 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Reranker: Maximizing performance of retrieval-augmented generation in the FinanceRAG challenge
Nov 23, 2024

As Large Language Models (LLMs) increasingly address domain-specific problems, their application in the financial sector has expanded rapidly. Tasks that are both highly valuable and time-consuming, such as analyzing financial statements, disclosures, and related documents, are now being effectively tackled using LLMs. This paper details the development of a high-performance, finance-specific Retrieval-Augmented Generation (RAG) system for the ACM-ICAIF '24 FinanceRAG competition. We optimized performance through ablation studies on query expansion and corpus refinement during the pre-retrieval phase. To enhance retrieval accuracy, we employed multiple reranker models. Notably, we introduced an efficient method for managing long context sizes during the generation phase, significantly improving response quality without sacrificing performance. We ultimately achieve 2nd place in the FinanceRAG Challenge. Our key contributions include: (1) pre-retrieval ablation analysis, (2) an enhanced retrieval algorithm, and (3) a novel approach for long-context management. This work demonstrates the potential of LLMs in effectively processing and analyzing complex financial data to generate accurate and valuable insights. The source code and further details are available at https://github.com/cv-lee/FinanceRAG.
Dynamic Anchor Selection and Real-Time Pose Prediction for Ultra-wideband Tagless Gate
Feb 22, 2024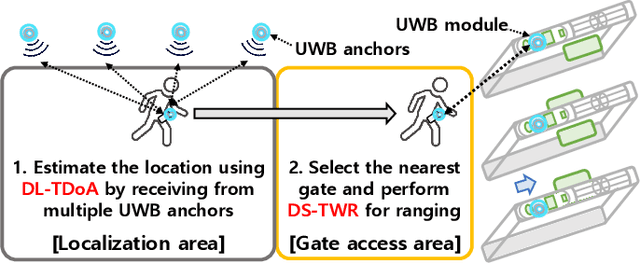
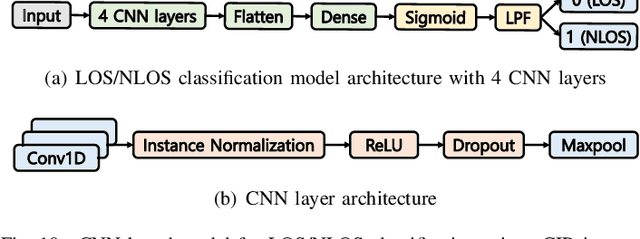
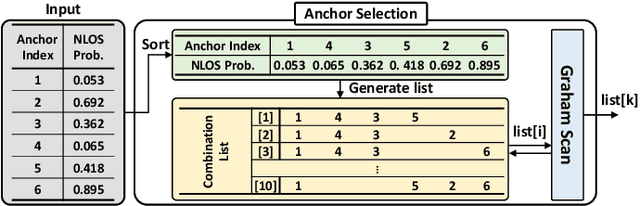
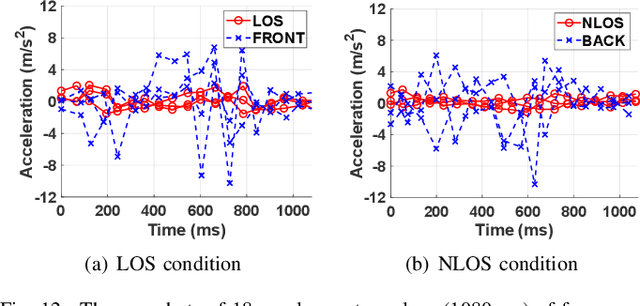
Ultra-wideband (UWB) is emerging as a promising solution that can realize proximity services, such as UWB tagless gate (UTG), thanks to centimeter-level localization accuracy based on two different ranging methods such as downlink time-difference of arrival (DL-TDoA) and double-sided two-way ranging (DS-TWR). The UTG is a UWB-based proximity service that provides a seamless gate pass system without requiring real-time mobile device (MD) tapping. The location of MD is calculated using DL-TDoA, and the MD communicates with the nearest UTG using DS-TWR to open the gate. Therefore, the knowledge about the exact location of MD is the main challenge of UTG, and hence we provide the solutions for both DL-TDoA and DS-TWR. In this paper, we propose dynamic anchor selection for extremely accurate DL-TDoA localization and pose prediction for DS-TWR, called DynaPose. The pose is defined as the actual location of MD on the human body, which affects the localization accuracy. DynaPose is based on line-of-sight (LOS) and non-LOS (NLOS) classification using deep learning for anchor selection and pose prediction. Deep learning models use the UWB channel impulse response and the inertial measurement unit embedded in the smartphone. DynaPose is implemented on Samsung Galaxy Note20 Ultra and Qorvo UWB board to show the feasibility and applicability. DynaPose achieves a LOS/NLOS classification accuracy of 0.984, 62% higher DL-TDoA localization accuracy, and ultimately detects four different poses with an accuracy of 0.961 in real-time.
