 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemHalDet: Robust VLM Hallucination Detection via Ensemble of Internal State Detectors
Apr 03, 2026Vision-Language Models (VLMs) excel at multimodal tasks, but they remain vulnerable to hallucinations that are factually incorrect or ungrounded in the input image. Recent work suggests that hallucination detection using internal representations is more efficient and accurate than approaches that rely solely on model outputs. However, existing internal-representation-based methods typically rely on a single representation or detector, limiting their ability to capture diverse hallucination signals. In this paper, we propose EnsemHalDet, an ensemble-based hallucination detection framework that leverages multiple internal representations of VLMs, including attention outputs and hidden states. EnsemHalDet trains independent detectors for each representation and combines them through ensemble learning. Experimental results across multiple VQA datasets and VLMs show that EnsemHalDet consistently outperforms prior methods and single-detector models in terms of AUC. These results demonstrate that ensembling diverse internal signals significantly improves robustness in multimodal hallucination detection.
SciGA: A Comprehensive Dataset for Designing Graphical Abstracts in Academic Papers
Jul 03, 2025Graphical Abstracts (GAs) play a crucial role in visually conveying the key findings of scientific papers. While recent research has increasingly incorporated visual materials such as Figure 1 as de facto GAs, their potential to enhance scientific communication remains largely unexplored. Moreover, designing effective GAs requires advanced visualization skills, creating a barrier to their widespread adoption. To tackle these challenges, we introduce SciGA-145k, a large-scale dataset comprising approximately 145,000 scientific papers and 1.14 million figures, explicitly designed for supporting GA selection and recommendation as well as facilitating research in automated GA generation. As a preliminary step toward GA design support, we define two tasks: 1) Intra-GA recommendation, which identifies figures within a given paper that are well-suited to serve as GAs, and 2) Inter-GA recommendation, which retrieves GAs from other papers to inspire the creation of new GAs. We provide reasonable baseline models for these tasks. Furthermore, we propose Confidence Adjusted top-1 ground truth Ratio (CAR), a novel recommendation metric that offers a fine-grained analysis of model behavior. CAR addresses limitations in traditional ranking-based metrics by considering cases where multiple figures within a paper, beyond the explicitly labeled GA, may also serve as GAs. By unifying these tasks and metrics, our SciGA-145k establishes a foundation for advancing visual scientific communication while contributing to the development of AI for Science.
VASCAR: Content-Aware Layout Generation via Visual-Aware Self-Correction
Dec 05, 2024



Large language models (LLMs) have proven effective for layout generation due to their ability to produce structure-description languages, such as HTML or JSON, even without access to visual information. Recently, LLM providers have evolved these models into large vision-language models (LVLM), which shows prominent multi-modal understanding capabilities. Then, how can we leverage this multi-modal power for layout generation? To answer this, we propose Visual-Aware Self-Correction LAyout GeneRation (VASCAR) for LVLM-based content-aware layout generation. In our method, LVLMs iteratively refine their outputs with reference to rendered layout images, which are visualized as colored bounding boxes on poster backgrounds. In experiments, we demonstrate that our method combined with the Gemini. Without any additional training, VASCAR achieves state-of-the-art (SOTA) layout generation quality outperforming both existing layout-specific generative models and other LLM-based methods.
