 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQT-TDM: Planning with Transformer Dynamics Model and Autoregressive Q-Learning
Paper and Code
Jul 26, 2024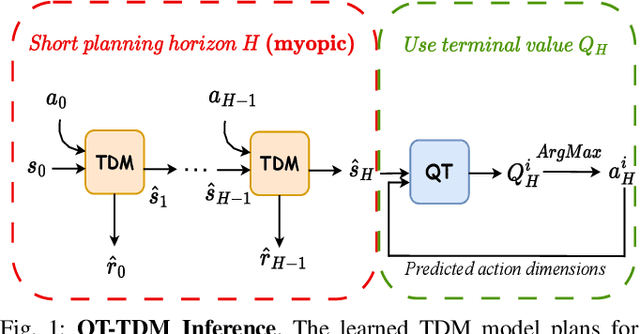
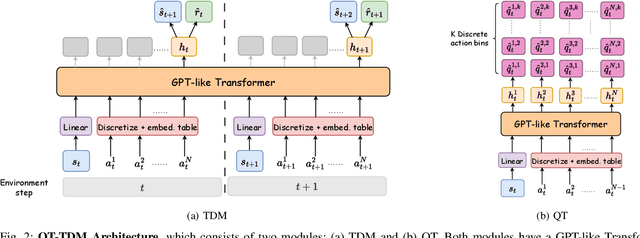

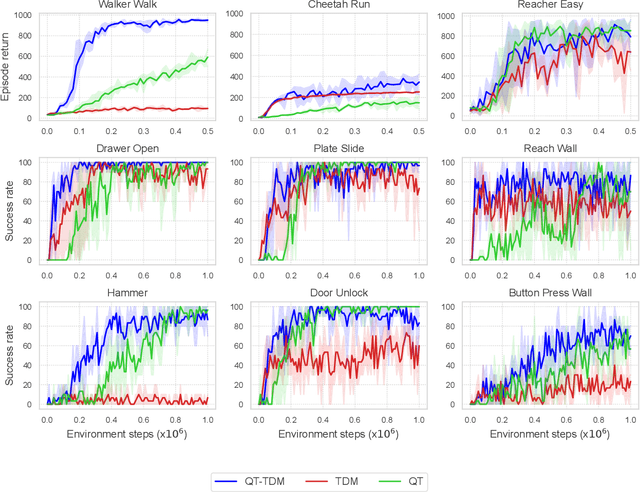
Inspired by the success of the Transformer architecture in natural language processing and computer vision, we investigate the use of Transformers in Reinforcement Learning (RL), specifically in modeling the environment's dynamics using Transformer Dynamics Models (TDMs). We evaluate the capabilities of TDMs for continuous control in real-time planning scenarios with Model Predictive Control (MPC). While Transformers excel in long-horizon prediction, their tokenization mechanism and autoregressive nature lead to costly planning over long horizons, especially as the environment's dimensionality increases. To alleviate this issue, we use a TDM for short-term planning, and learn an autoregressive discrete Q-function using a separate Q-Transformer (QT) model to estimate a long-term return beyond the short-horizon planning. Our proposed method, QT-TDM, integrates the robust predictive capabilities of Transformers as dynamics models with the efficacy of a model-free Q-Transformer to mitigate the computational burden associated with real-time planning. Experiments in diverse state-based continuous control tasks show that QT-TDM is superior in performance and sample efficiency compared to existing Transformer-based RL models while achieving fast and computationally efficient inference.