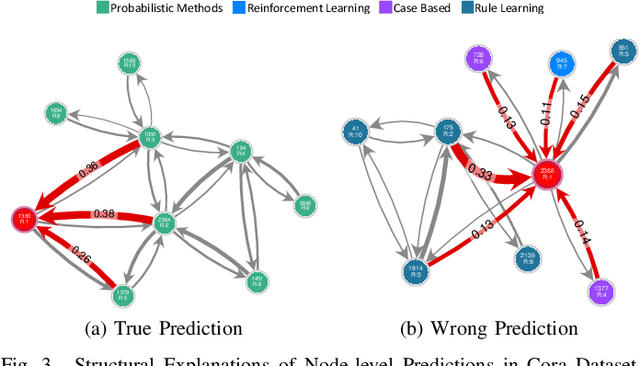
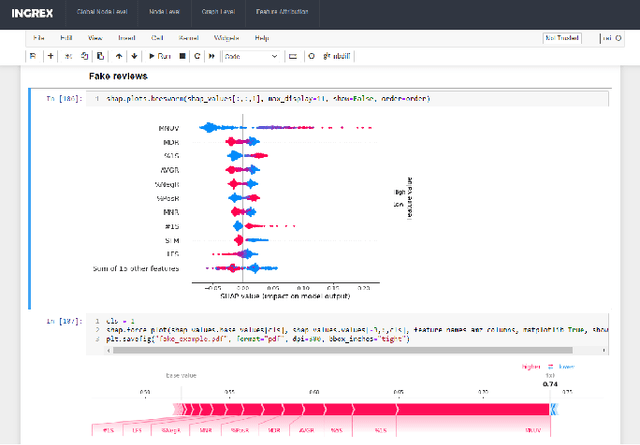
Graph Neural Networks (GNNs) are widely used in many modern applications, necessitating explanations for their decisions. However, the complexity of GNNs makes it difficult to explain predictions. Even though several methods have been proposed lately, they can only provide simple and static explanations, which are difficult for users to understand in many scenarios. Therefore, we introduce INGREX, an interactive explanation framework for GNNs designed to aid users in comprehending model predictions. Our framework is implemented based on multiple explanation algorithms and advanced libraries. We demonstrate our framework in three scenarios covering common demands for GNN explanations to present its effectiveness and helpfulness.
Generative Pre-training for Paraphrase Generation by Representing and Predicting Spans in Exemplars
Nov 29, 2020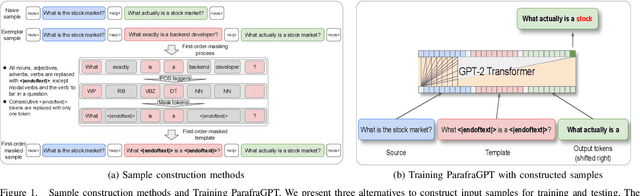
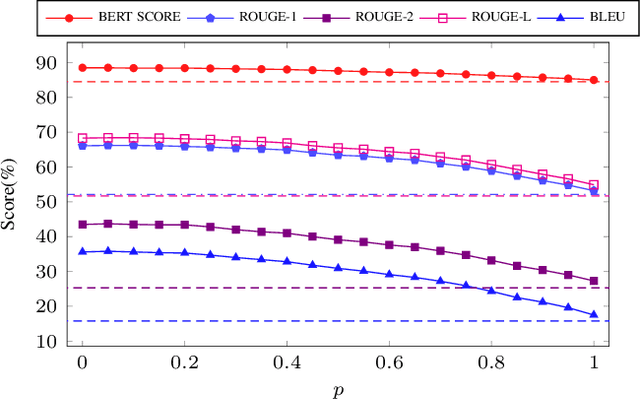
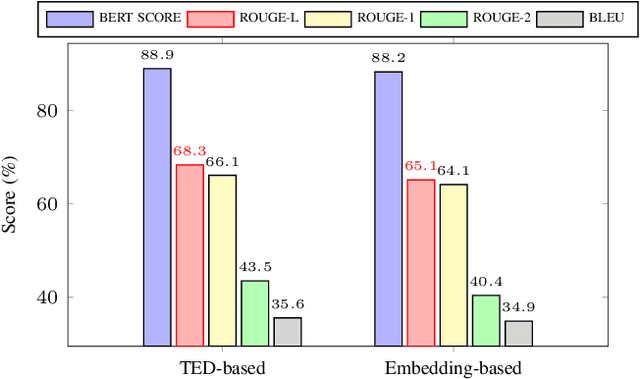
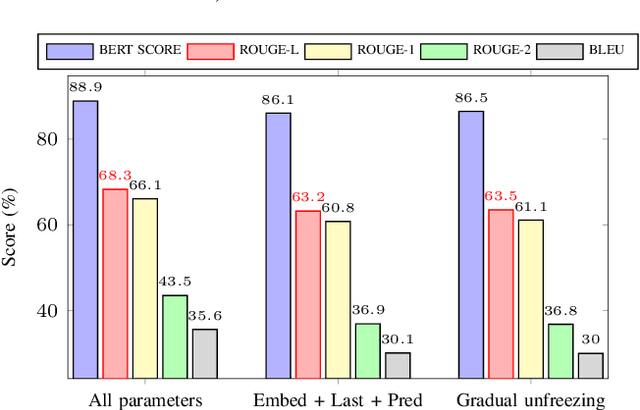
Paraphrase generation is a long-standing problem and serves an essential role in many natural language processing problems. Despite some encouraging results, recent methods either confront the problem of favoring generic utterance or need to retrain the model from scratch for each new dataset. This paper presents a novel approach to paraphrasing sentences, extended from the GPT-2 model. We develop a template masking technique, named first-order masking, to masked out irrelevant words in exemplars utilizing POS taggers. So that, the paraphrasing task is changed to predicting spans in masked templates. Our proposed approach outperforms competitive