 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification through Glyph-aware Disentangled Character Embedding and Semantic Sub-character Augmentation
Nov 09, 2020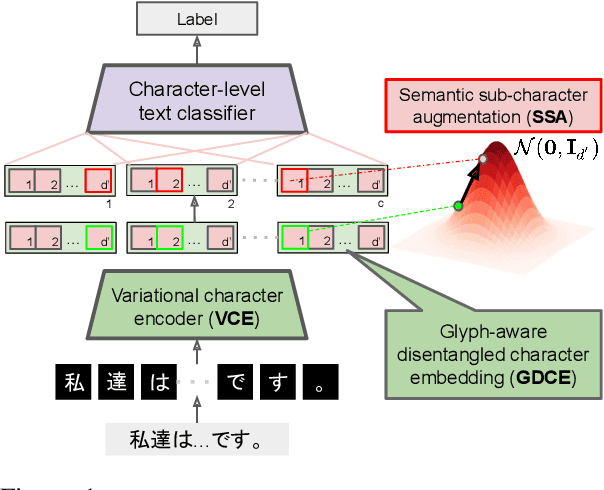

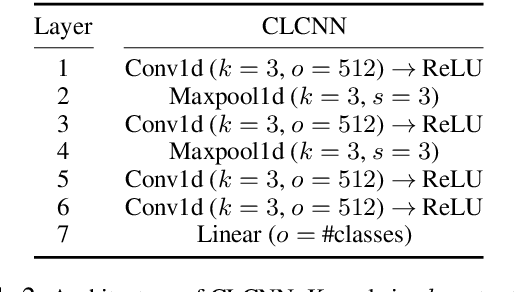

We propose a new character-based text classification framework for non-alphabetic languages, such as Chinese and Japanese. Our framework consists of a variational character encoder (VCE) and character-level text classifier. The VCE is composed of a $\beta$-variational auto-encoder ($\beta$-VAE) that learns the proposed glyph-aware disentangled character embedding (GDCE). Since our GDCE provides zero-mean unit-variance character embeddings that are dimensionally independent, it is applicable for our interpretable data augmentation, namely, semantic sub-character augmentation (SSA). In this paper, we evaluated our framework using Japanese text classification tasks at the document- and sentence-level. We confirmed that our GDCE and SSA not only provided embedding interpretability but also improved the classification performance. Our proposal achieved a competitive result to the state-of-the-art model while also providing model interpretability. Our code is available on https://github.com/IyatomiLab/GDCE-SSA