 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning for Natural Language to SQL with Embedding Fine-Tuning and RAG
Nov 11, 2025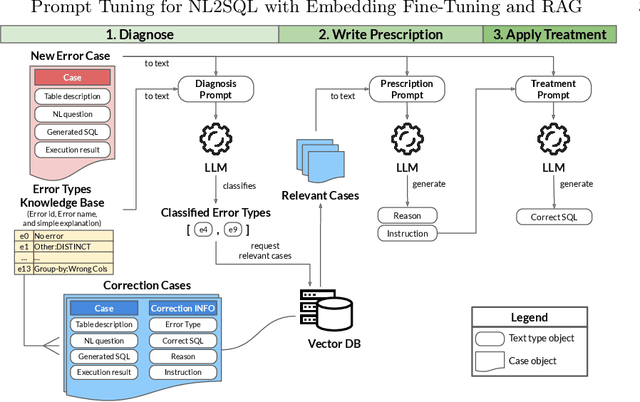
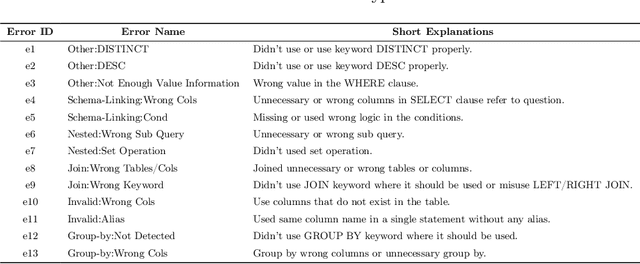
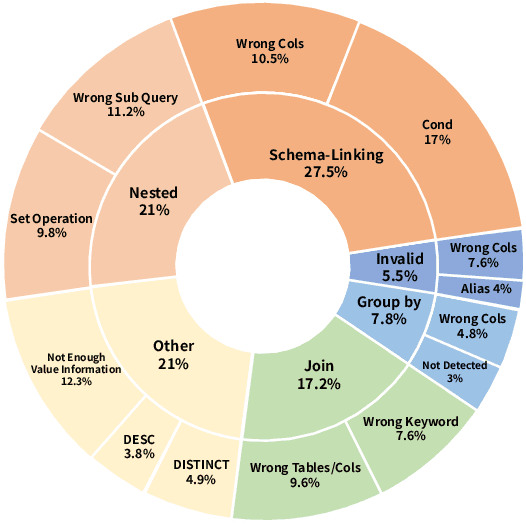
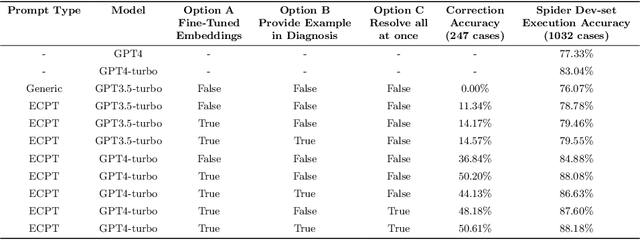
This paper introduces an Error Correction through Prompt Tuning for NL-to-SQL, leveraging the latest advancements in generative pre-training-based LLMs and RAG. Our work addresses the crucial need for efficient and accurate translation of natural language queries into SQL expressions in various settings with the growing use of natural language interfaces. We explore the evolution of NLIDBs from early rule-based systems to advanced neural network-driven approaches. Drawing inspiration from the medical diagnostic process, we propose a novel framework integrating an error correction mechanism that diagnoses error types, identifies their causes, provides fixing instructions, and applies these corrections to SQL queries. This approach is further enriched by embedding fine-tuning and RAG, which harnesses external knowledge bases for improved accuracy and transparency. Through comprehensive experiments, we demonstrate that our framework achieves a significant 12 percent accuracy improvement over existing baselines, highlighting its potential to revolutionize data access and handling in contemporary data-driven environments.
