 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFlow: Unsupervised Motion Flow by Joint Geometric and Pixel-level Estimation
Paper and Code
Oct 30, 2017
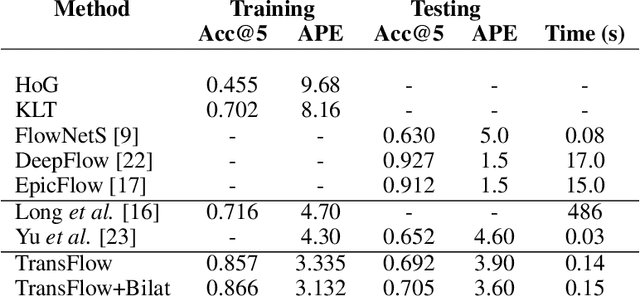
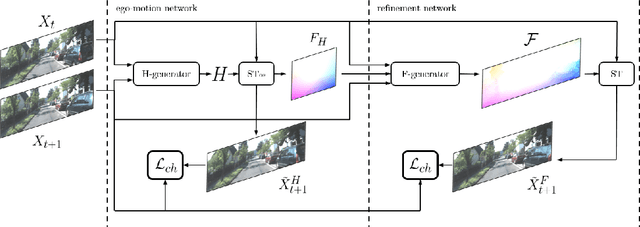

We address unsupervised optical flow estimation for ego-centric motion. We argue that optical flow can be cast as a geometrical warping between two successive video frames and devise a deep architecture to estimate such transformation in two stages. First, a dense pixel-level flow is computed with a geometric prior imposing strong spatial constraints. Such prior is typical of driving scenes, where the point of view is coherent with the vehicle motion. We show how such global transformation can be approximated with an homography and how spatial transformer layers can be employed to compute the flow field implied by such transformation. The second stage then refines the prediction feeding a second deeper network. A final reconstruction loss compares the warping of frame X(t) with the subsequent frame X(t+1) and guides both estimates. The model, which we named TransFlow, performs favorably compared to other unsupervised algorithms, and shows better generalization compared to supervised methods with a 3x reduction in error on unseen data.