Layout-Corrector: Alleviating Layout Sticking Phenomenon in Discrete Diffusion Model
Sep 25, 2024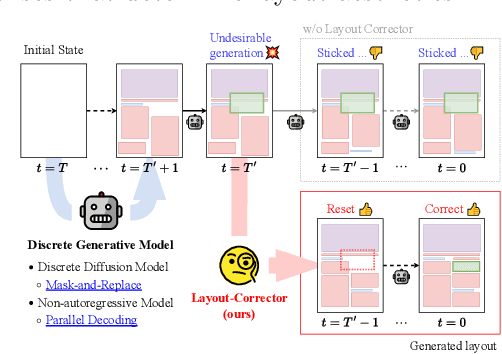
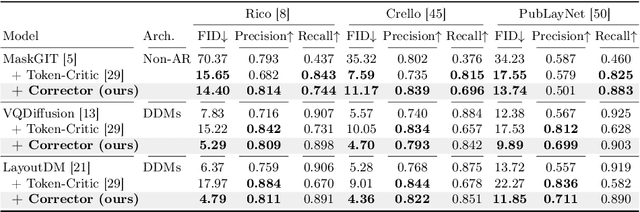
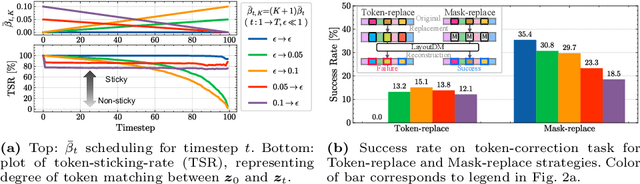
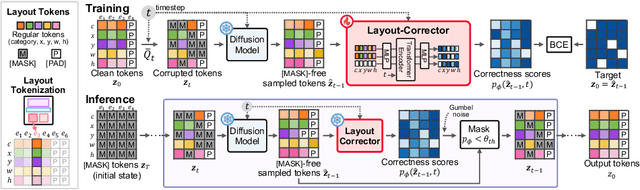
Layout generation is a task to synthesize a harmonious layout with elements characterized by attributes such as category, position, and size. Human designers experiment with the placement and modification of elements to create aesthetic layouts, however, we observed that current discrete diffusion models (DDMs) struggle to correct inharmonious layouts after they have been generated. In this paper, we first provide novel insights into layout sticking phenomenon in DDMs and then propose a simple yet effective layout-assessment module Layout-Corrector, which works in conjunction with existing DDMs to address the layout sticking problem. We present a learning-based module capable of identifying inharmonious elements within layouts, considering overall layout harmony characterized by complex composition. During the generation process, Layout-Corrector evaluates the correctness of each token in the generated layout, reinitializing those with low scores to the ungenerated state. The DDM then uses the high-scored tokens as clues to regenerate the harmonized tokens. Layout-Corrector, tested on common benchmarks, consistently boosts layout-generation performance when in conjunction with various state-of-the-art DDMs. Furthermore, our extensive analysis demonstrates that the Layout-Corrector (1) successfully identifies erroneous tokens, (2) facilitates control over the fidelity-diversity trade-off, and (3) significantly mitigates the performance drop associated with fast sampling.
Majority or Minority: Data Imbalance Learning Method for Named Entity Recognition
Jan 21, 2024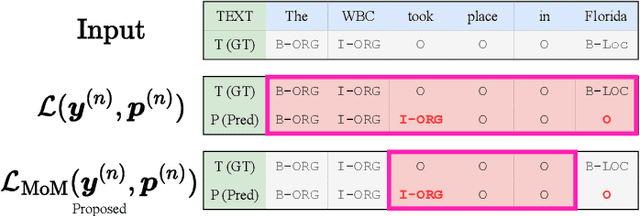

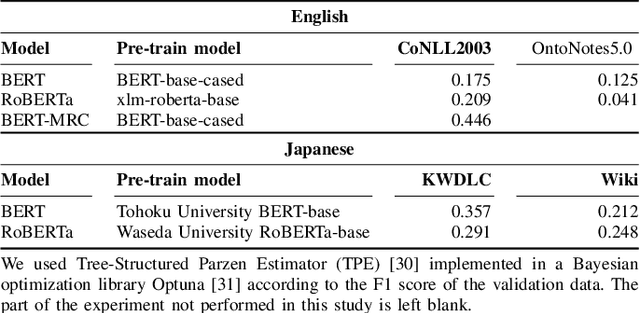
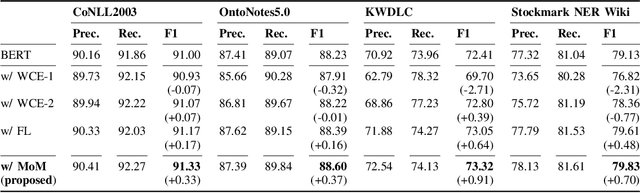
Data imbalance presents a significant challenge in various machine learning (ML) tasks, particularly named entity recognition (NER) within natural language processing (NLP). NER exhibits a data imbalance with a long-tail distribution, featuring numerous minority classes (i.e., entity classes) and a single majority class (i.e., O-class). The imbalance leads to the misclassifications of the entity classes as the O-class. To tackle the imbalance, we propose a simple and effective learning method, named majority or minority (MoM) learning. MoM learning incorporates the loss computed only for samples whose ground truth is the majority class (i.e., the O-class) into the loss of the conventional ML model. Evaluation experiments on four NER datasets (Japanese and English) showed that MoM learning improves prediction performance of the minority classes, without sacrificing the performance of the majority class and is more effective than widely known and state-of-the-art methods. We also evaluated MoM learning using frameworks as sequential labeling and machine reading comprehension, which are commonly used in NER. Furthermore, MoM learning has achieved consistent performance improvements regardless of language, model, or framework.
