 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Policy Adaptation via Weight-Space Meta-Learning
Jun 05, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for robotic manipulation, enabling general-purpose policies trained from large corpora of demonstrations and action labels. However, adapting these models to new tasks still typically requires task-specific demonstrations, action annotations, and additional fine-tuning, making deployment costly and difficult to scale. We propose WIZARD, a weight-space meta-learning framework that sidesteps task-specific fine-tuning by generating task-specific LoRA parameters for a frozen VLA policy. Given only a language instruction and a short demonstration video, WIZARD predicts the corresponding adaptation weights in a single forward pass, without target-task action labels or test-time optimization. During meta-training, WIZARD learns to map task evidence directly to expert LoRA updates, capturing relationships between tasks in weight space. Experiments on LIBERO show that WIZARD improves performance by up to ~2x on unseen dataset collections and up to ~14x on unseen tasks. On a Franka Emika Panda, WIZARD consistently improves over a real-domain adapted baseline, showing that generated adapters provide task-level specialization beyond simulation.
Contrastive Neural Processes for Self-Supervised Learning
Oct 31, 2021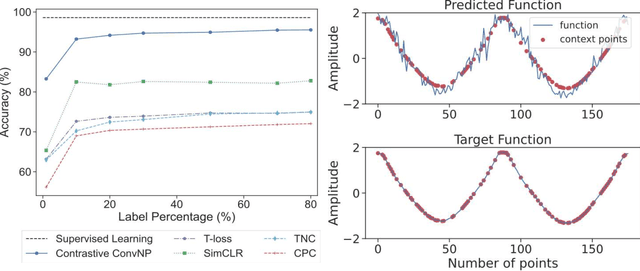
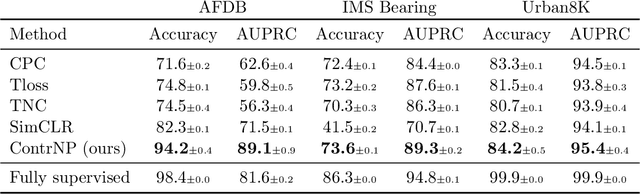
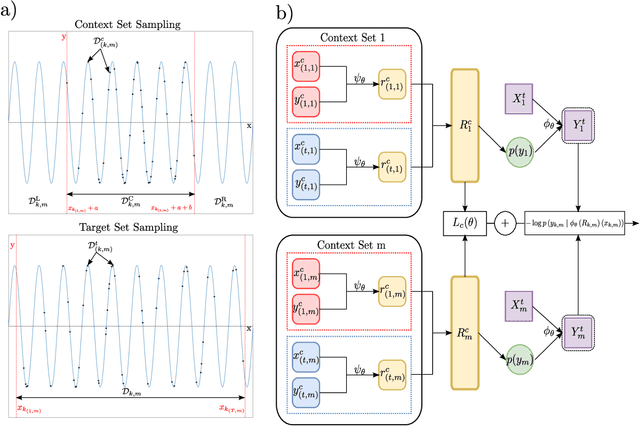
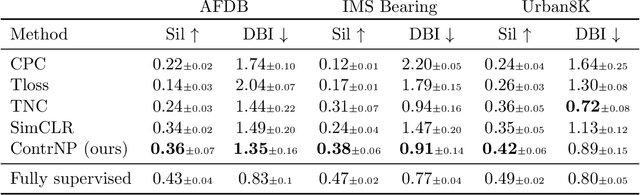
Recent contrastive methods show significant improvement in self-supervised learning in several domains. In particular, contrastive methods are most effective where data augmentation can be easily constructed e.g. in computer vision. However, they are less successful in domains without established data transformations such as time series data. In this paper, we propose a novel self-supervised learning framework that combines contrastive learning with neural processes. It relies on recent advances in neural processes to perform time series forecasting. This allows to generate augmented versions of data by employing a set of various sampling functions and, hence, avoid manually designed augmentations. We extend conventional neural processes and propose a new contrastive loss to learn times series representations in a self-supervised setup. Therefore, unlike previous self-supervised methods, our augmentation pipeline is task-agnostic, enabling our method to perform well across various applications. In particular, a ResNet with a linear classifier trained using our approach is able to outperform state-of-the-art techniques across industrial, medical and audio datasets improving accuracy over 10% in ECG periodic data. We further demonstrate that our self-supervised representations are more efficient in the latent space, improving multiple clustering indexes and that fine-tuning our method on 10% of labels achieves results competitive to fully-supervised learning.
AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 11, 2021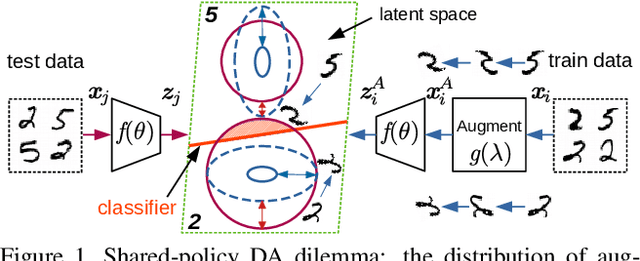
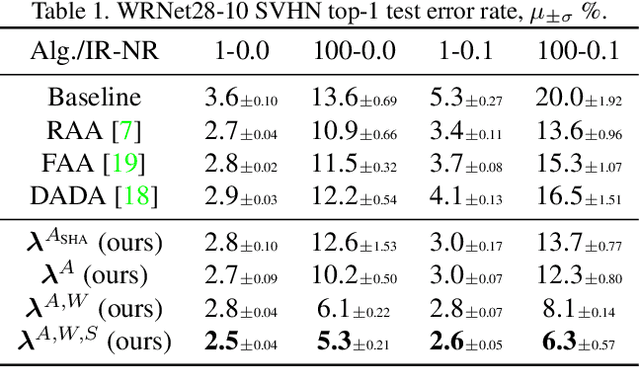


AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.
DoorGym: A Scalable Door Opening Environment And Baseline Agent
Aug 07, 2019
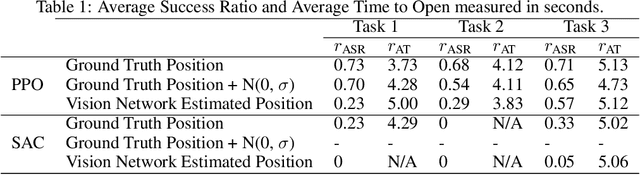

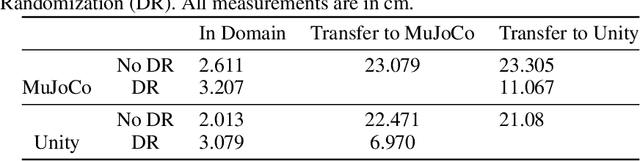
Reinforcement Learning (RL) has brought forth ideas of autonomous robots that can navigate real-world environments with ease, aiding humans in a variety of tasks. RL agents have just begun to make their way out of simulation into the real world. Once in the real world, benchmark tasks often fail to transfer into useful skills. We introduce DoorGym, a simulation environment intended to be the first step to move RL from toy environments towards useful atomic skills that can be composed and extended towards a broader goal. DoorGym is an open-source door simulation framework designed to be highly configurable. We also provide a baseline PPO (Proximal Policy Optimization) and SAC (Soft Actor-Critic)implementation, which achieves a success rate of up to 70% for common tasks in this environment. Environment kit available here:https://github.com/PSVL/DoorGym/
DNN Feature Map Compression using Learned Representation over GF(2)
Aug 15, 2018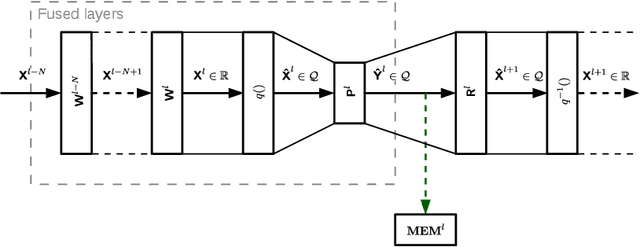
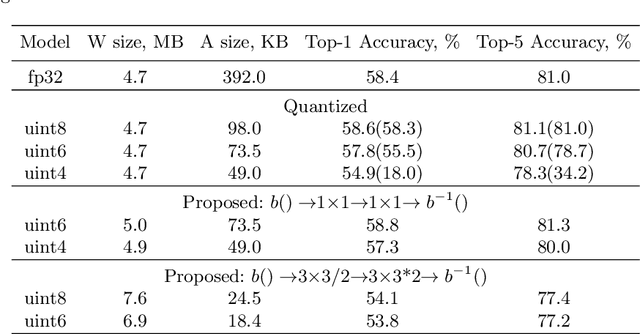
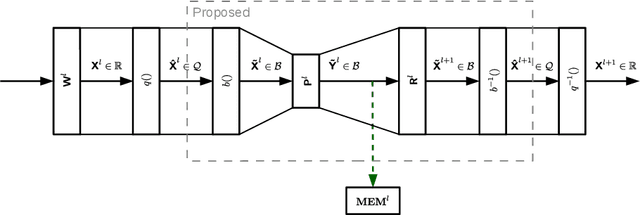
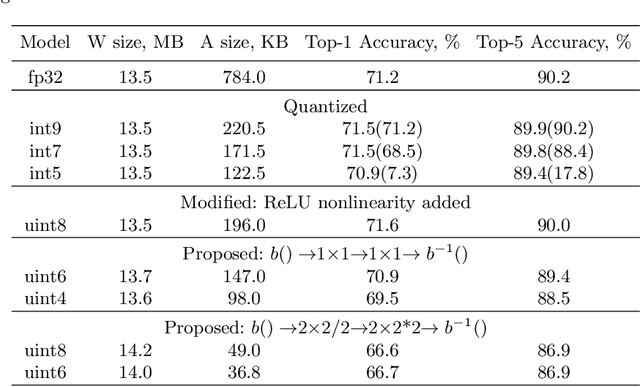
In this paper, we introduce a method to compress intermediate feature maps of deep neural networks (DNNs) to decrease memory storage and bandwidth requirements during inference. Unlike previous works, the proposed method is based on converting fixed-point activations into vectors over the smallest GF(2) finite field followed by nonlinear