 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the State of the Art: A Critical Look at Visual Representation Evaluation
Nov 30, 2019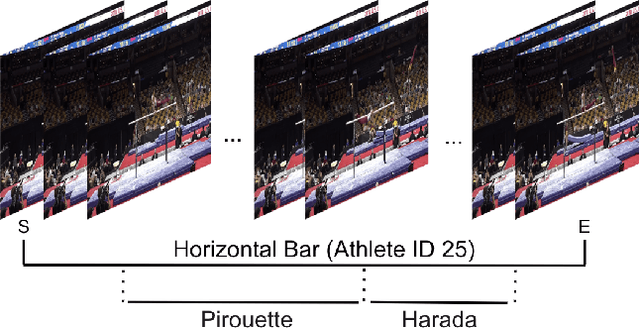
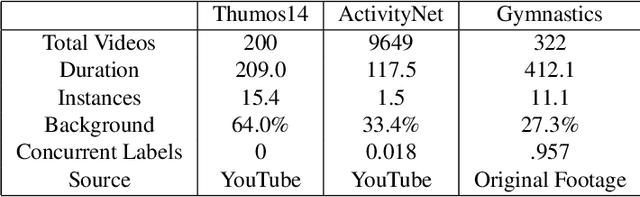
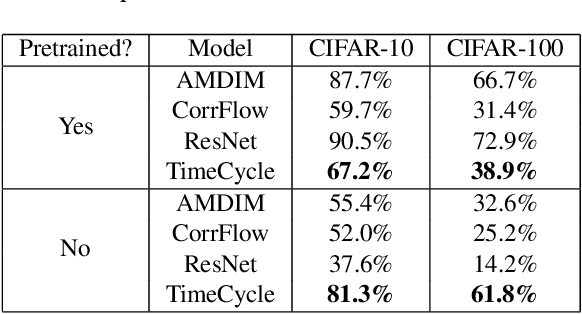
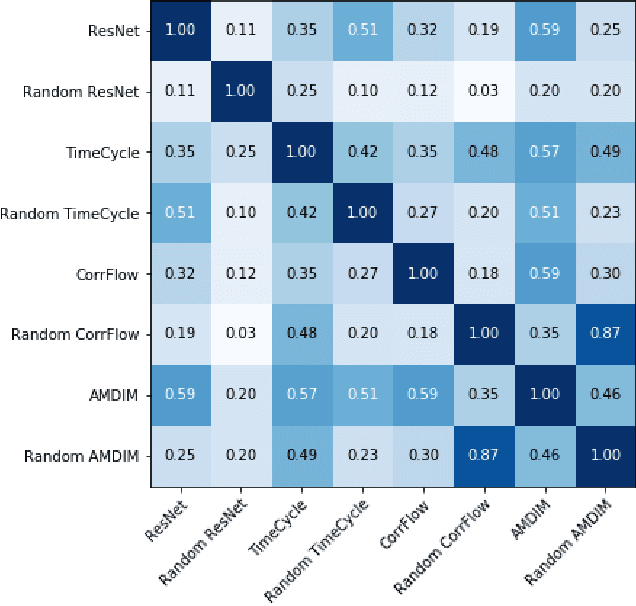
Self-supervised research improved greatly over the past half decade, with much of the growth being driven by objectives that are hard to quantitatively compare. These techniques include colorization, cyclical consistency, and noise-contrastive estimation from image patches. Consequently, the field has settled on a handful of measurements that depend on linear probes to adjudicate which approaches are the best. Our first contribution is to show that this test is insufficient and that models which perform poorly (strongly) on linear classification can perform strongly (weakly) on more involved tasks like temporal activity localization. Our second contribution is to analyze the capabilities of five different representations. And our third contribution is a much needed new dataset for temporal activity localization.
