 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the State of the Art: A Critical Look at Visual Representation Evaluation
Paper and Code
Nov 30, 2019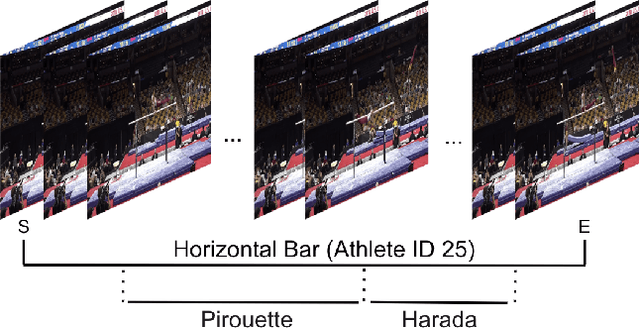
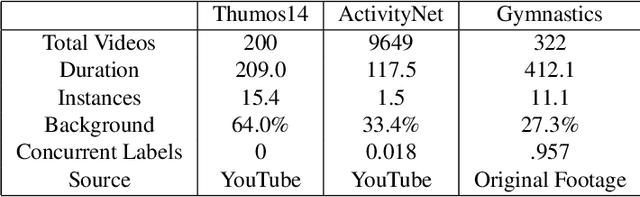
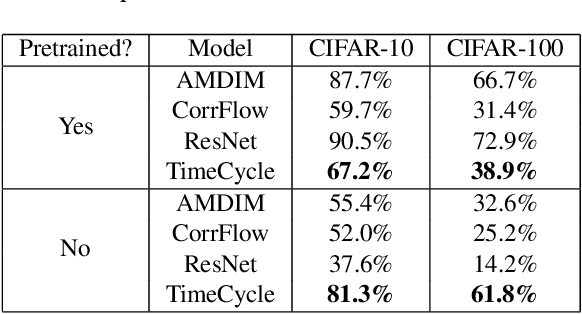
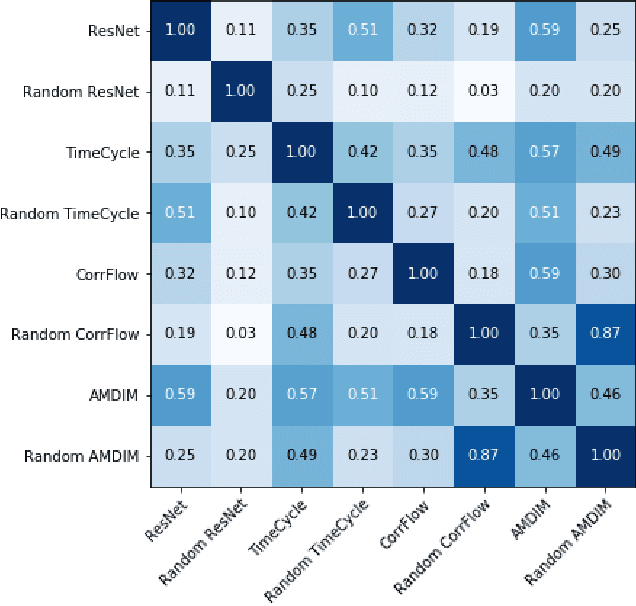
Self-supervised research improved greatly over the past half decade, with much of the growth being driven by objectives that are hard to quantitatively compare. These techniques include colorization, cyclical consistency, and noise-contrastive estimation from image patches. Consequently, the field has settled on a handful of measurements that depend on linear probes to adjudicate which approaches are the best. Our first contribution is to show that this test is insufficient and that models which perform poorly (strongly) on linear classification can perform strongly (weakly) on more involved tasks like temporal activity localization. Our second contribution is to analyze the capabilities of five different representations. And our third contribution is a much needed new dataset for temporal activity localization.