dimensionality reduction (NDR) layers embedded into a DNN. Such an end-to-end learned representation finds more compact feature maps by exploiting quantization redundancies within the fixed-point activations along the channel or spatial dimensions. We apply the proposed network architectures derived from modified SqueezeNet and MobileNetV2 to the tasks of ImageNet classification and PASCAL VOC object detection. Compared to prior approaches, the conducted experiments show a factor of 2 decrease in memory requirements with minor degradation in accuracy while adding only bitwise computations.
TransFlow: Unsupervised Motion Flow by Joint Geometric and Pixel-level Estimation
Oct 30, 2017
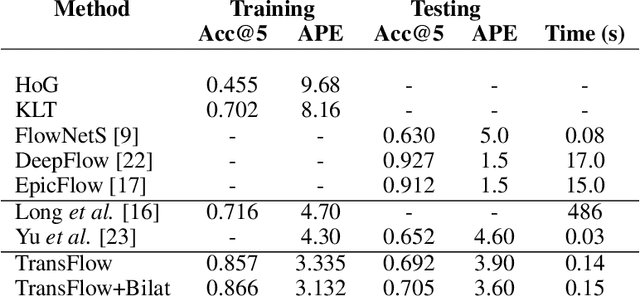
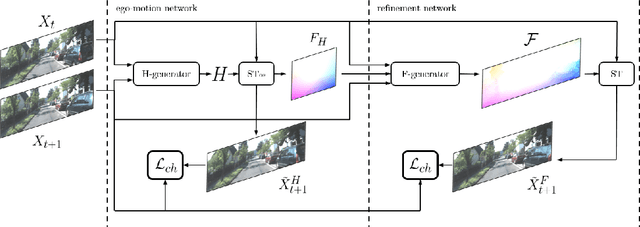

We address unsupervised optical flow estimation for ego-centric motion. We argue that optical flow can be cast as a geometrical warping between two successive video frames and devise a deep architecture to estimate such transformation in two stages. First, a dense pixel-level flow is computed with a geometric prior imposing strong spatial constraints. Such prior is typical of driving scenes, where the point of view is coherent with the vehicle motion. We show how such global transformation can be approximated with an homography and how spatial transformer layers can be employed to compute the flow field implied by such transformation. The second stage then refines the prediction feeding a second deeper network. A final reconstruction loss compares the warping of frame X(t) with the subsequent frame X(t+1) and guides both estimates. The model, which we named TransFlow, performs favorably compared to other unsupervised algorithms, and shows better generalization compared to supervised methods with a 3x reduction in error on unseen data.