baselines, especially in the semantic preservation aspect. To prevent the model from being biased towards a given template, we introduce a technique, referred to as second-order masking, which utilizes Bernoulli distribution to control the visibility of the first-order-masked template's tokens. Moreover, this technique allows the model to provide various paraphrased sentences in testing by adjusting the second-order-masking level. For scale-up objectives, we compare the performance of two alternatives template-selection methods, which shows that they were equivalent in preserving semantic information.
Spatial Semantic Embedding Network: Fast 3D Instance Segmentation with Deep Metric Learning
Jul 07, 2020
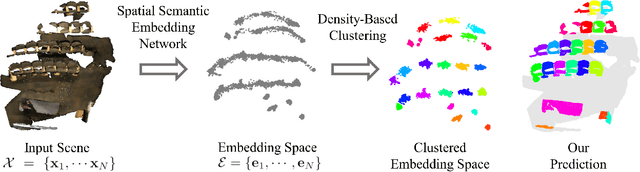


We propose spatial semantic embedding network (SSEN), a simple, yet efficient algorithm for 3D instance segmentation using deep metric learning. The raw 3D reconstruction of an indoor environment suffers from occlusions, noise, and is produced without any meaningful distinction between individual entities. For high-level intelligent tasks from a large scale scene, 3D instance segmentation recognizes individual instances of objects. We approach the instance segmentation by simply learning the correct embedding space that maps individual instances of objects into distinct clusters that reflect both spatial and semantic information. Unlike previous approaches that require complex pre-processing or post-processing, our implementation is compact and fast with competitive performance, maintaining scalability on large scenes with high resolution voxels. We demonstrate the state-of-the-art performance of our algorithm in the ScanNet 3D instance segmentation benchmark on AP score.
