 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Scene BERT: Improving object detection by searching for challenging groups of data
Feb 08, 2022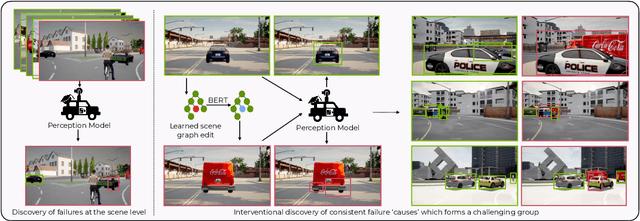
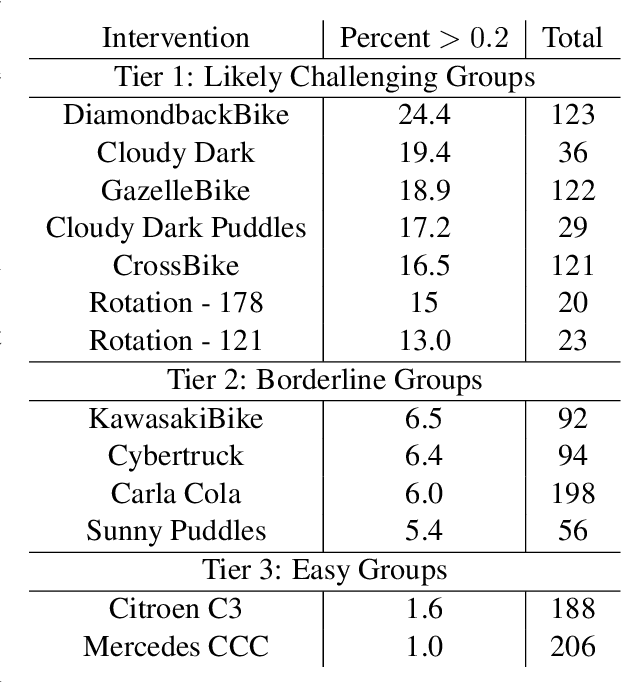
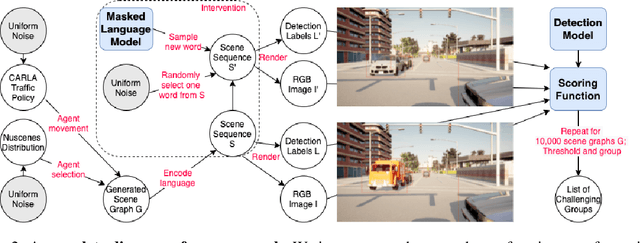
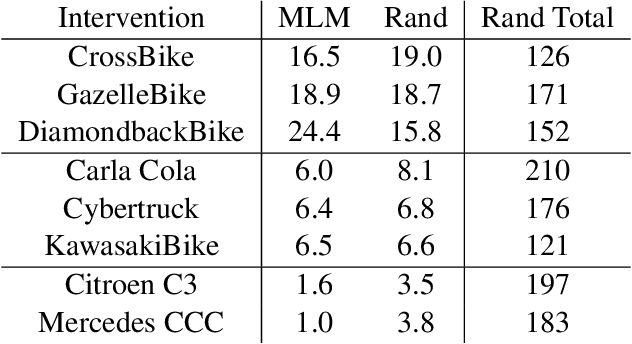
Modern computer vision applications rely on learning-based perception modules parameterized with neural networks for tasks like object detection. These modules frequently have low expected error overall but high error on atypical groups of data due to biases inherent in the training process. In building autonomous vehicles (AV), this problem is an especially important challenge because their perception modules are crucial to the overall system performance. After identifying failures in AV, a human team will comb through the associated data to group perception failures that share common causes. More data from these groups is then collected and annotated before retraining the model to fix the issue. In other words, error groups are found and addressed in hindsight. Our main contribution is a pseudo-automatic method to discover such groups in foresight by performing causal interventions on simulated scenes. To keep our interventions on the data manifold, we utilize masked language models. We verify that the prioritized groups found via intervention are challenging for the object detector and show that retraining with data collected from these groups helps inordinately compared to adding more IID data. We also plan to release software to run interventions in simulated scenes, which we hope will benefit the causality community.