Path Integral Networks: End-to-End Differentiable Optimal Control
Jun 29, 2017
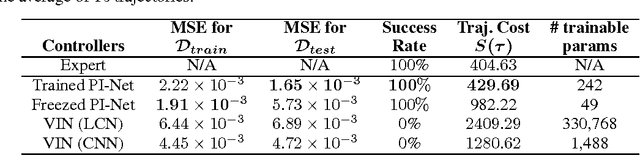
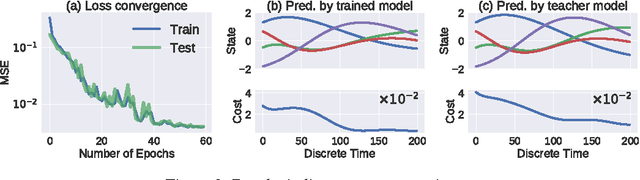

In this paper, we introduce Path Integral Networks (PI-Net), a recurrent network representation of the Path Integral optimal control algorithm. The network includes both system dynamics and cost models, used for optimal control based planning. PI-Net is fully differentiable, learning both dynamics and cost models end-to-end by back-propagation and stochastic gradient descent. Because of this, PI-Net can learn to plan. PI-Net has several advantages: it can generalize to unseen states thanks to planning, it can be applied to continuous control tasks, and it allows for a wide variety learning schemes, including imitation and reinforcement learning. Preliminary experiment results show that PI-Net, trained by imitation learning, can mimic control demonstrations for two simulated problems; a linear system and a pendulum swing-up problem. We also show that PI-Net is able to learn dynamics and cost models latent in the demonstrations.
ShiftCNN: Generalized Low-Precision Architecture for Inference of Convolutional Neural Networks
Jun 07, 2017
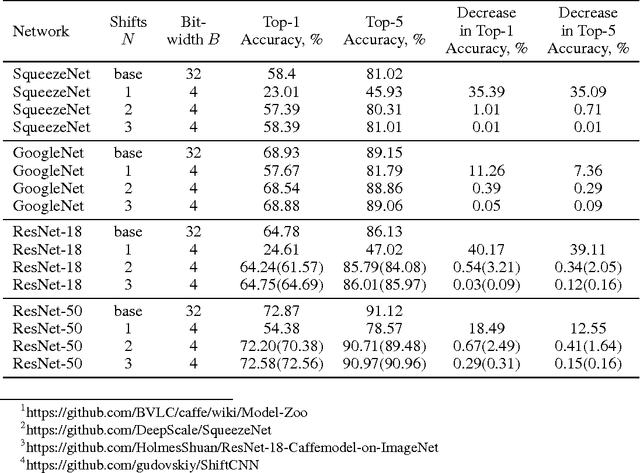
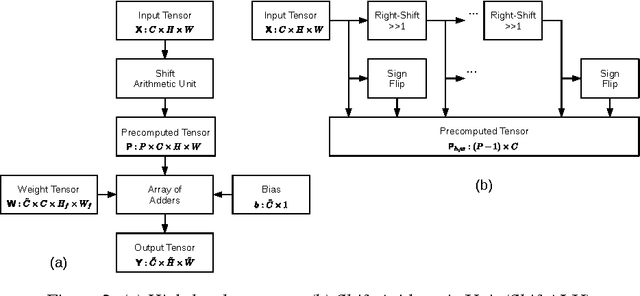
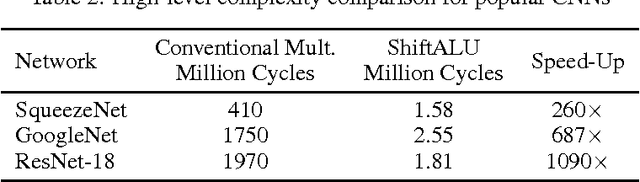
In this paper we introduce ShiftCNN, a generalized low-precision architecture for inference of multiplierless convolutional neural networks (CNNs). ShiftCNN is based on a power-of-two weight representation and, as a result, performs only shift and addition operations. Furthermore, ShiftCNN substantially reduces computational cost of convolutional layers by precomputing convolution terms. Such an optimization can be applied to any CNN architecture with a relatively small codebook of weights and allows to decrease the number of product operations by at least two orders of magnitude. The proposed architecture targets custom inference accelerators and can be realized on FPGAs or ASICs. Extensive evaluation on ImageNet shows that the state-of-the-art CNNs can be converted without retraining into ShiftCNN with less than 1% drop in accuracy when the proposed quantization algorithm is employed. RTL simulations, targeting modern FPGAs, show that power consumption of convolutional layers is reduced by a factor of 4 compared to conventional 8-bit fixed-point architectures.
