 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Generating Earnings Report Analysis via a Financial-Augmented LLM
Dec 11, 2024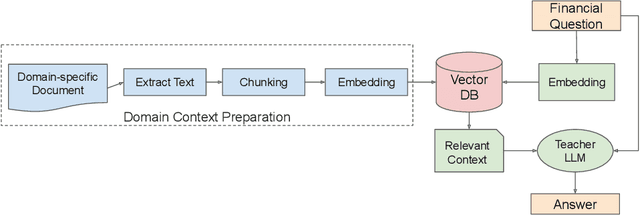
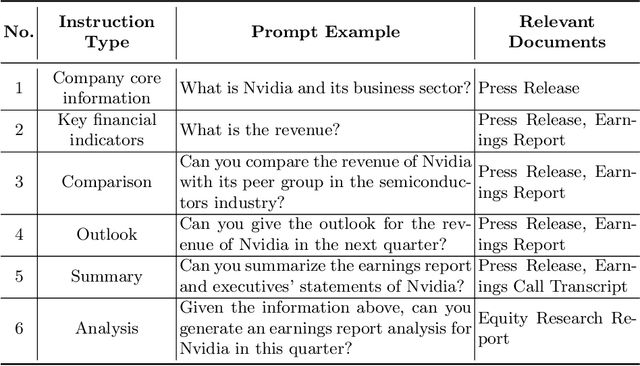


Financial analysis heavily relies on the evaluation of earnings reports to gain insights into company performance. Traditional generation of these reports requires extensive financial expertise and is time-consuming. With the impressive progress in Large Language Models (LLMs), a wide variety of financially focused LLMs has emerged, addressing tasks like sentiment analysis and entity recognition in the financial domain. This paper presents a novel challenge: developing an LLM specifically for automating the generation of earnings reports analysis. Our methodology involves an in-depth analysis of existing earnings reports followed by a unique approach to fine-tune an LLM for this purpose. This approach combines retrieval augmentation and the generation of instruction-based data, specifically tailored for the financial sector, to enhance the LLM's performance. With extensive financial documents, we construct financial instruction data, enabling the refined adaptation of our LLM to financial contexts. Preliminary results indicate that our augmented LLM outperforms general open-source models and rivals commercial counterparts like GPT-3.5 in financial applications. Our research paves the way for streamlined and insightful automation in financial report generation, marking a significant stride in the field of financial analysis.
Spatiotemporal Graph Convolutional Recurrent Neural Network Model for Citywide Air Pollution Forecasting
Apr 25, 2023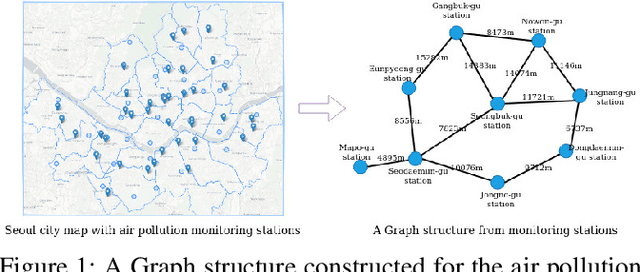
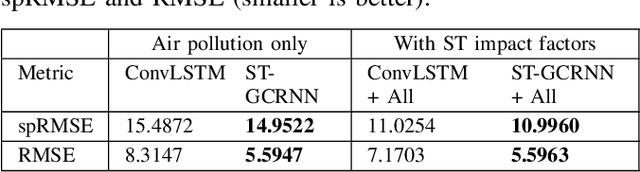
Citywide Air Pollution Forecasting tries to precisely predict the air quality multiple hours ahead for the entire city. This topic is challenged since air pollution varies in a spatiotemporal manner and depends on many complicated factors. Our previous research has solved the problem by considering the whole city as an image and leveraged a Convolutional Long Short-Term Memory (ConvLSTM) model to learn the spatiotemporal features. However, an image-based representation may not be ideal as air pollution and other impact factors have natural graph structures. In this research, we argue that a Graph Convolutional Network (GCN) can efficiently represent the spatial features of air quality readings in the whole city. Specially, we extend the ConvLSTM model to a Spatiotemporal Graph Convolutional Recurrent Neural Network (Spatiotemporal GCRNN) model by tightly integrating a GCN architecture into an RNN structure for efficient learning spatiotemporal characteristics of air quality values and their influential factors. Our extensive experiments prove the proposed model has a better performance compare to the state-of-the-art ConvLSTM model for air pollution predicting while the number of parameters is much smaller. Moreover, our approach is also superior to a hybrid GCN-based method in a real-world air pollution dataset.