Self-Supervised Equivariant Scene Synthesis from Video
Feb 01, 2021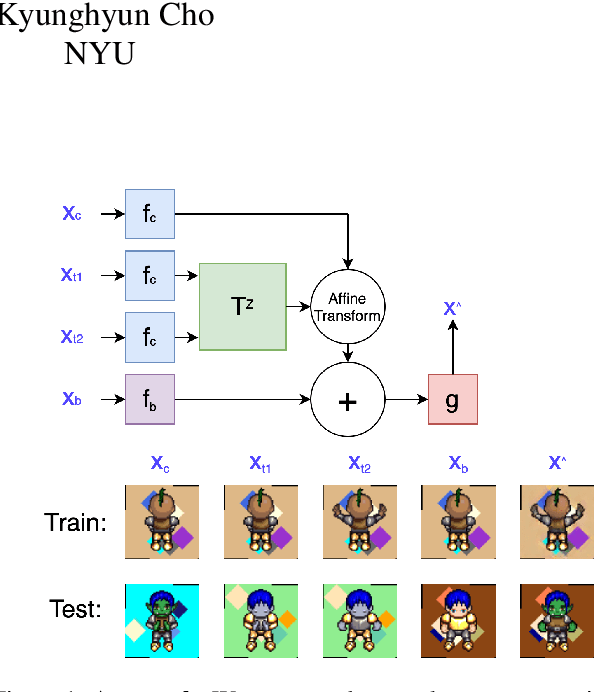
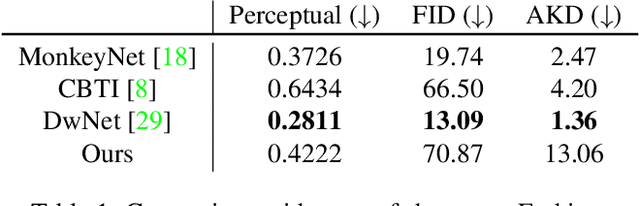
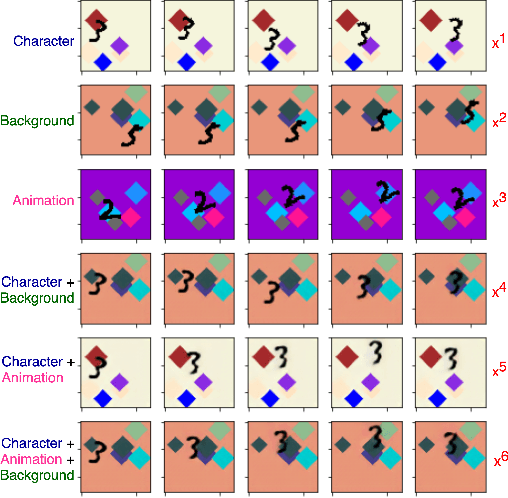
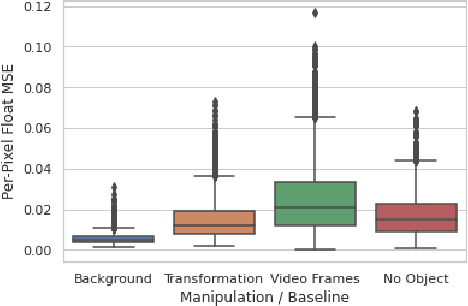
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into background, characters, and their animations. Our method capitalizes on moving characters being equivariant with respect to their transformation across frames and the background being constant with respect to that same transformation. After training, we can manipulate image encodings in real time to create unseen combinations of the delineated components. As far as we know, we are the first method to perform unsupervised extraction and synthesis of interpretable background, character, and animation. We demonstrate results on three datasets: Moving MNIST with backgrounds, 2D video game sprites, and Fashion Modeling.
Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian
Nov 12, 2020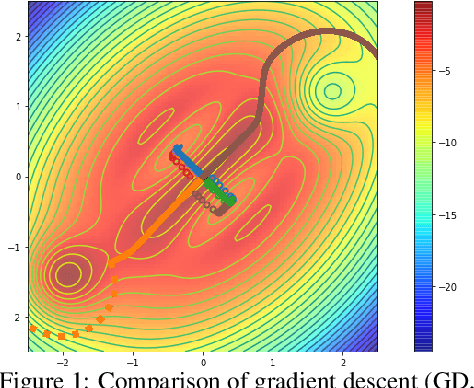
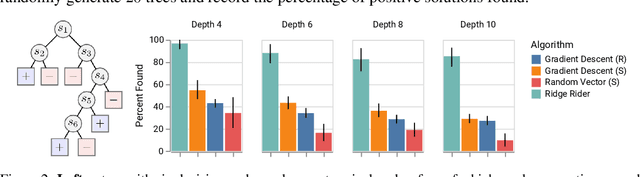
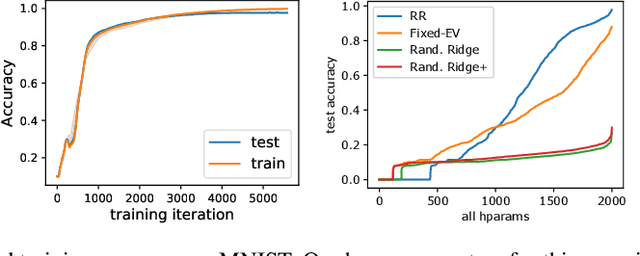
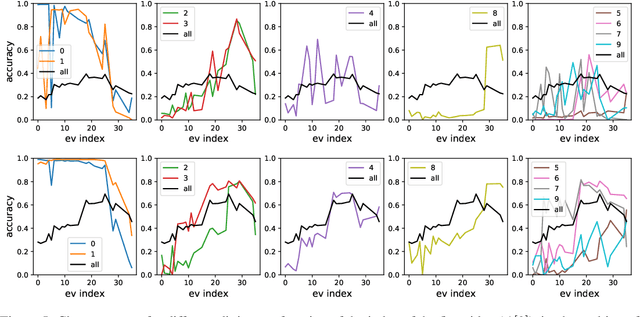
Over the last decade, a single algorithm has changed many facets of our lives - Stochastic Gradient Descent (SGD). In the era of ever decreasing loss functions, SGD and its various offspring have become the go-to optimization tool in machine learning and are a key component of the success of deep neural networks (DNNs). While SGD is guaranteed to converge to a local optimum (under loose assumptions), in some cases it may matter which local optimum is found, and this is often context-dependent. Examples frequently arise in machine learning, from shape-versus-texture-features to ensemble methods and zero-shot coordination. In these settings, there are desired solutions which SGD on 'standard' loss functions will not find, since it instead converges to the 'easy' solutions. In this paper, we present a different approach. Rather than following the gradient, which corresponds to a locally greedy direction, we instead follow the eigenvectors of the Hessian, which we call "ridges". By iteratively following and branching amongst the ridges, we effectively span the loss surface to find qualitatively different solutions. We show both theoretically and experimentally that our method, called Ridge Rider (RR), offers a promising direction for a variety of challenging problems.
Learned Equivariant Rendering without Transformation Supervision
Nov 11, 2020



We propose a self-supervised framework to learn scene representations from video that are automatically delineated into objects and background. Our method relies on moving objects being equivariant with respect to their transformation across frames and the background being constant. After training, we can manipulate and render the scenes in real time to create unseen combinations of objects, transformations, and backgrounds. We show results on moving MNIST with backgrounds.