INGREX: An Interactive Explanation Framework for Graph Neural Networks
Nov 03, 2022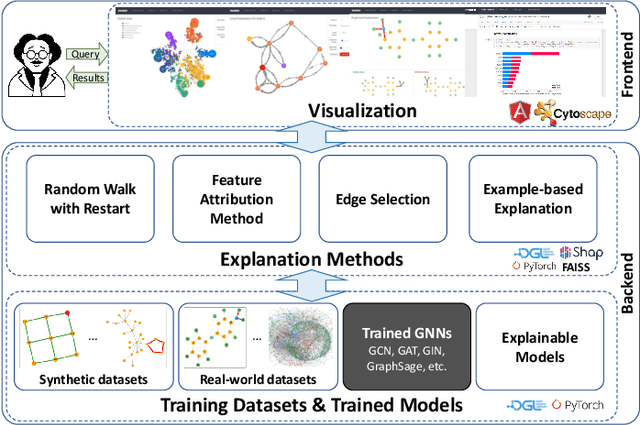
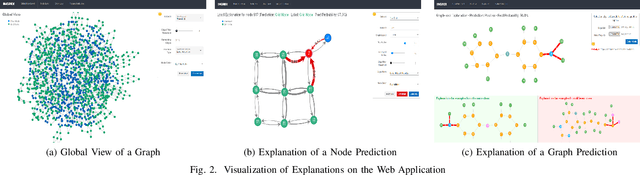
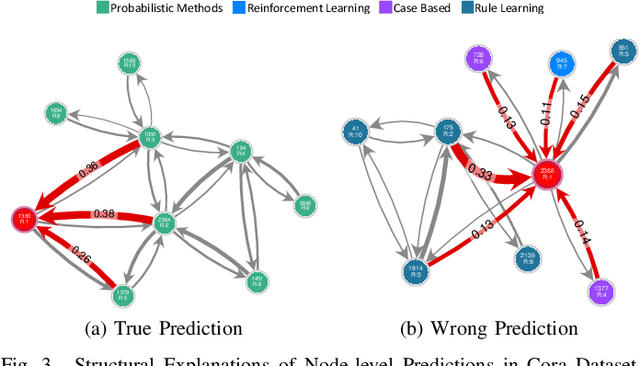
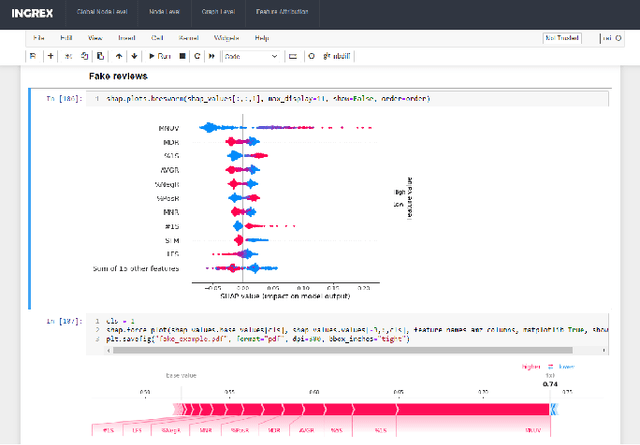
Graph Neural Networks (GNNs) are widely used in many modern applications, necessitating explanations for their decisions. However, the complexity of GNNs makes it difficult to explain predictions. Even though several methods have been proposed lately, they can only provide simple and static explanations, which are difficult for users to understand in many scenarios. Therefore, we introduce INGREX, an interactive explanation framework for GNNs designed to aid users in comprehending model predictions. Our framework is implemented based on multiple explanation algorithms and advanced libraries. We demonstrate our framework in three scenarios covering common demands for GNN explanations to present its effectiveness and helpfulness.