Improving Prediction Performance and Model Interpretability through Attention Mechanisms from Basic and Applied Research Perspectives
Mar 24, 2023With the dramatic advances in deep learning technology, machine learning research is focusing on improving the interpretability of model predictions as well as prediction performance in both basic and applied research. While deep learning models have much higher prediction performance than traditional machine learning models, the specific prediction process is still difficult to interpret and/or explain. This is known as the black-boxing of machine learning models and is recognized as a particularly important problem in a wide range of research fields, including manufacturing, commerce, robotics, and other industries where the use of such technology has become commonplace, as well as the medical field, where mistakes are not tolerated. This bulletin is based on the summary of the author's dissertation. The research summarized in the dissertation focuses on the attention mechanism, which has been the focus of much attention in recent years, and discusses its potential for both basic research in terms of improving prediction performance and interpretability, and applied research in terms of evaluating it for real-world applications using large data sets beyond the laboratory environment. The dissertation also concludes with a summary of the implications of these findings for subsequent research and future prospects in the field.
Feedback is Needed for Retakes: An Explainable Poor Image Notification Framework for the Visually Impaired
Nov 17, 2022



We propose a simple yet effective image captioning framework that can determine the quality of an image and notify the user of the reasons for any flaws in the image. Our framework first determines the quality of images and then generates captions using only those images that are determined to be of high quality. The user is notified by the flaws feature to retake if image quality is low, and this cycle is repeated until the input image is deemed to be of high quality. As a component of the framework, we trained and evaluated a low-quality image detection model that simultaneously learns difficulty in recognizing images and individual flaws, and we demonstrated that our proposal can explain the reasons for flaws with a sufficient score. We also evaluated a dataset with low-quality images removed by our framework and found improved values for all four common metrics (e.g., BLEU-4, METEOR, ROUGE-L, CIDEr), confirming an improvement in general-purpose image captioning capability. Our framework would assist the visually impaired, who have difficulty judging image quality.
DM$^2$S$^2$: Deep Multi-Modal Sequence Sets with Hierarchical Modality Attention
Sep 07, 2022
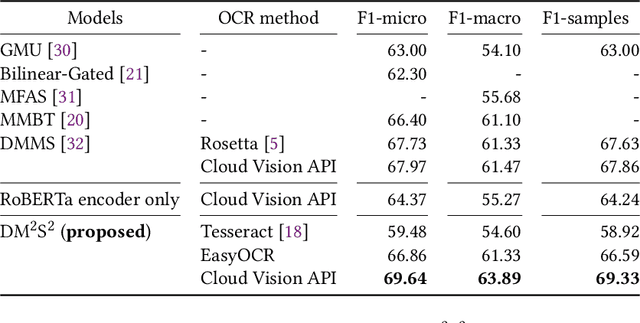
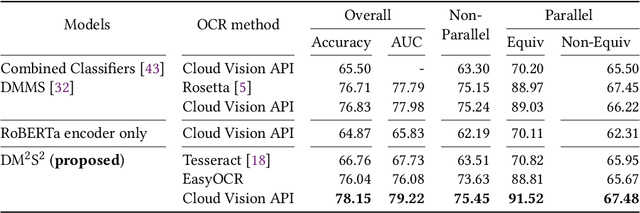

There is increasing interest in the use of multimodal data in various web applications, such as digital advertising and e-commerce. Typical methods for extracting important information from multimodal data rely on a mid-fusion architecture that combines the feature representations from multiple encoders. However, as the number of modalities increases, several potential problems with the mid-fusion model structure arise, such as an increase in the dimensionality of the concatenated multimodal features and missing modalities. To address these problems, we propose a new concept that considers multimodal inputs as a set of sequences, namely, deep multimodal sequence sets (DM$^2$S$^2$). Our set-aware concept consists of three components that capture the relationships among multiple modalities: (a) a BERT-based encoder to handle the inter- and intra-order of elements in the sequences, (b) intra-modality residual attention (IntraMRA) to capture the importance of the elements in a modality, and (c) inter-modality residual attention (InterMRA) to enhance the importance of elements with modality-level granularity further. Our concept exhibits performance that is comparable to or better than the previous set-aware models. Furthermore, we demonstrate that the visualization of the learned InterMRA and IntraMRA weights can provide an interpretation of the prediction results.