In-Distribution Interpretability for Challenging Modalities
Jul 07, 2020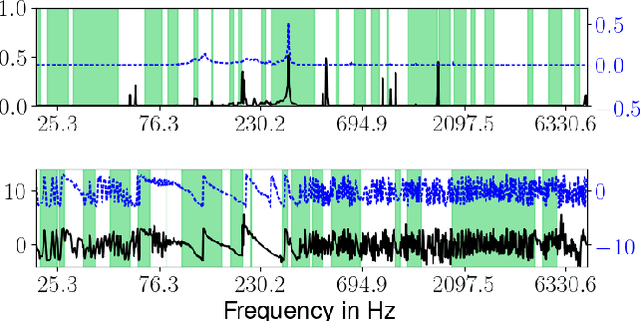
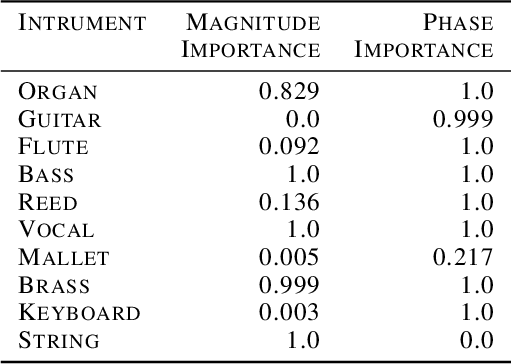
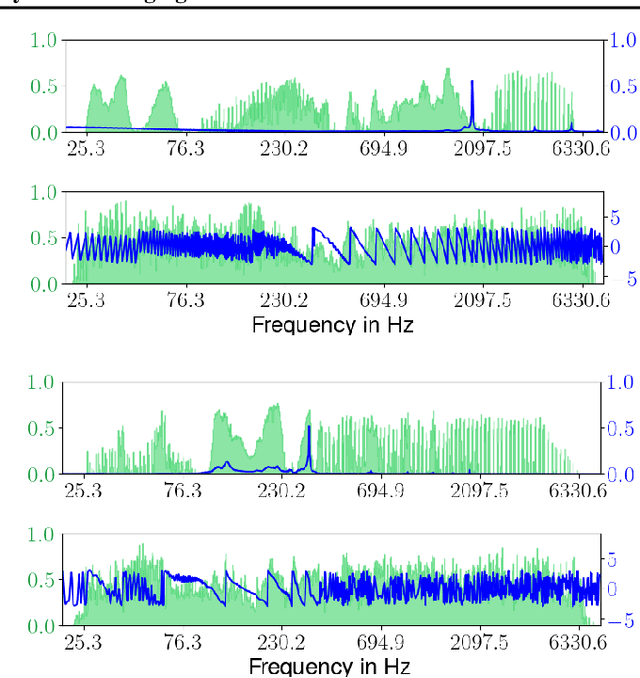
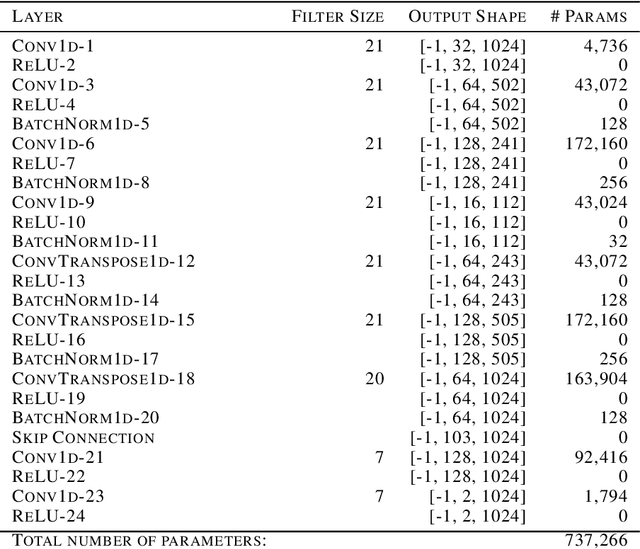
It is widely recognized that the predictions of deep neural networks are difficult to parse relative to simpler approaches. However, the development of methods to investigate the mode of operation of such models has advanced rapidly in the past few years. Recent work introduced an intuitive framework which utilizes generative models to improve on the meaningfulness of such explanations. In this work, we display the flexibility of this method to interpret diverse and challenging modalities: music and physical simulations of urban environments.
