 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows
Jul 27, 2021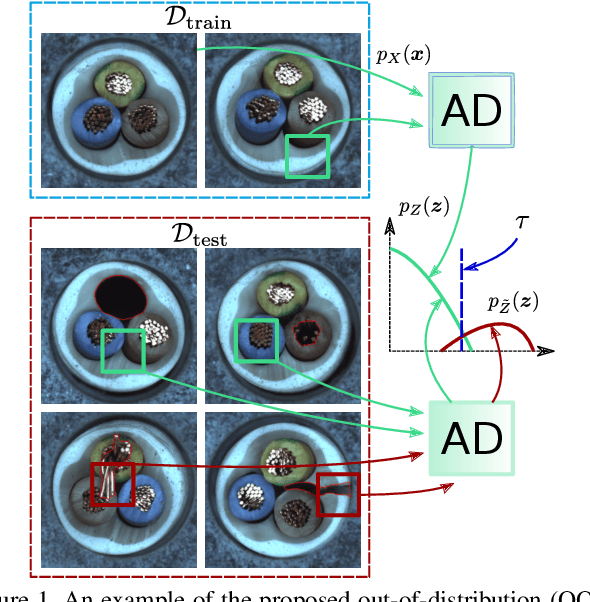
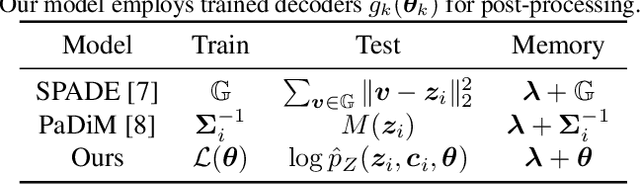
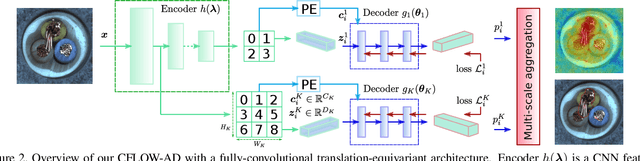
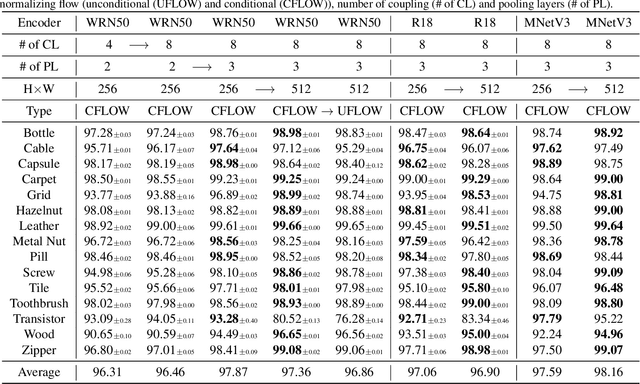
Unsupervised anomaly detection with localization has many practical applications when labeling is infeasible and, moreover, when anomaly examples are completely missing in the train data. While recently proposed models for such data setup achieve high accuracy metrics, their complexity is a limiting factor for real-time processing. In this paper, we propose a real-time model and analytically derive its relationship to prior methods. Our CFLOW-AD model is based on a conditional normalizing flow framework adopted for anomaly detection with localization. In particular, CFLOW-AD consists of a discriminatively pretrained encoder followed by a multi-scale generative decoders where the latter explicitly estimate likelihood of the encoded features. Our approach results in a computationally and memory-efficient model: CFLOW-AD is faster and smaller by a factor of 10x than prior state-of-the-art with the same input setting. Our experiments on the MVTec dataset show that CFLOW-AD outperforms previous methods by 0.36% AUROC in detection task, by 1.12% AUROC and 2.5% AUPRO in localization task, respectively. We open-source our code with fully reproducible experiments.
Home Action Genome: Cooperative Compositional Action Understanding
May 11, 2021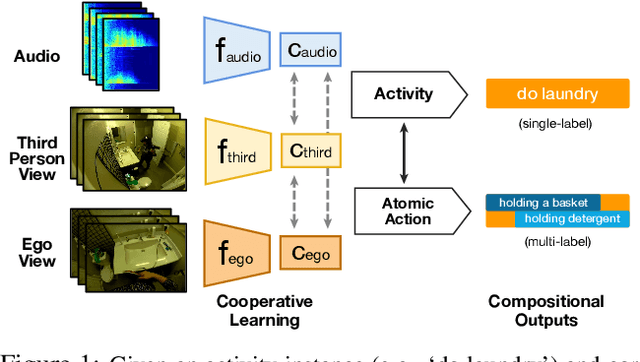
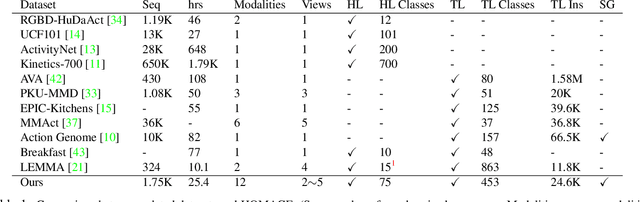


Existing research on action recognition treats activities as monolithic events occurring in videos. Recently, the benefits of formulating actions as a combination of atomic-actions have shown promise in improving action understanding with the emergence of datasets containing such annotations, allowing us to learn representations capturing this information. However, there remains a lack of studies that extend action composition and leverage multiple viewpoints and multiple modalities of data for representation learning. To promote research in this direction, we introduce Home Action Genome (HOMAGE): a multi-view action dataset with multiple modalities and view-points supplemented with hierarchical activity and atomic action labels together with dense scene composition labels. Leveraging rich multi-modal and multi-view settings, we propose Cooperative Compositional Action Understanding (CCAU), a cooperative learning framework for hierarchical action recognition that is aware of compositional action elements. CCAU shows consistent performance improvements across all modalities. Furthermore, we demonstrate the utility of co-learning compositions in few-shot action recognition by achieving 28.6% mAP with just a single sample.
AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 11, 2021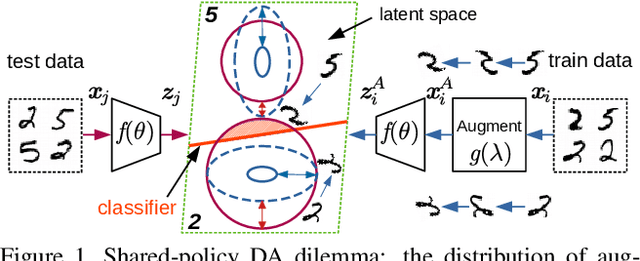
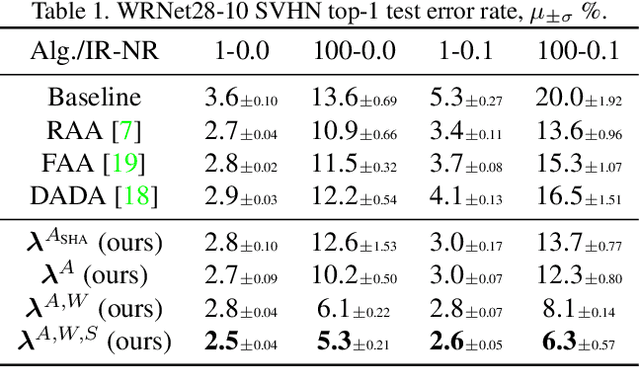


AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.