VeML: An End-to-End Machine Learning Lifecycle for Large-scale and High-dimensional Data
Apr 25, 2023



An end-to-end machine learning (ML) lifecycle consists of many iterative processes, from data preparation and ML model design to model training and then deploying the trained model for inference. When building an end-to-end lifecycle for an ML problem, many ML pipelines must be designed and executed that produce a huge number of lifecycle versions. Therefore, this paper introduces VeML, a Version management system dedicated to end-to-end ML Lifecycle. Our system tackles several crucial problems that other systems have not solved. First, we address the high cost of building an ML lifecycle, especially for large-scale and high-dimensional dataset. We solve this problem by proposing to transfer the lifecycle of similar datasets managed in our system to the new training data. We design an algorithm based on the core set to compute similarity for large-scale, high-dimensional data efficiently. Another critical issue is the model accuracy degradation by the difference between training data and testing data during the ML lifetime, which leads to lifecycle rebuild. Our system helps to detect this mismatch without getting labeled data from testing data and rebuild the ML lifecycle for a new data version. To demonstrate our contributions, we conduct experiments on real-world, large-scale datasets of driving images and spatiotemporal sensor data and show promising results.
INGREX: An Interactive Explanation Framework for Graph Neural Networks
Nov 03, 2022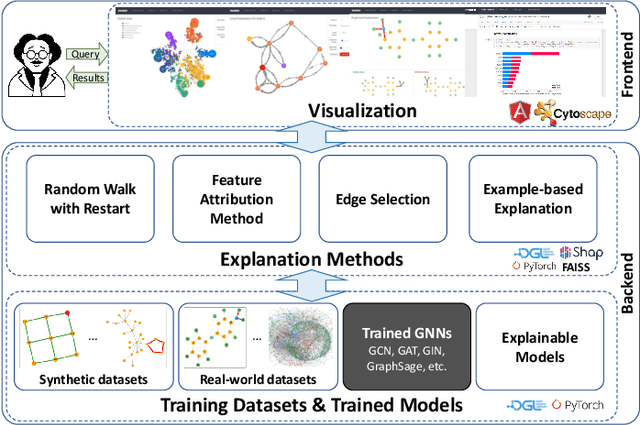
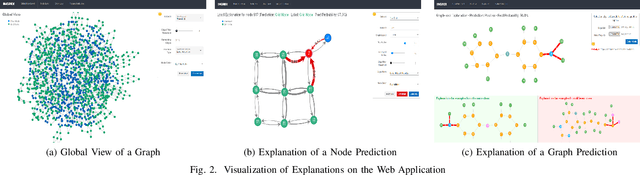
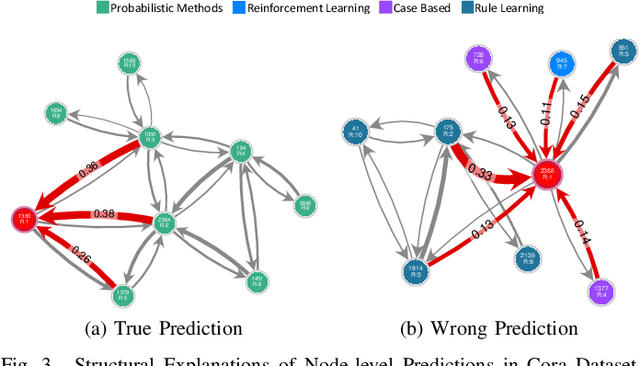
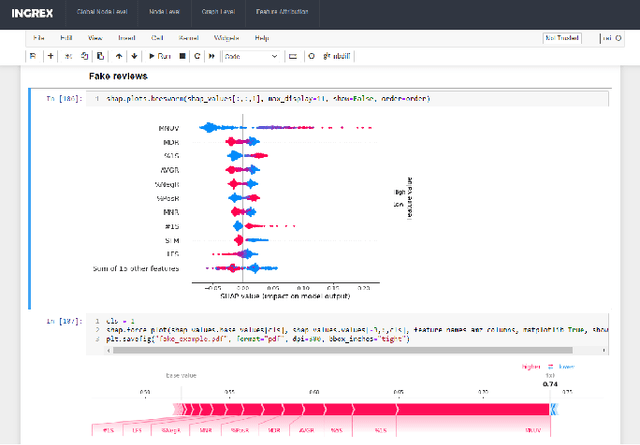