Probing the State of the Art: A Critical Look at Visual Representation Evaluation
Nov 30, 2019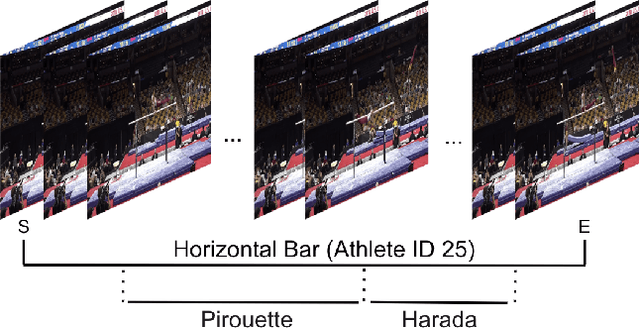
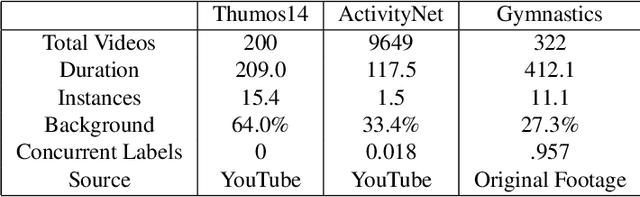
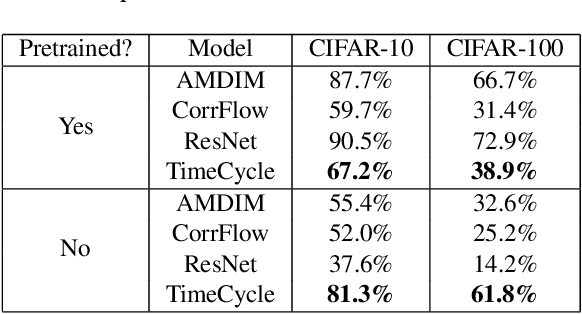
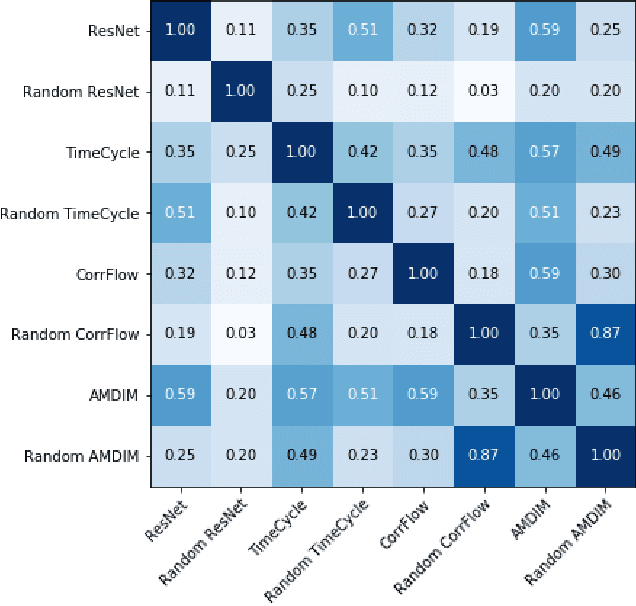
Self-supervised research improved greatly over the past half decade, with much of the growth being driven by objectives that are hard to quantitatively compare. These techniques include colorization, cyclical consistency, and noise-contrastive estimation from image patches. Consequently, the field has settled on a handful of measurements that depend on linear probes to adjudicate which approaches are the best. Our first contribution is to show that this test is insufficient and that models which perform poorly (strongly) on linear classification can perform strongly (weakly) on more involved tasks like temporal activity localization. Our second contribution is to analyze the capabilities of five different representations. And our third contribution is a much needed new dataset for temporal activity localization.