Towards an Error-free Deep Occupancy Detector for Smart Camera Parking System
Aug 17, 2022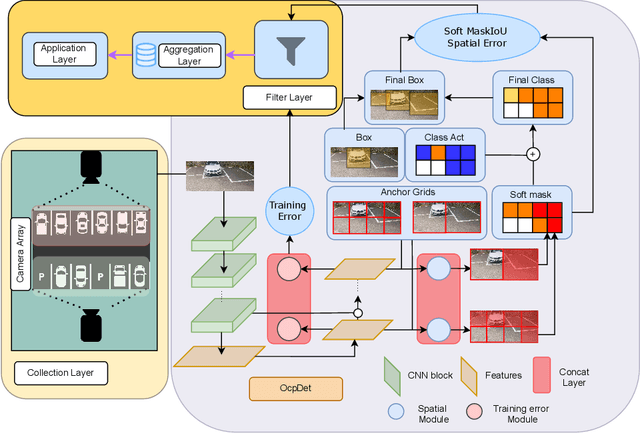


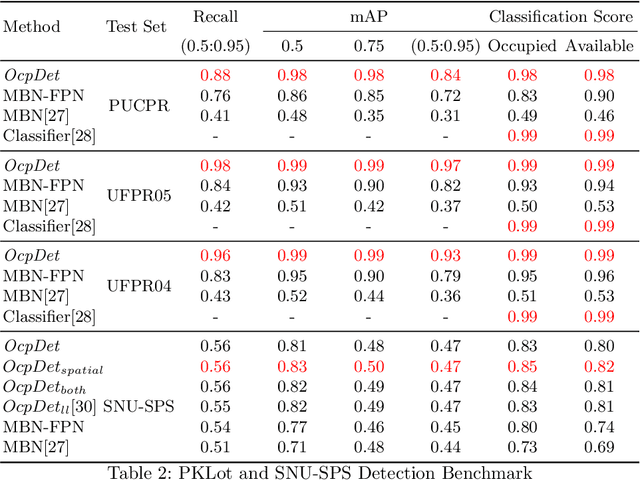
Although the smart camera parking system concept has existed for decades, a few approaches have fully addressed the system's scalability and reliability. As the cornerstone of a smart parking system is the ability to detect occupancy, traditional methods use the classification backbone to predict spots from a manual labeled grid. This is time-consuming and loses the system's scalability. Additionally, most of the approaches use deep learning models, making them not error-free and not reliable at scale. Thus, we propose an end-to-end smart camera parking system where we provide an autonomous detecting occupancy by an object detector called OcpDet. Our detector also provides meaningful information from contrastive modules: training and spatial knowledge, which avert false detections during inference. We benchmark OcpDet on the existing PKLot dataset and reach competitive results compared to traditional classification solutions. We also introduce an additional SNU-SPS dataset, in which we estimate the system performance from various views and conduct system evaluation in parking assignment tasks. The result from our dataset shows that our system is promising for real-world applications.
PGX: A Multi-level GNN Explanation Framework Based on Separate Knowledge Distillation Processes
Aug 05, 2022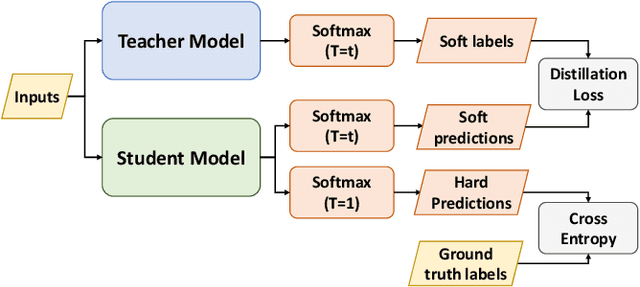
Graph Neural Networks (GNNs) are widely adopted in advanced AI systems due to their capability of representation learning on graph data. Even though GNN explanation is crucial to increase user trust in the systems, it is challenging due to the complexity of GNN execution. Lately, many works have been proposed to address some of the issues in GNN explanation. However, they lack generalization capability or suffer from computational burden when the size of graphs is enormous. To address these challenges, we propose a multi-level GNN explanation framework based on an observation that GNN is a multimodal learning process of multiple components in graph data. The complexity of the original problem is relaxed by breaking into multiple sub-parts represented as a hierarchical structure. The top-level explanation aims at specifying the contribution of each component to the model execution and predictions, while fine-grained levels focus on feature attribution and graph structure attribution analysis based on knowledge distillation. Student models are trained in standalone modes and are responsible for capturing different teacher behaviors, later used for particular component interpretation. Besides, we also aim for personalized explanations as the framework can generate different results based on user preferences. Finally, extensive experiments demonstrate the effectiveness and fidelity of our proposed approach.