Graph Neural Networks (GNNs) are widely used in many modern applications, necessitating explanations for their decisions. However, the complexity of GNNs makes it difficult to explain predictions. Even though several methods have been proposed lately, they can only provide simple and static explanations, which are difficult for users to understand in many scenarios. Therefore, we introduce INGREX, an interactive explanation framework for GNNs designed to aid users in comprehending model predictions. Our framework is implemented based on multiple explanation algorithms and advanced libraries. We demonstrate our framework in three scenarios covering common demands for GNN explanations to present its effectiveness and helpfulness.
Towards an Error-free Deep Occupancy Detector for Smart Camera Parking System
Aug 17, 2022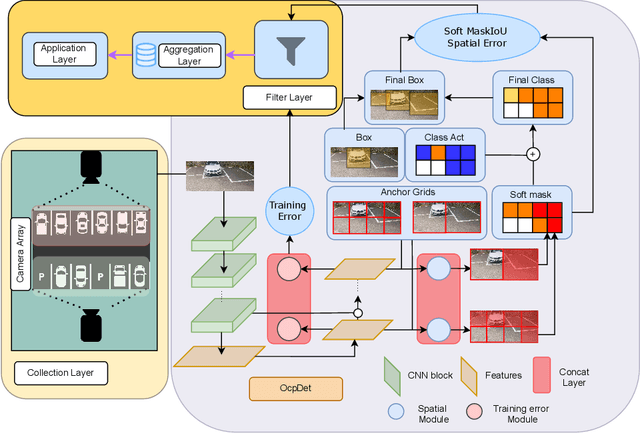


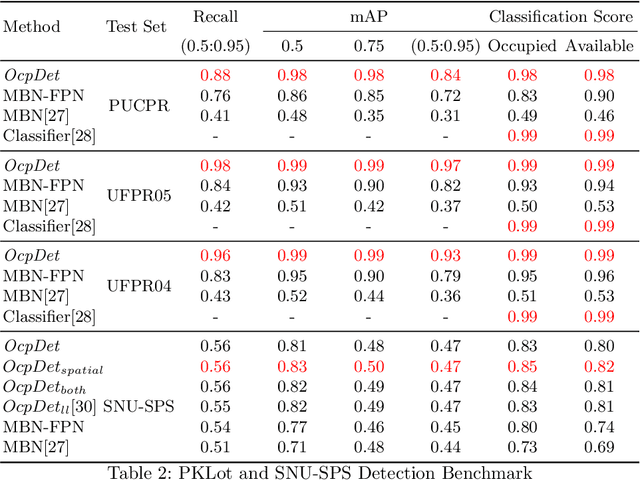
Although the smart camera parking system concept has existed for decades, a few approaches have fully addressed the system's scalability and reliability. As the cornerstone of a smart parking system is the ability to detect occupancy, traditional methods use the classification backbone to predict spots from a manual labeled grid. This is time-consuming and loses the system's scalability. Additionally, most of the approaches use deep learning models, making them not error-free and not reliable at scale. Thus, we propose an end-to-end smart camera parking system where we provide an autonomous detecting occupancy by an object detector called OcpDet. Our detector also provides meaningful information from contrastive modules: training and spatial knowledge, which avert false detections during inference. We benchmark OcpDet on the existing PKLot dataset and reach competitive results compared to traditional classification solutions. We also introduce an additional SNU-SPS dataset, in which we estimate the system performance from various views and conduct system evaluation in parking assignment tasks. The result from our dataset shows that our system is promising for real-world applications.