Capacity, Bandwidth, and Compositionality in Emergent Language Learning
Oct 24, 2019
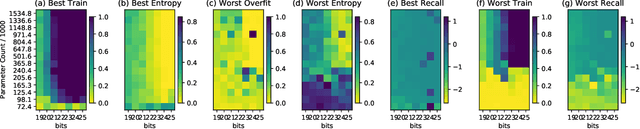
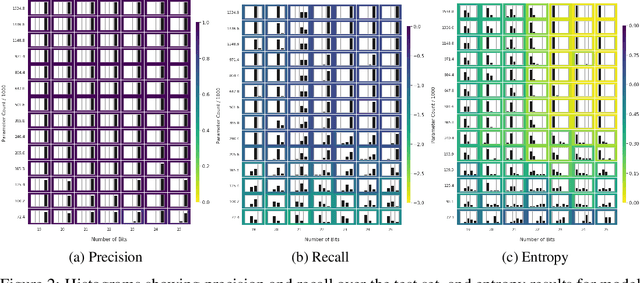
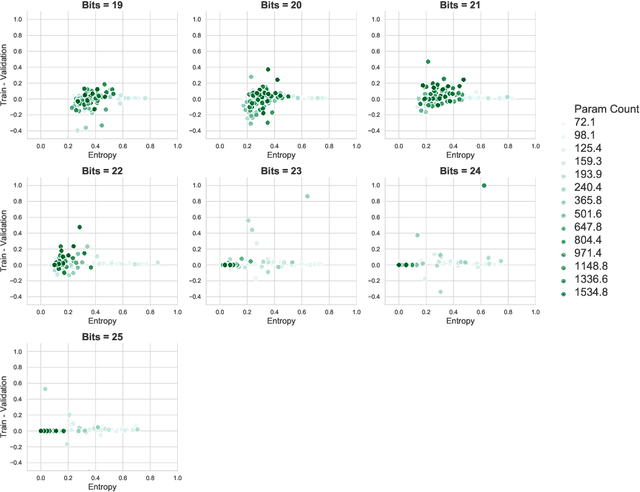
Many recent works have discussed the propensity, or lack thereof, for emergent languages to exhibit properties of natural languages. A favorite in the literature is learning compositionality. We note that most of those works have focused on communicative bandwidth as being of primary importance. While important, it is not the only contributing factor. In this paper, we investigate the learning biases that affect the efficacy and compositionality of emergent languages. Our foremost contribution is to explore how capacity of a neural network impacts its ability to learn a compositional language. We additionally introduce a set of evaluation metrics with which we analyze the learned languages. Our hypothesis is that there should be a specific range of model capacity and channel bandwidth that induces compositional structure in the resulting language and consequently encourages systematic generalization. While we empirically see evidence for the bottom of this range, we curiously do not find evidence for the top part of the range and believe that this is an open question for the community.