Generative Pre-training for Paraphrase Generation by Representing and Predicting Spans in Exemplars
Nov 29, 2020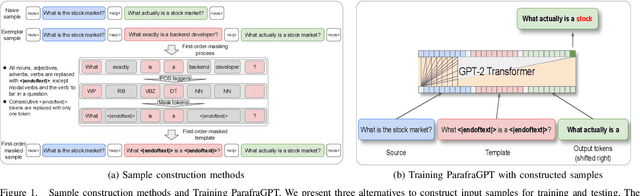
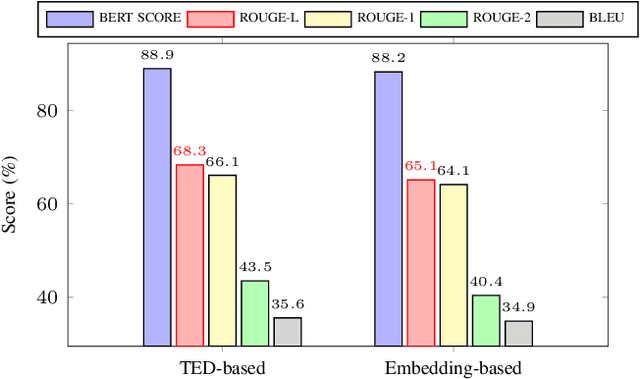
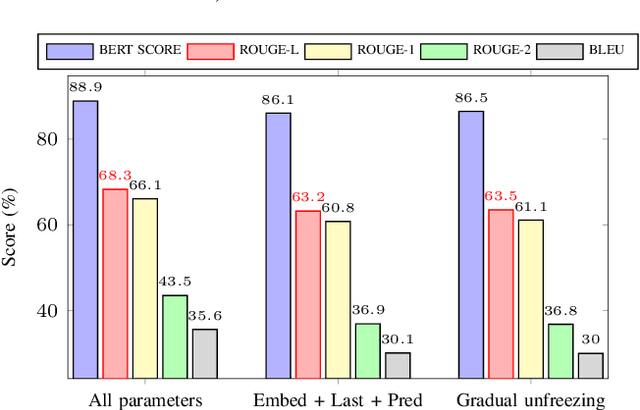
Paraphrase generation is a long-standing problem and serves an essential role in many natural language processing problems. Despite some encouraging results, recent methods either confront the problem of favoring generic utterance or need to retrain the model from scratch for each new dataset. This paper presents a novel approach to paraphrasing sentences, extended from the GPT-2 model. We develop a template masking technique, named first-order masking, to masked out irrelevant words in exemplars utilizing POS taggers. So that, the paraphrasing task is changed to predicting spans in masked templates. Our proposed approach outperforms competitive baselines, especially in the semantic preservation aspect. To prevent the model from being biased towards a given template, we introduce a technique, referred to as second-order masking, which utilizes Bernoulli distribution to control the visibility of the first-order-masked template's tokens. Moreover, this technique allows the model to provide various paraphrased sentences in testing by adjusting the second-order-masking level. For scale-up objectives, we compare the performance of two alternatives template-selection methods, which shows that they were equivalent in preserving semantic information.
An Attention-Based Speaker Naming Method for Online Adaptation in Non-Fixed Scenarios
Dec 02, 2019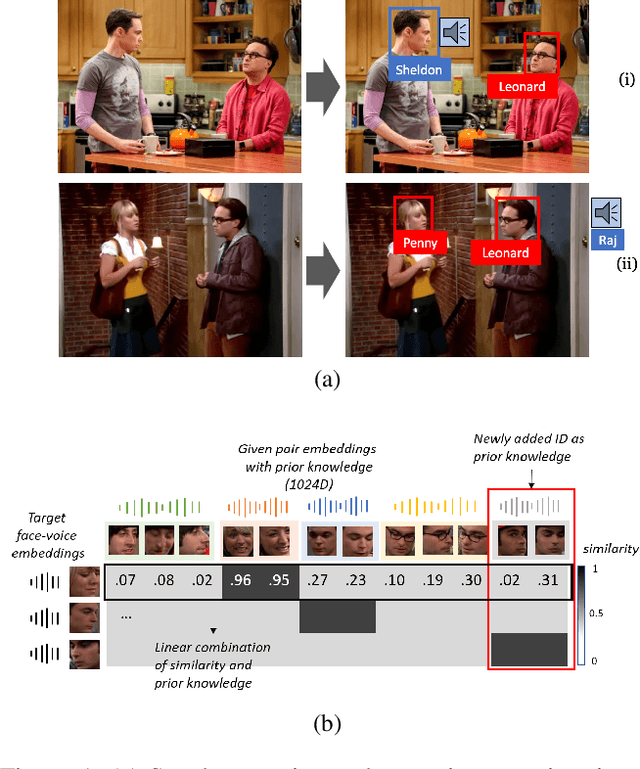
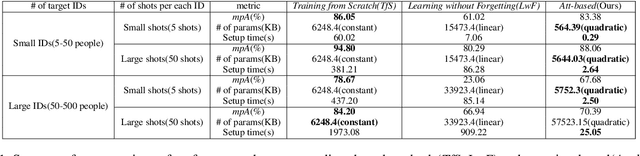
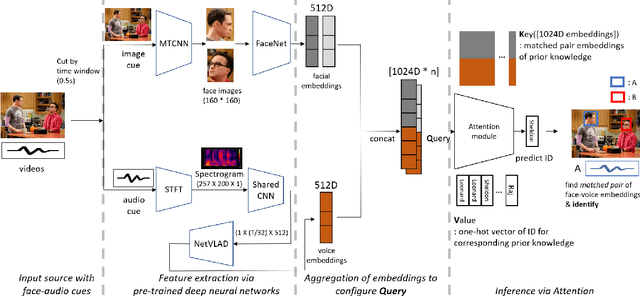

A speaker naming task, which finds and identifies the active speaker in a certain movie or drama scene, is crucial for dealing with high-level video analysis applications such as automatic subtitle labeling and video summarization. Modern approaches have usually exploited biometric features with a gradient-based method instead of rule-based algorithms. In a certain situation, however, a naive gradient-based method does not work efficiently. For example, when new characters are added to the target identification list, the neural network needs to be frequently retrained to identify new people and it causes delays in model preparation. In this paper, we present an attention-based method which reduces the model setup time by updating the newly added data