 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Guide to Structureless Visual Localization
Apr 24, 2025Visual localization algorithms, i.e., methods that estimate the camera pose of a query image in a known scene, are core components of many applications, including self-driving cars and augmented / mixed reality systems. State-of-the-art visual localization algorithms are structure-based, i.e., they store a 3D model of the scene and use 2D-3D correspondences between the query image and 3D points in the model for camera pose estimation. While such approaches are highly accurate, they are also rather inflexible when it comes to adjusting the underlying 3D model after changes in the scene. Structureless localization approaches represent the scene as a database of images with known poses and thus offer a much more flexible representation that can be easily updated by adding or removing images. Although there is a large amount of literature on structure-based approaches, there is significantly less work on structureless methods. Hence, this paper is dedicated to providing the, to the best of our knowledge, first comprehensive discussion and comparison of structureless methods. Extensive experiments show that approaches that use a higher degree of classical geometric reasoning generally achieve higher pose accuracy. In particular, approaches based on classical absolute or semi-generalized relative pose estimation outperform very recent methods based on pose regression by a wide margin. Compared with state-of-the-art structure-based approaches, the flexibility of structureless methods comes at the cost of (slightly) lower pose accuracy, indicating an interesting direction for future work.
Combining Absolute and Semi-Generalized Relative Poses for Visual Localization
Sep 21, 2024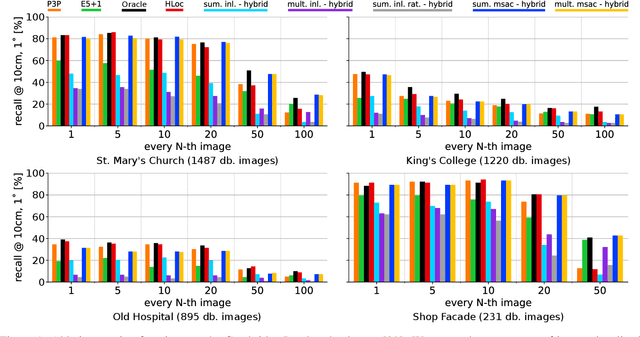

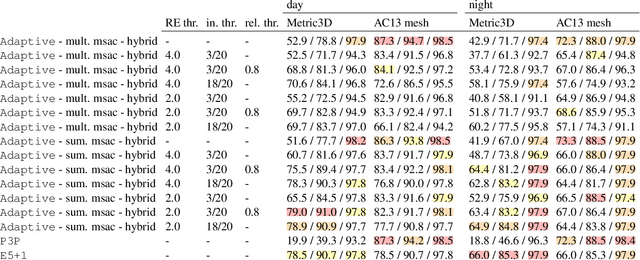
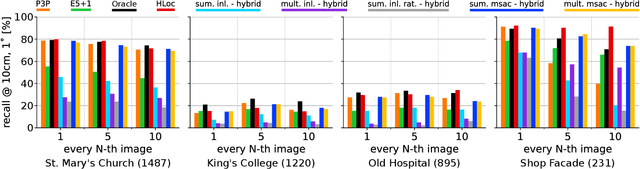
Visual localization is the problem of estimating the camera pose of a given query image within a known scene. Most state-of-the-art localization approaches follow the structure-based paradigm and use 2D-3D matches between pixels in a query image and 3D points in the scene for pose estimation. These approaches assume an accurate 3D model of the scene, which might not always be available, especially if only a few images are available to compute the scene representation. In contrast, structure-less methods rely on 2D-2D matches and do not require any 3D scene model. However, they are also less accurate than structure-based methods. Although one prior work proposed to combine structure-based and structure-less pose estimation strategies, its practical relevance has not been shown. We analyze combining structure-based and structure-less strategies while exploring how to select between poses obtained from 2D-2D and 2D-3D matches, respectively. We show that combining both strategies improves localization performance in multiple practically relevant scenarios.
Visual Localization using Imperfect 3D Models from the Internet
Apr 12, 2023



Visual localization is a core component in many applications, including augmented reality (AR). Localization algorithms compute the camera pose of a query image w.r.t. a scene representation, which is typically built from images. This often requires capturing and storing large amounts of data, followed by running Structure-from-Motion (SfM) algorithms. An interesting, and underexplored, source of data for building scene representations are 3D models that are readily available on the Internet, e.g., hand-drawn CAD models, 3D models generated from building footprints, or from aerial images. These models allow to perform visual localization right away without the time-consuming scene capturing and model building steps. Yet, it also comes with challenges as the available 3D models are often imperfect reflections of reality. E.g., the models might only have generic or no textures at all, might only provide a simple approximation of the scene geometry, or might be stretched. This paper studies how the imperfections of these models affect localization accuracy. We create a new benchmark for this task and provide a detailed experimental evaluation based on multiple 3D models per scene. We show that 3D models from the Internet show promise as an easy-to-obtain scene representation. At the same time, there is significant room for improvement for visual localization pipelines. To foster research on this interesting and challenging task, we release our benchmark at v-pnk.github.io/cadloc.
MeshLoc: Mesh-Based Visual Localization
Jul 25, 2022


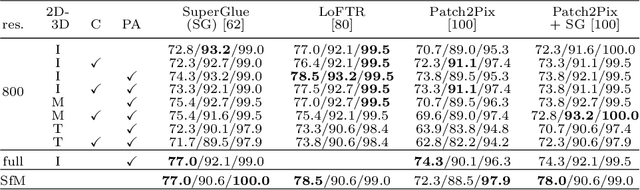
Visual localization, i.e., the problem of camera pose estimation, is a central component of applications such as autonomous robots and augmented reality systems. A dominant approach in the literature, shown to scale to large scenes and to handle complex illumination and seasonal changes, is based on local features extracted from images. The scene representation is a sparse Structure-from-Motion point cloud that is tied to a specific local feature. Switching to another feature type requires an expensive feature matching step between the database images used to construct the point cloud. In this work, we thus explore a more flexible alternative based on dense 3D meshes that does not require features matching between database images to build the scene representation. We show that this approach can achieve state-of-the-art results. We further show that surprisingly competitive results can be obtained when extracting features on renderings of these meshes, without any neural rendering stage, and even when rendering raw scene geometry without color or texture. Our results show that dense 3D model-based representations are a promising alternative to existing representations and point to interesting and challenging directions for future research.