Expressions Causing Differences in Emotion Recognition in Social Networking Service Documents
Aug 30, 2022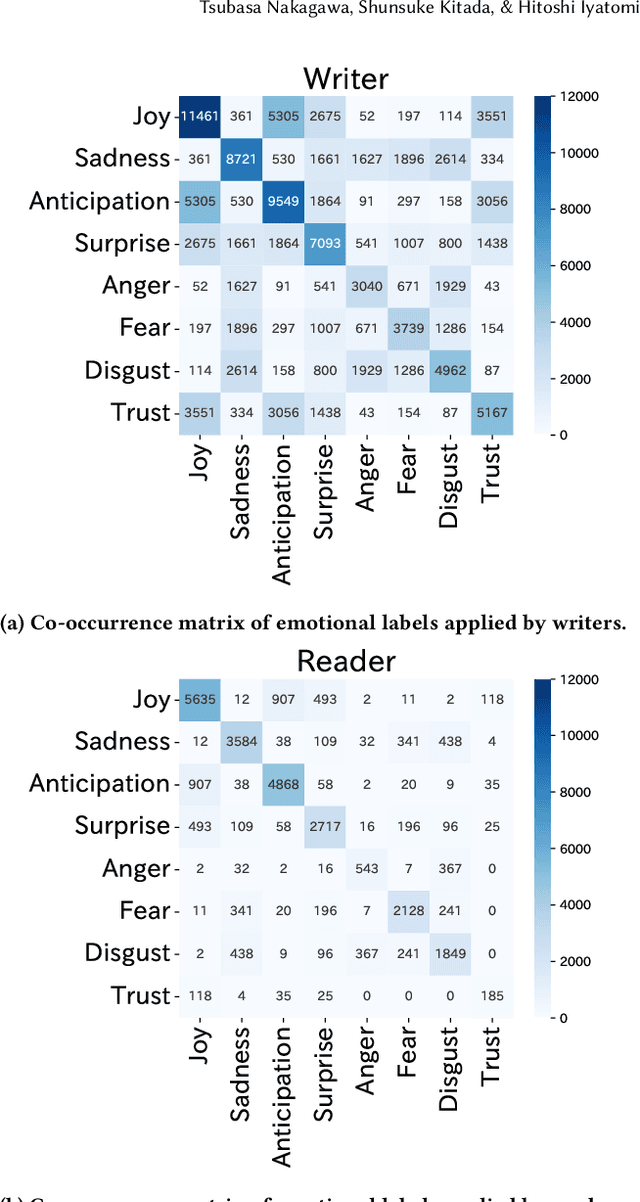
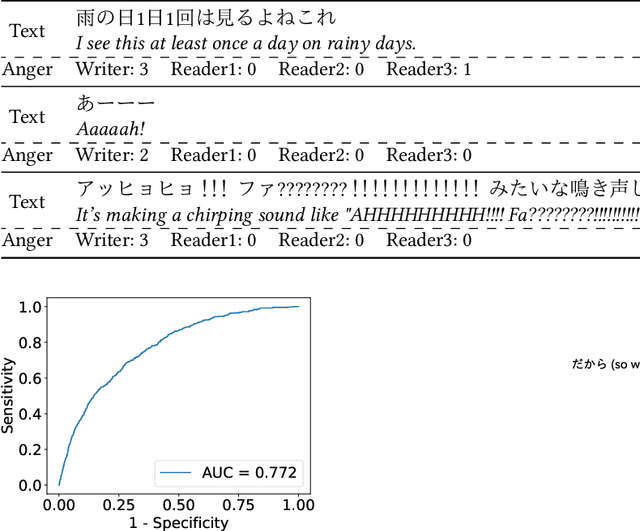


It is often difficult to correctly infer a writer's emotion from text exchanged online, and differences in recognition between writers and readers can be problematic. In this paper, we propose a new framework for detecting sentences that create differences in emotion recognition between the writer and the reader and for detecting the kinds of expressions that cause such differences. The proposed framework consists of a bidirectional encoder representations from transformers (BERT)-based detector that detects sentences causing differences in emotion recognition and an analysis that acquires expressions that characteristically appear in such sentences. The detector, based on a Japanese SNS-document dataset with emotion labels annotated by both the writer and three readers of the social networking service (SNS) documents, detected "hidden-anger sentences" with AUC = 0.772; these sentences gave rise to differences in the recognition of anger. Because SNS documents contain many sentences whose meaning is extremely difficult to interpret, by analyzing the sentences detected by this detector, we obtained several expressions that appear characteristically in hidden-anger sentences. The detected sentences and expressions do not convey anger explicitly, and it is difficult to infer the writer's anger, but if the implicit anger is pointed out, it becomes possible to guess why the writer is angry. Put into practical use, this framework would likely have the ability to mitigate problems based on misunderstandings.