via online adaptation without a gradient update process. We comparatively analyzed with three evaluation metrics(accuracy, memory usage, setup time) of the attention-based method and existing gradient-based methods under various controlled settings of speaker naming. Also, we applied existing speaker naming models and the attention-based model to real video to prove that our approach shows comparable accuracy to the existing state-of-the-art models and even higher accuracy in some cases.
Spatiotemporal deep learning model for citywide air pollution interpolation and prediction
Nov 29, 2019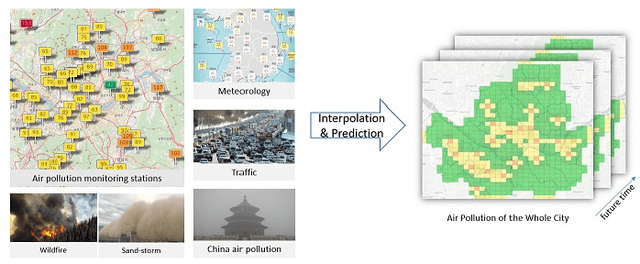
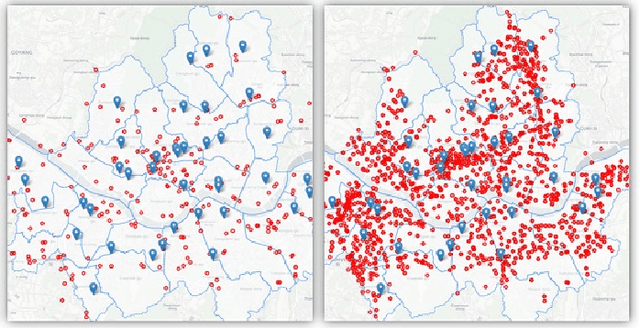
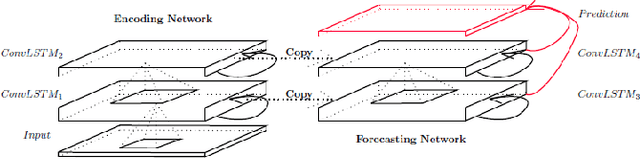
Recently, air pollution is one of the most concerns for big cities. Predicting air quality for any regions and at any time is a critical requirement of urban citizens. However, air pollution prediction for the whole city is a challenging problem. The reason is, there are many spatiotemporal factors affecting air pollution throughout the city. Collecting as many of them could help us to forecast air pollution better. In this research, we present many spatiotemporal datasets collected over Seoul city in Korea, which is currently much suffered by air pollution problem as well. These datasets include air pollution data, meteorological data, traffic volume, average driving speed, and air pollution indexes of external areas which are known to impact Seoul's air pollution. To the best of our knowledge, traffic volume and average driving speed data are two new datasets in air pollution research. In addition, recent research in air pollution has tried to build models to interpolate and predict air pollution in the city. Nevertheless, they mostly focused on predicting air quality in discrete locations or used hand-crafted spatial and temporal features. In this paper, we propose the usage of Convolutional Long Short-Term Memory (ConvLSTM) model \cite{b16}, a combination of Convolutional Neural Networks and Long Short-Term Memory, which automatically manipulates both the spatial and temporal features of the data. Specially, we introduce how to transform the air pollution data into sequences of images which leverages the using of ConvLSTM model to interpolate and predict air quality for the entire city at the same time. We prove that our approach is suitable for spatiotemporal air pollution problems and also outperforms other related research.