Similarity Mapping with Enhanced Siamese Network for Multi-Object Tracking
Jan 24, 2017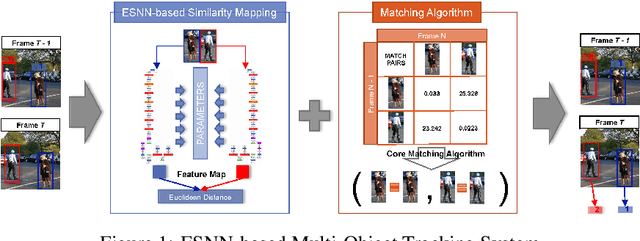
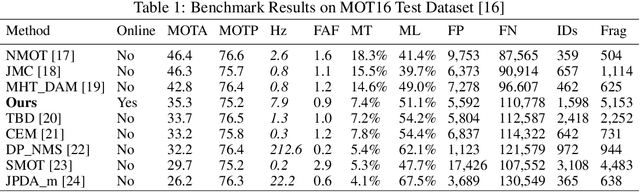
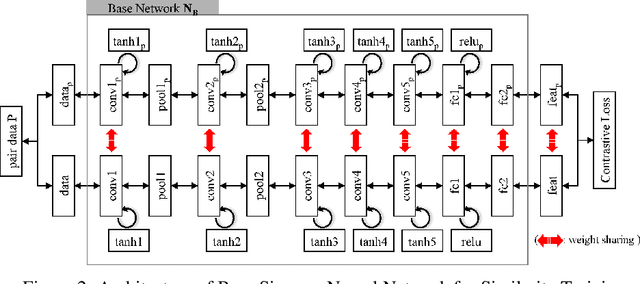

Multi-object tracking has recently become an important area of computer vision, especially for Advanced Driver Assistance Systems (ADAS). Despite growing attention, achieving high performance tracking is still challenging, with state-of-the- art systems resulting in high complexity with a large number of hyper parameters. In this paper, we focus on reducing overall system complexity and the number hyper parameters that need to be tuned to a specific environment. We introduce a novel tracking system based on similarity mapping by Enhanced Siamese Neural Network (ESNN), which accounts for both appearance and geometric information, and is trainable end-to-end. Our system achieves competitive performance in both speed and accuracy on MOT16 challenge, compared to known state-of-the-art methods.
Towards Deep Neural Network Architectures Robust to Adversarial Examples
Apr 09, 2015
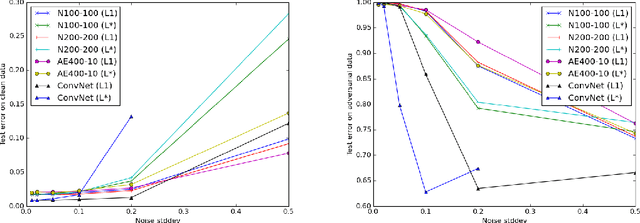
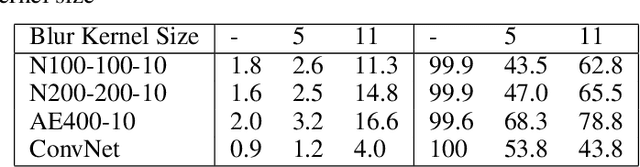

Recent work has shown deep neural networks (DNNs) to be highly susceptible to well-designed, small perturbations at the input layer, or so-called adversarial examples. Taking images as an example, such distortions are often imperceptible, but can result in 100% mis-classification for a state of the art DNN. We study the structure of adversarial examples and explore network topology, pre-processing and training strategies to improve the robustness of DNNs. We perform various experiments to assess the removability of adversarial examples by corrupting with additional noise and pre-processing with denoising autoencoders (DAEs). We find that DAEs can remove substantial amounts of the adversarial noise. How- ever, when stacking the DAE with the original DNN, the resulting network can again be attacked by new adversarial examples with even smaller distortion. As a solution, we propose Deep Contractive Network, a model with a new end-to-end training procedure that includes a smoothness penalty inspired by the contractive autoencoder (CAE). This increases the network robustness to adversarial examples, without a significant performance penalty.