An Attention-Based Speaker Naming Method for Online Adaptation in Non-Fixed Scenarios
Dec 02, 2019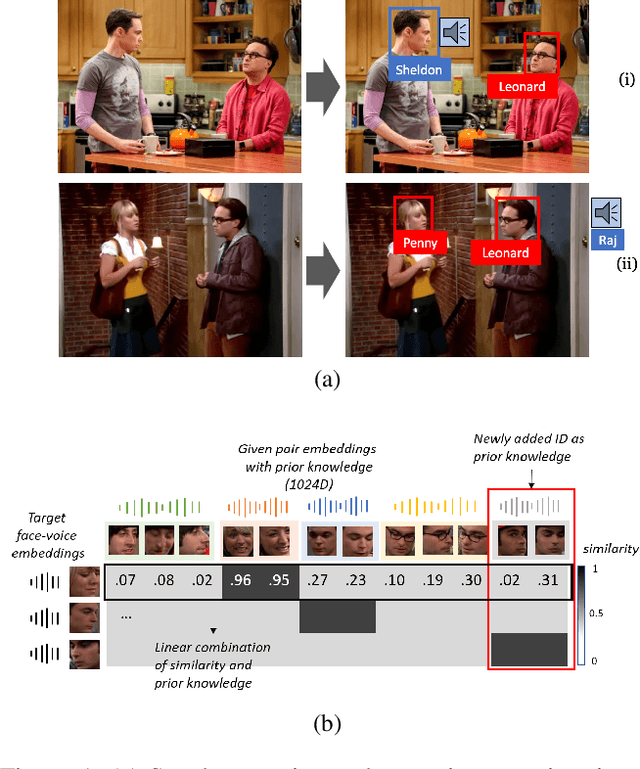
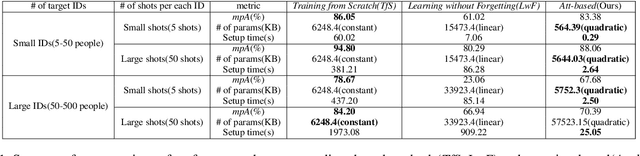
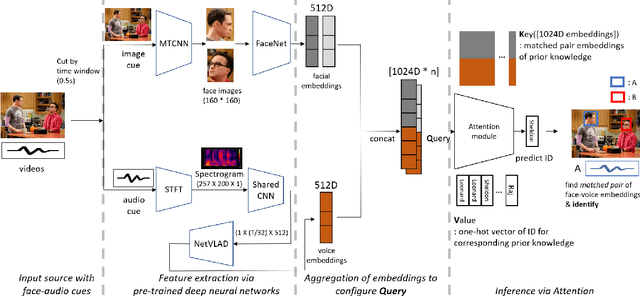

A speaker naming task, which finds and identifies the active speaker in a certain movie or drama scene, is crucial for dealing with high-level video analysis applications such as automatic subtitle labeling and video summarization. Modern approaches have usually exploited biometric features with a gradient-based method instead of rule-based algorithms. In a certain situation, however, a naive gradient-based method does not work efficiently. For example, when new characters are added to the target identification list, the neural network needs to be frequently retrained to identify new people and it causes delays in model preparation. In this paper, we present an attention-based method which reduces the model setup time by updating the newly added data via online adaptation without a gradient update process. We comparatively analyzed with three evaluation metrics(accuracy, memory usage, setup time) of the attention-based method and existing gradient-based methods under various controlled settings of speaker naming. Also, we applied existing speaker naming models and the attention-based model to real video to prove that our approach shows comparable accuracy to the existing state-of-the-art models and even higher accuracy in some cases.
