 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 11, 2021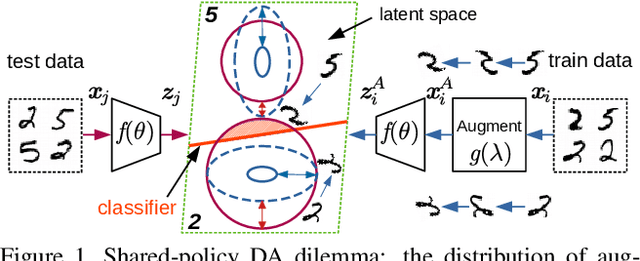
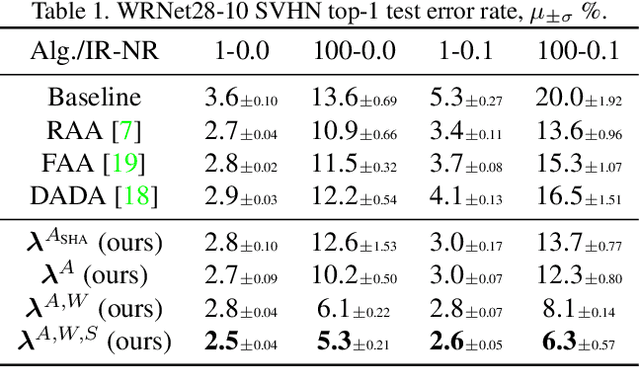


AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision
Mar 01, 2020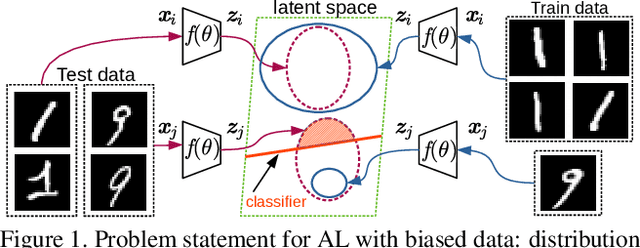

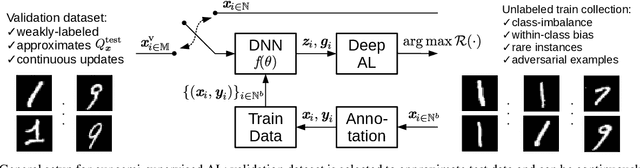
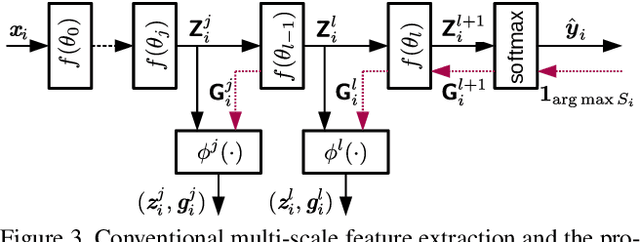
Active learning (AL) aims to minimize labeling efforts for data-demanding deep neural networks (DNNs) by selecting the most representative data points for annotation. However, currently used methods are ill-equipped to deal with biased data. The main motivation of this paper is to consider a realistic setting for pool-based semi-supervised AL, where the unlabeled collection of train data is biased. We theoretically derive an optimal acquisition function for AL in this setting. It can be formulated as distribution shift minimization between unlabeled train data and weakly-labeled validation dataset. To implement such acquisition function, we propose a low-complexity method for feature density matching using self-supervised Fisher kernel (FK) as well as several novel pseudo-label estimators. Our FK-based method outperforms state-of-the-art methods on MNIST, SVHN, and ImageNet classification while requiring only 1/10th of processing. The conducted experiments show at least 40% drop in labeling efforts for the biased class-imbalanced data compared to existing methods.
Smart Home Appliances: Chat with Your Fridge
Dec 19, 2019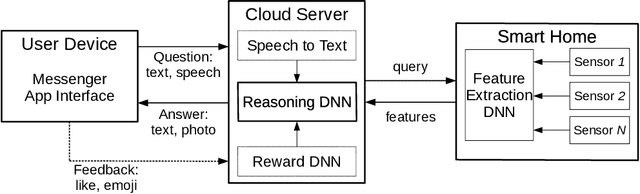

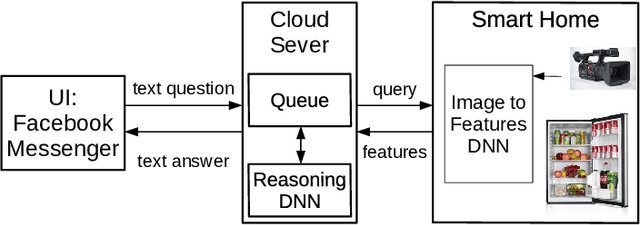
Current home appliances are capable to execute a limited number of voice commands such as turning devices on or off, adjusting music volume or light conditions. Recent progress in machine reasoning gives an opportunity to develop new types of conversational user interfaces for home appliances. In this paper, we apply state-of-the-art visual reasoning model and demonstrate that it is feasible to ask a smart fridge about its contents and various properties of the food with close-to-natural conversation experience. Our visual reasoning model answers user questions about existence, count, category and freshness of each product by analyzing photos made by the image sensor inside the smart fridge. Users may chat with their fridge using off-the-shelf phone messenger while being away from home, for example, when shopping in the supermarket. We generate a visually realistic synthetic dataset to train machine learning reasoning model that achieves 95% answer accuracy on test data. We present the results of initial user tests and discuss how we modify distribution of generated questions for model training based on human-in-the-loop guidance. We open source code for the whole system including dataset generation, reasoning model and demonstration scripts.
Explain to Fix: A Framework to Interpret and Correct DNN Object Detector Predictions
Nov 19, 2018
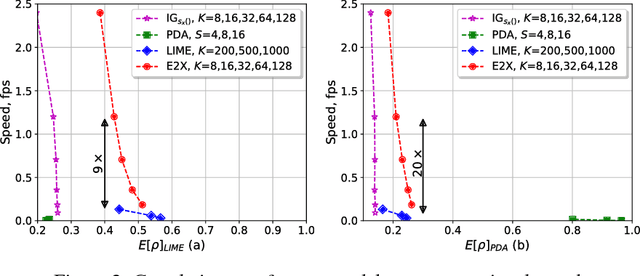
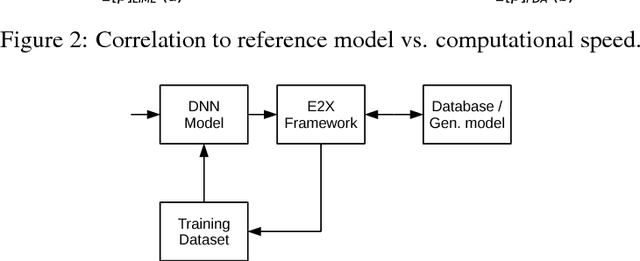
Explaining predictions of deep neural networks (DNNs) is an important and nontrivial task. In this paper, we propose a practical approach to interpret decisions made by a DNN object detector that has fidelity comparable to state-of-the-art methods and sufficient computational efficiency to process large datasets. Our method relies on recent theory and approximates Shapley feature importance values. We qualitatively and quantitatively show that the proposed explanation method can be used to find image features which cause failures in DNN object detection. The developed software tool combined into the "Explain to Fix" (E2X) framework has a factor of 10 higher computational efficiency than prior methods and can be used for cluster processing using graphics processing units (GPUs). Lastly, we propose a potential extension of the E2X framework where the discovered missing features can be added into training dataset to overcome failures after model retraining.