Generative Pre-training for Paraphrase Generation by Representing and Predicting Spans in Exemplars
Nov 29, 2020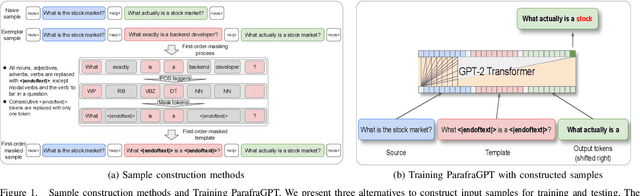
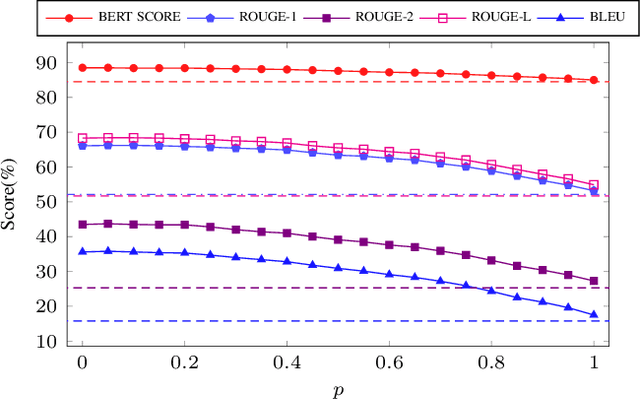
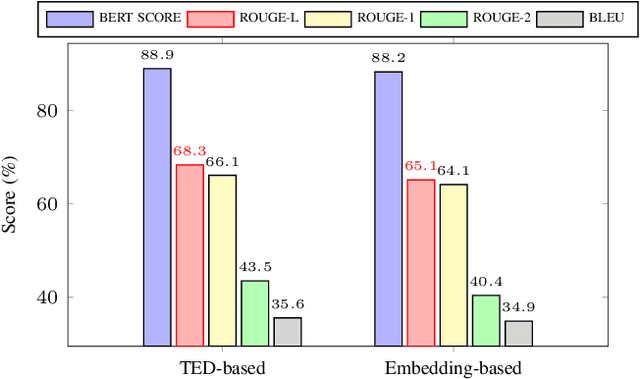
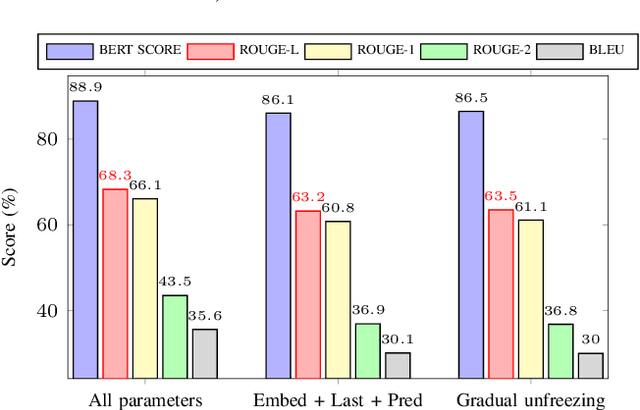
Paraphrase generation is a long-standing problem and serves an essential role in many natural language processing problems. Despite some encouraging results, recent methods either confront the problem of favoring generic utterance or need to retrain the model from scratch for each new dataset. This paper presents a novel approach to paraphrasing sentences, extended from the GPT-2 model. We develop a template masking technique, named first-order masking, to masked out irrelevant words in exemplars utilizing POS taggers. So that, the paraphrasing task is changed to predicting spans in masked templates. Our proposed approach outperforms competitive baselines, especially in the semantic preservation aspect. To prevent the model from being biased towards a given template, we introduce a technique, referred to as second-order masking, which utilizes Bernoulli distribution to control the visibility of the first-order-masked template's tokens. Moreover, this technique allows the model to provide various paraphrased sentences in testing by adjusting the second-order-masking level. For scale-up objectives, we compare the performance of two alternatives template-selection methods, which shows that they were equivalent in preserving semantic information.