* 5 pages, 3 figures. Accepted at the 31st ACM International Conference on Information and Knowledge Management (CIKM '22) as a short paper
Making Attention Mechanisms More Robust and Interpretable with Virtual Adversarial Training for Semi-Supervised Text Classification
Apr 18, 2021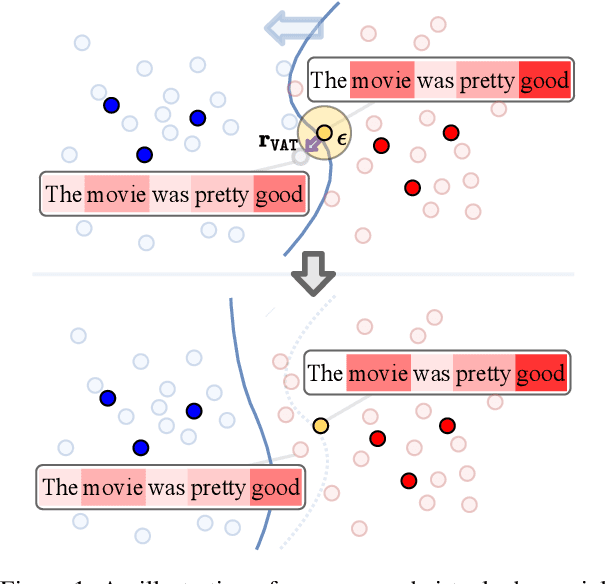

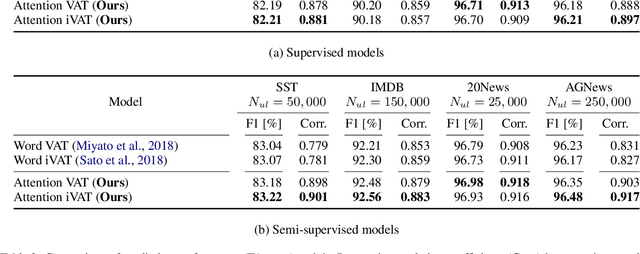
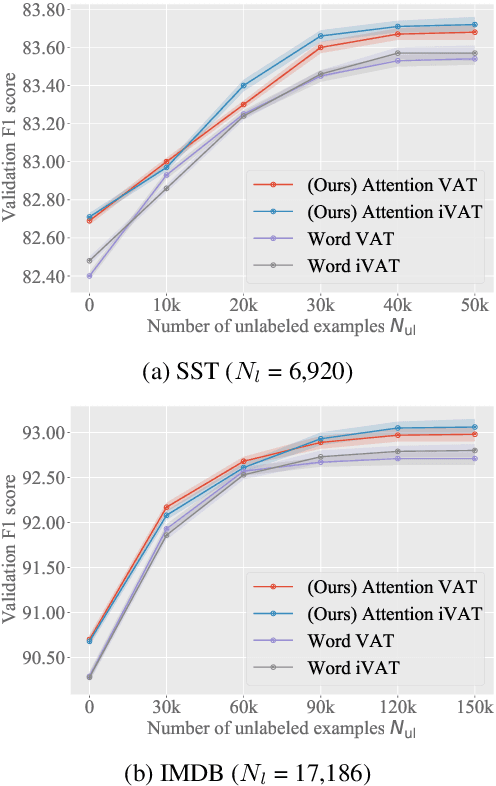
We propose a new general training technique for attention mechanisms based on virtual adversarial training (VAT). VAT can compute adversarial perturbations from unlabeled data in a semi-supervised setting for the attention mechanisms that have been reported in previous studies to be vulnerable to perturbations. Empirical experiments reveal that our technique (1) provides significantly better prediction performance compared to not only conventional adversarial training-based techniques but also VAT-based techniques in a semi-supervised setting, (2) demonstrates a stronger correlation with the word importance and better agreement with evidence provided by humans, and (3) gains in performance with increasing amounts of unlabeled data.