Power-Efficient Indoor Localization Using Adaptive Channel-aware Ultra-wideband DL-TDOA
Feb 16, 2024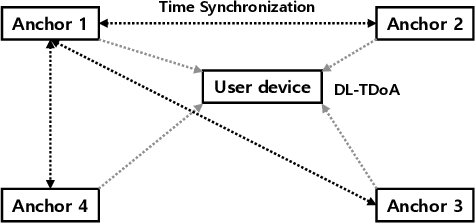
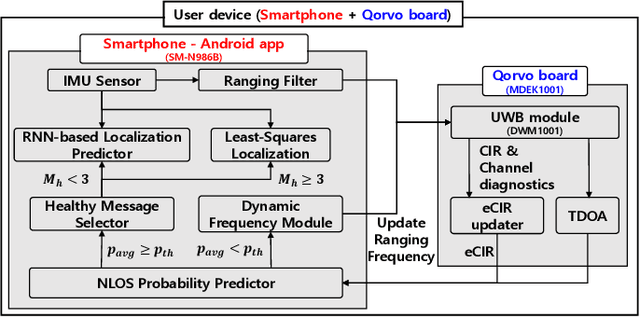
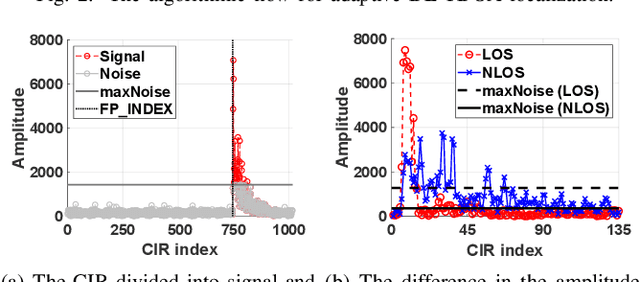

Among the various Ultra-wideband (UWB) ranging methods, the absence of uplink communication or centralized computation makes downlink time-difference-of-arrival (DL-TDOA) localization the most suitable for large-scale industrial deployments. However, temporary or permanent obstacles in the deployment region often lead to non-line-of-sight (NLOS) channel path and signal outage effects, which result in localization errors. Prior research has addressed this problem by increasing the ranging frequency, which leads to a heavy increase in the user device power consumption. It also does not contribute to any increase in localization accuracy under line-of-sight (LOS) conditions. In this paper, we propose and implement a novel low-power channel-aware dynamic frequency DL-TDOA ranging algorithm. It comprises NLOS probability predictor based on a convolutional neural network (CNN), a dynamic ranging frequency control module, and an IMU sensor-based ranging filter. Based on the conducted experiments, we show that the proposed algorithm achieves 50% higher accuracy in NLOS conditions while having 46% lower power consumption in LOS conditions compared to baseline methods from prior research.
An Attention-Based Speaker Naming Method for Online Adaptation in Non-Fixed Scenarios
Dec 02, 2019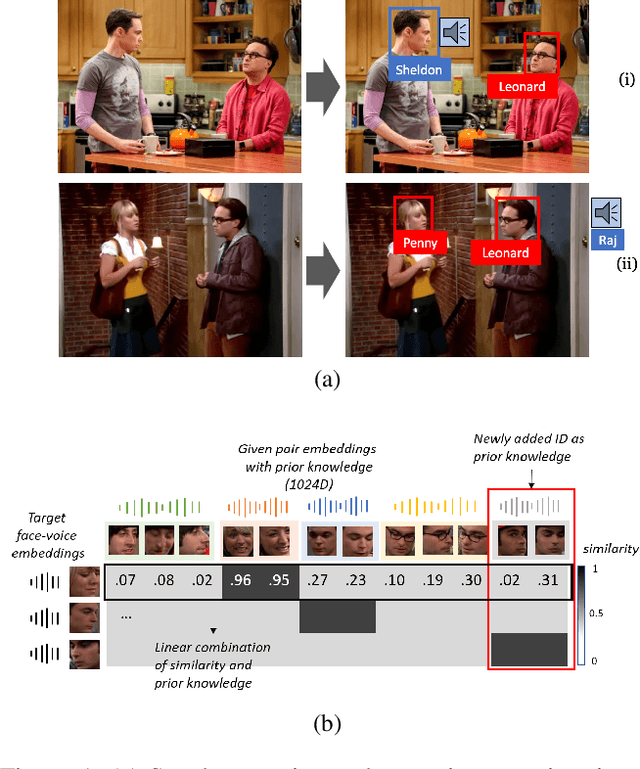
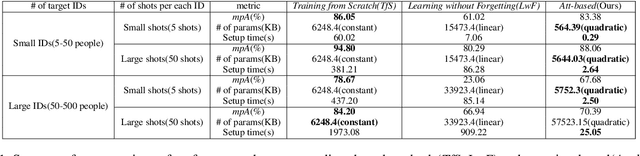
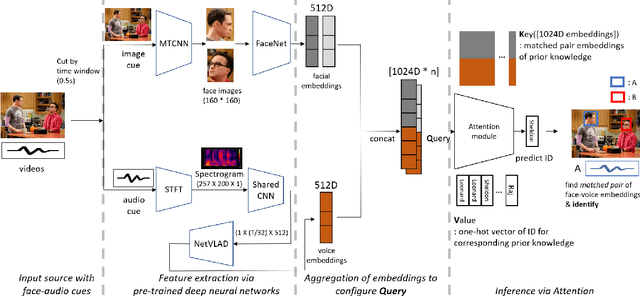

A speaker naming task, which finds and identifies the active speaker in a certain movie or drama scene, is crucial for dealing with high-level video analysis applications such as automatic subtitle labeling and video summarization. Modern approaches have usually exploited biometric features with a gradient-based method instead of rule-based algorithms. In a certain