Spatiotemporal deep learning model for citywide air pollution interpolation and prediction
Nov 29, 2019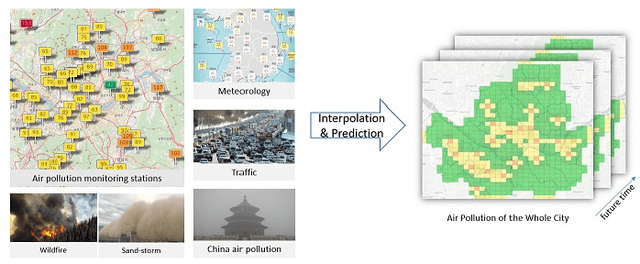
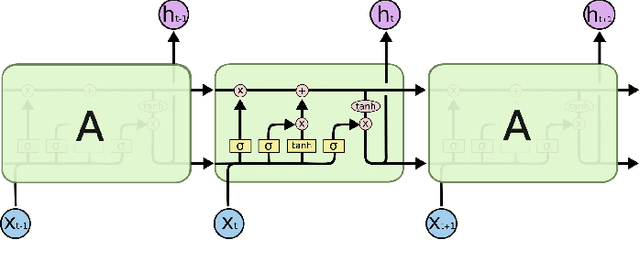
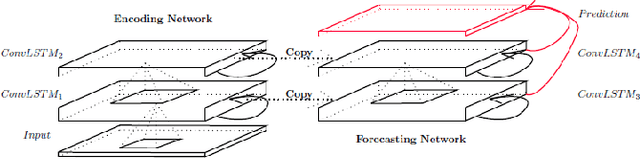
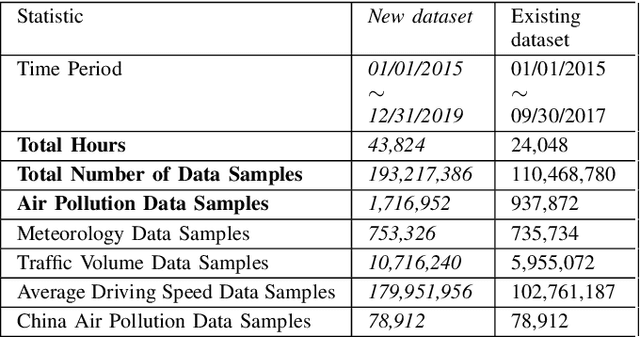
Recently, air pollution is one of the most concerns for big cities. Predicting air quality for any regions and at any time is a critical requirement of urban citizens. However, air pollution prediction for the whole city is a challenging problem. The reason is, there are many spatiotemporal factors affecting air pollution throughout the city. Collecting as many of them could help us to forecast air pollution better. In this research, we present many spatiotemporal datasets collected over Seoul city in Korea, which is currently much suffered by air pollution problem as well. These datasets include air pollution data, meteorological data, traffic volume, average driving speed, and air pollution indexes of external areas which are known to impact Seoul's air pollution. To the best of our knowledge, traffic volume and average driving speed data are two new datasets in air pollution research. In addition, recent research in air pollution has tried to build models to interpolate and predict air pollution in the city. Nevertheless, they mostly focused on predicting air quality in discrete locations or used hand-crafted spatial and temporal features. In this paper, we propose the usage of Convolutional Long Short-Term Memory (ConvLSTM) model \cite{b16}, a combination of Convolutional Neural Networks and Long Short-Term Memory, which automatically manipulates both the spatial and temporal features of the data. Specially, we introduce how to transform the air pollution data into sequences of images which leverages the using of ConvLSTM model to interpolate and predict air quality for the entire city at the same time. We prove that our approach is suitable for spatiotemporal air pollution problems and also outperforms other related research.
