 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Based Speaker Naming Method for Online Adaptation in Non-Fixed Scenarios
Dec 02, 2019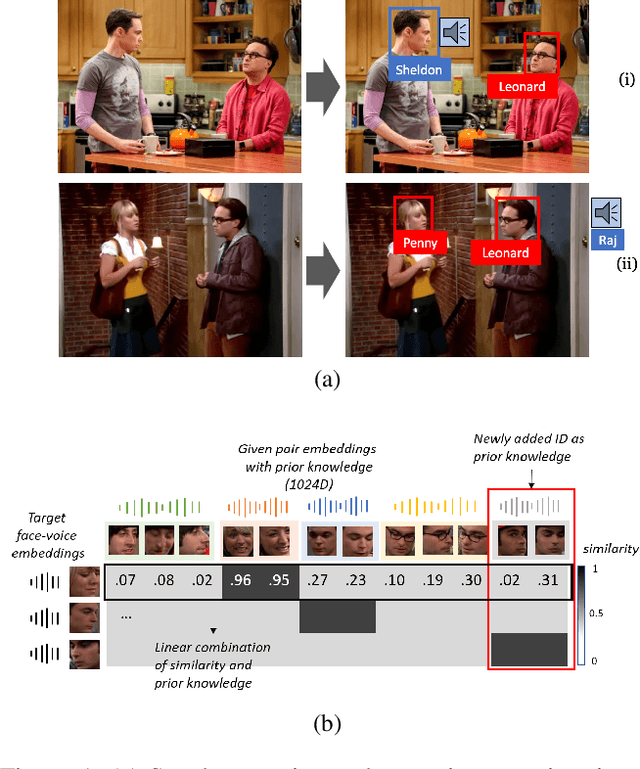
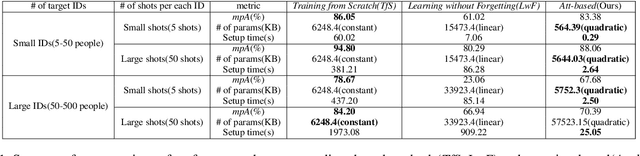
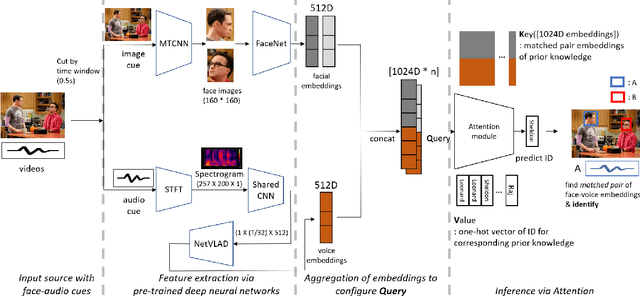

A speaker naming task, which finds and identifies the active speaker in a certain movie or drama scene, is crucial for dealing with high-level video analysis applications such as automatic subtitle labeling and video summarization. Modern approaches have usually exploited biometric features with a gradient-based method instead of rule-based algorithms. In a certain situation, however, a naive gradient-based method does not work efficiently. For example, when new characters are added to the target identification list, the neural network needs to be frequently retrained to identify new people and it causes delays in model preparation. In this paper, we present an attention-based method which reduces the model setup time by updating the newly added data via online adaptation without a gradient update process. We comparatively analyzed with three evaluation metrics(accuracy, memory usage, setup time) of the attention-based method and existing gradient-based methods under various controlled settings of speaker naming. Also, we applied existing speaker naming models and the attention-based model to real video to prove that our approach shows comparable accuracy to the existing state-of-the-art models and even higher accuracy in some cases.