 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Neural Network Architectures Robust to Adversarial Examples
Paper and Code

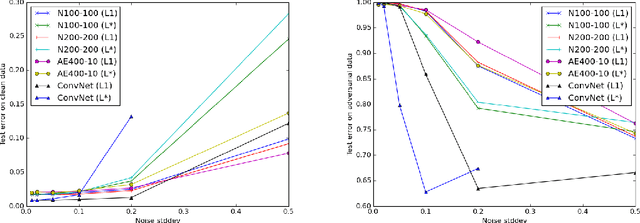
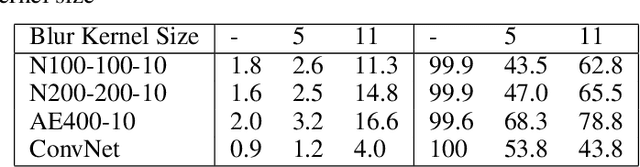

Recent work has shown deep neural networks (DNNs) to be highly susceptible to well-designed, small perturbations at the input layer, or so-called adversarial examples. Taking images as an example, such distortions are often imperceptible, but can result in 100% mis-classification for a state of the art DNN. We study the structure of adversarial examples and explore network topology, pre-processing and training strategies to improve the robustness of DNNs. We perform various experiments to assess the removability of adversarial examples by corrupting with additional noise and pre-processing with denoising autoencoders (DAEs). We find that DAEs can remove substantial amounts of the adversarial noise. How- ever, when stacking the DAE with the original DNN, the resulting network can again be attacked by new adversarial examples with even smaller distortion. As a solution, we propose Deep Contractive Network, a model with a new end-to-end training procedure that includes a smoothness penalty inspired by the contractive autoencoder (CAE). This increases the network robustness to adversarial examples, without a significant performance penalty.