A Deep Learning Approach for Forecasting Air Pollution in South Korea Using LSTM
May 10, 2018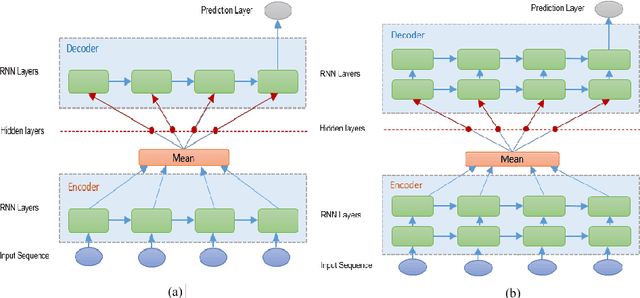
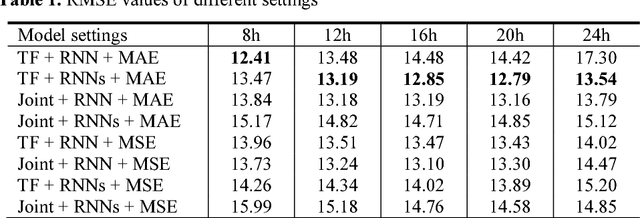
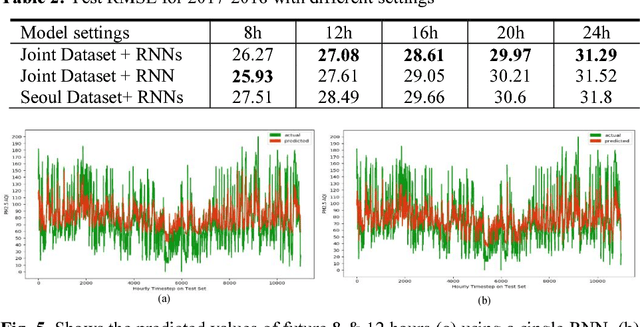
Tackling air pollution is an imperative problem in South Korea, especially in urban areas, over the last few years. More specially, South Korea has joined the ranks of the world's most polluted countries alongside with other Asian capitals, such as Beijing or Delhi. Much research is being conducted in environmental science to evaluate the dangerous impact of particulate matters on public health. Besides that, deterministic models of air pollutant behavior are also generated; however, this is both complex and often inaccurate. On the contrary, deep recurrent neural network reveals potent potential on forecasting out-comes of time-series data and has become more prevalent. This paper uses Recurrent Neural Network (RNN) with Long Short-Term Memory units as a framework for leveraging knowledge from time-series data of air pollution and meteorological information in Daegu, Seoul, Beijing, and Shenyang. Additionally, we use encoder-decoder model, which is similar to machine comprehension problems, as a crucial part of our prediction machine. Finally, we investigate the prediction accuracy of various configurations. Our experiments prevent the efficiency of integrating multiple layers of RNN on prediction model when forecasting far timesteps ahead. This research is a significant motivation for not only continuing researching on urban air quality but also help the government leverage that insight to enact beneficial policies