Backplay: "Man muss immer umkehren"
Sep 28, 2018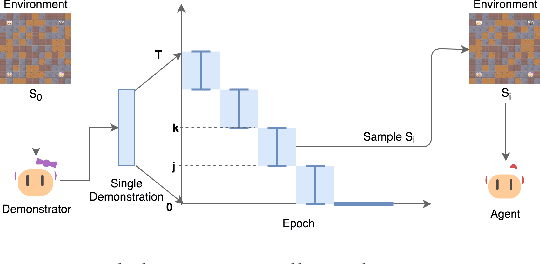
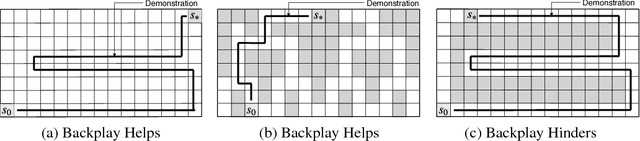
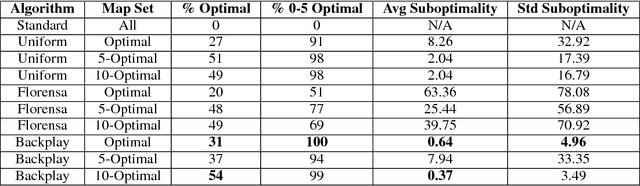
A long-standing problem in model-free reinforcement learning (RL) is that it requires a large number of trials to learn a good policy, especially in environments with sparse rewards. We explore a method to increase the sample efficiency of RL when we have access to demonstrations. Our approach, Backplay, uses a single demonstration to construct a curriculum for a given task. Rather than starting each training episode in the environment's fixed initial state, we start the agent near the end of the demonstration and move the starting point backwards during the course of training until we reach the initial state. We perform experiments in a competitive four-player game (Pommerman) and a path-finding maze game. We find that Backplay provides significant gains in sample complexity with a stark advantage in sparse reward settings. In some cases, it reached success rates greater than 50 and generalized to unseen initial conditions, while standard RL did not yield any improvement.
Vehicle Communication Strategies for Simulated Highway Driving
Aug 14, 2018

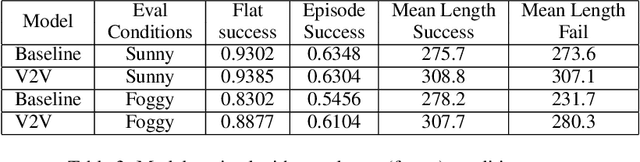
Interest in emergent communication has recently surged in Machine Learning. The focus of this interest has largely been either on investigating the properties of the learned protocol or on utilizing emergent communication to better solve problems that already have a viable solution. Here, we consider self-driving cars coordinating with each other and focus on how communication influences the agents' collective behavior. Our main result is that communication helps (most) with adverse conditions.
Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders
Apr 05, 2017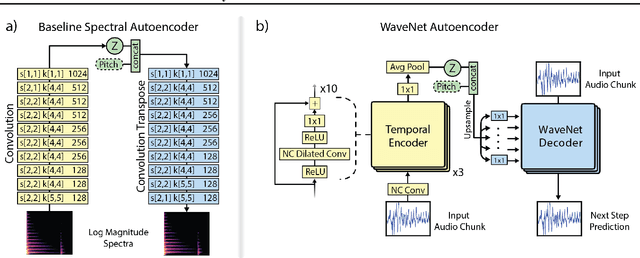
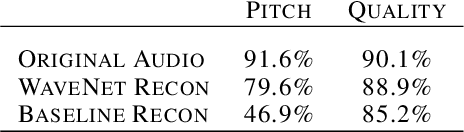


Generative models in vision have seen rapid progress due to algorithmic improvements and the availability of high-quality image datasets. In this paper, we offer contributions in both these areas to enable similar progress in audio modeling. First, we detail a powerful new WaveNet-style autoencoder model that conditions an autoregressive decoder on temporal codes learned from the raw audio waveform. Second, we introduce NSynth, a large-scale and high-quality dataset of musical notes that is an order of magnitude larger than comparable public datasets. Using NSynth, we demonstrate improved qualitative and quantitative performance of the WaveNet autoencoder over a well-tuned spectral autoencoder baseline. Finally, we show that the model learns a manifold of embeddings that allows for morphing between instruments, meaningfully interpolating in timbre to create new types of sounds that are realistic and expressive.