A Deep Learning Approach for Forecasting Air Pollution in South Korea Using LSTM
May 10, 2018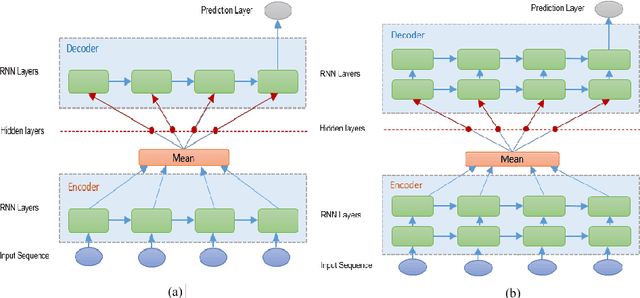
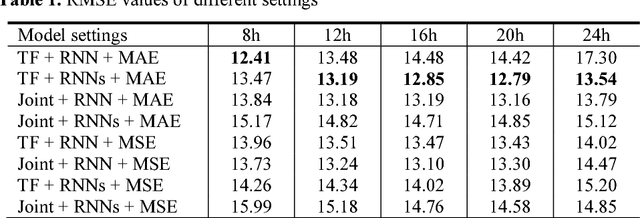
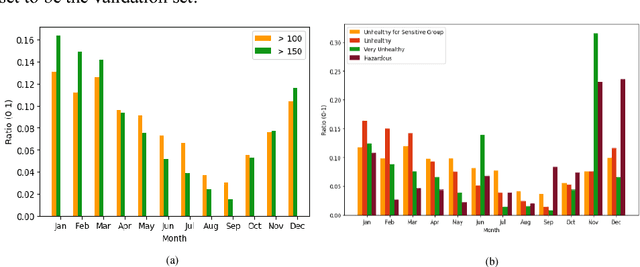
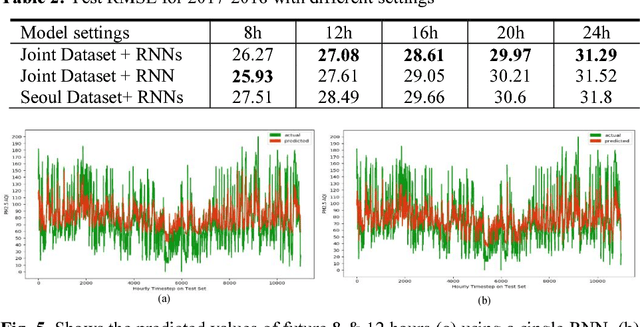
Tackling air pollution is an imperative problem in South Korea, especially in urban areas, over the last few years. More specially, South Korea has joined the ranks of the world's most polluted countries alongside with other Asian capitals, such as Beijing or Delhi. Much research is being conducted in environmental science to evaluate the dangerous impact of particulate matters on public health. Besides that, deterministic models of air pollutant behavior are also generated; however, this is both complex and often inaccurate. On the contrary, deep recurrent neural network reveals potent potential on forecasting out-comes of time-series data and has become more prevalent. This paper uses Recurrent Neural Network (RNN) with Long Short-Term Memory units as a framework for leveraging knowledge from time-series data of air pollution and meteorological information in Daegu, Seoul, Beijing, and Shenyang. Additionally, we use encoder-decoder model, which is similar to machine comprehension problems, as a crucial part of our prediction machine. Finally, we investigate the prediction accuracy of various configurations. Our experiments prevent the efficiency of integrating multiple layers of RNN on prediction model when forecasting far timesteps ahead. This research is a significant motivation for not only continuing researching on urban air quality but also help the government leverage that insight to enact beneficial policies