Spatiotemporal deep learning model for citywide air pollution interpolation and prediction
Nov 29, 2019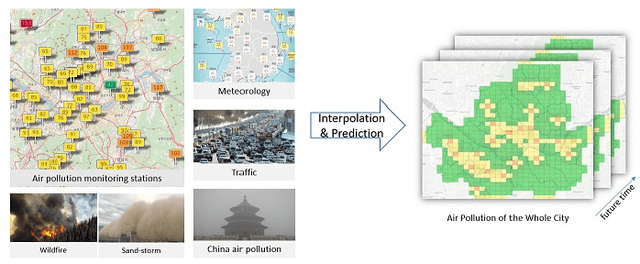
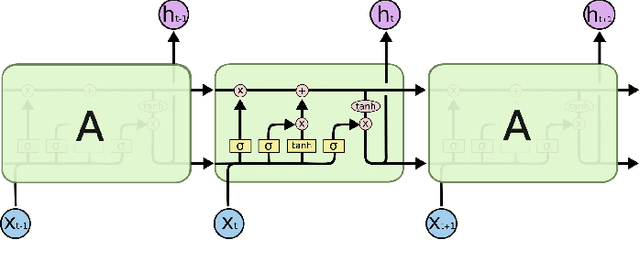
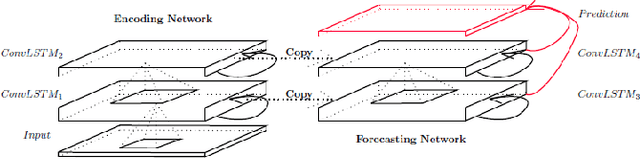
Recently, air pollution is one of the most concerns for big cities. Predicting air quality for any regions and at any time is a critical requirement of urban citizens. However, air pollution prediction for the whole city is a challenging problem. The reason is, there are many spatiotemporal factors affecting air pollution throughout the city. Collecting as many of them could help us to forecast air pollution better. In this research, we present many spatiotemporal datasets collected over Seoul city in Korea, which is currently much suffered by air pollution problem as well. These datasets include air pollution data, meteorological data, traffic volume, average driving speed, and air pollution indexes of external areas which are known to impact Seoul's air pollution. To the best of our knowledge, traffic volume and average driving speed data are two new datasets in air pollution research. In addition, recent research in air pollution has tried to build models to interpolate and predict air pollution in the city. Nevertheless, they mostly focused on predicting air quality in discrete locations or used hand-crafted spatial and temporal features. In this paper, we propose the usage of Convolutional Long Short-Term Memory (ConvLSTM) model \cite{b16}, a combination of Convolutional Neural Networks and Long Short-Term Memory, which automatically manipulates both the spatial and temporal features of the data. Specially, we introduce how to transform the air pollution data into sequences of images which leverages the using of ConvLSTM model to interpolate and predict air quality for the entire city at the same time. We prove that our approach is suitable for spatiotemporal air pollution problems and also outperforms other related research.
Real-time Air Pollution prediction model based on Spatiotemporal Big data
Aug 10, 2018
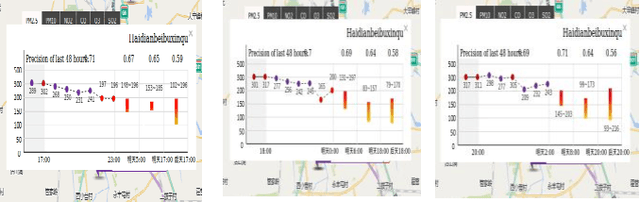

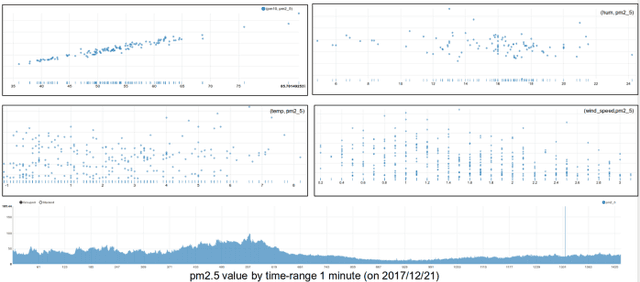
Air pollution is one of the most concerns for urban areas. Many countries have constructed monitoring stations to hourly collect pollution values. Recently, there is a research in Daegu city, Korea for real-time air quality monitoring via sensors installed on taxis running across the whole city. The collected data is huge (1-second interval) and in both Spatial and Temporal format. In this paper, based on this spatiotemporal Big data, we propose a real-time air pollution prediction model based on Convolutional Neural Network (CNN) algorithm for image-like Spatial distribution of air pollution. Regarding to Temporal information in the data, we introduce a combination of a Long Short-Term Memory (LSTM) unit for time series data and a Neural Network model for other air pollution impact factors such as weather conditions to build a hybrid prediction model. This model is simple in architecture but still brings good prediction ability.
* 6 pages