Taking the Scenic Route: Automatic Exploration for Videogames
Dec 07, 2018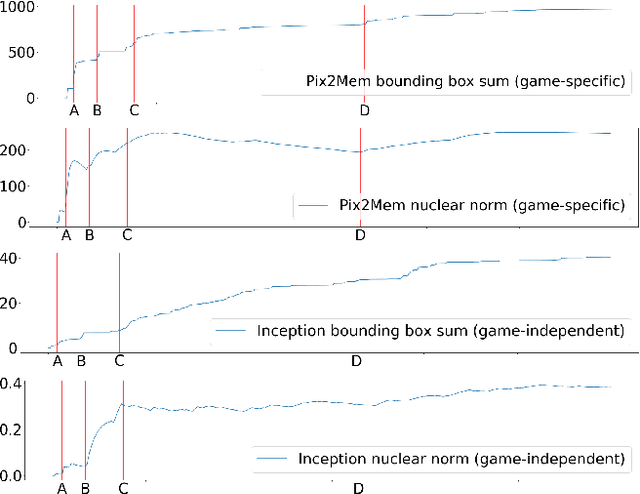
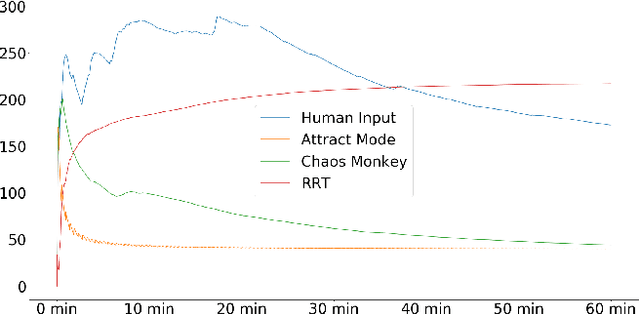
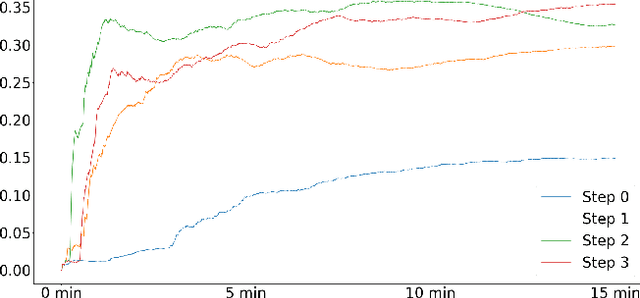
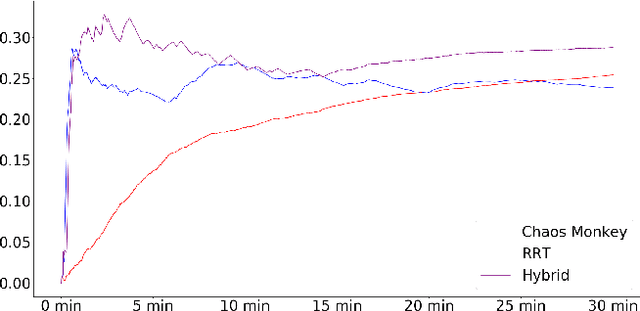
Machine playtesting tools and game moment search engines require exposure to the diversity of a game's state space if they are to report on or index the most interesting moments of possible play. Meanwhile, mobile app distribution services would like to quickly determine if a freshly-uploaded game is fit to be published. Having access to a semantic map of reachable states in the game would enable efficient inference in these applications. However, human gameplay data is expensive to acquire relative to the coverage of a game that it provides. We show that off-the-shelf automatic exploration strategies can explore with an effectiveness comparable to human gameplay on the same timescale. We contribute generic methods for quantifying exploration quality as a function of time and demonstrate our metric on several elementary techniques and human players on a collection of commercial games sampled from multiple game platforms (from Atari 2600 to Nintendo 64). Emphasizing the diversity of states reached and the semantic map extracted, this work makes productive contrast with the focus on finding a behavior policy or optimizing game score used in most automatic game playing research.