situation, however, a naive gradient-based method does not work efficiently. For example, when new characters are added to the target identification list, the neural network needs to be frequently retrained to identify new people and it causes delays in model preparation. In this paper, we present an attention-based method which reduces the model setup time by updating the newly added data via online adaptation without a gradient update process. We comparatively analyzed with three evaluation metrics(accuracy, memory usage, setup time) of the attention-based method and existing gradient-based methods under various controlled settings of speaker naming. Also, we applied existing speaker naming models and the attention-based model to real video to prove that our approach shows comparable accuracy to the existing state-of-the-art models and even higher accuracy in some cases.
A Change-Detection based Framework for Piecewise-stationary Multi-Armed Bandit Problem
Nov 20, 2017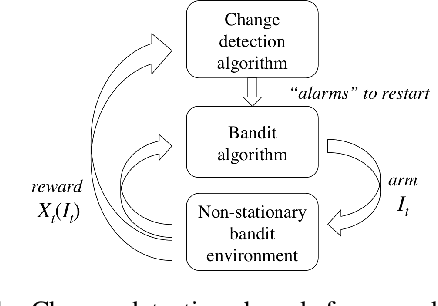

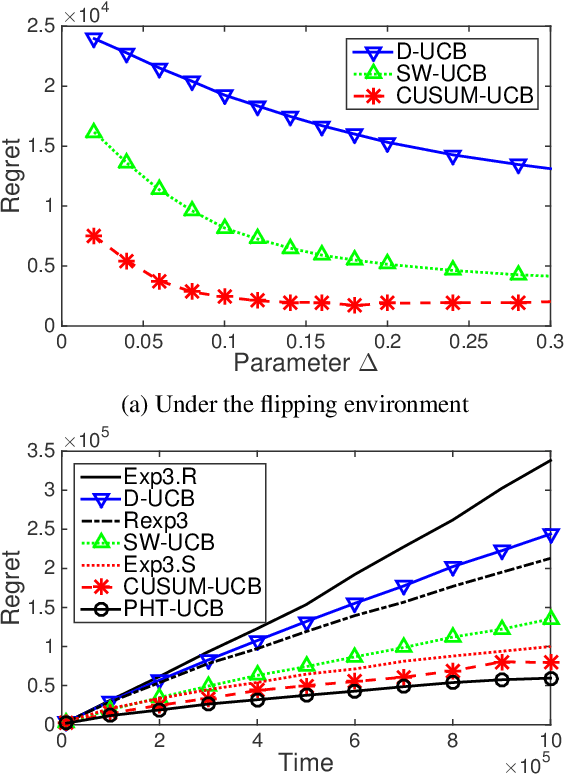
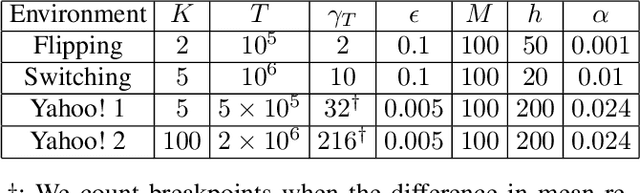
The multi-armed bandit problem has been extensively studied under the stationary assumption. However in reality, this assumption often does not hold because the distributions of rewards themselves may change over time. In this paper, we propose a change-detection (CD) based framework for multi-armed bandit problems under the piecewise-stationary setting, and study a class of change-detection based UCB (Upper Confidence Bound) policies, CD-UCB, that actively detects change points and restarts the UCB indices. We then develop CUSUM-UCB and PHT-UCB, that belong to the CD-UCB class and use cumulative sum (CUSUM) and Page-Hinkley Test (PHT) to detect changes. We show that CUSUM-UCB obtains the best known regret upper bound under mild assumptions. We also demonstrate the regret reduction of the CD-UCB policies over arbitrary Bernoulli rewards and Yahoo! datasets of webpage click-through rates.