 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Japanese Commonsense Morality Dataset with Masked Token and Label Enhancement
Oct 12, 2024Rapid advancements in artificial intelligence (AI) have made it crucial to integrate moral reasoning into AI systems. However, existing models and datasets often overlook regional and cultural differences. To address this shortcoming, we have expanded the JCommonsenseMorality (JCM) dataset, the only publicly available dataset focused on Japanese morality. The Extended JCM (eJCM) has grown from the original 13,975 sentences to 31,184 sentences using our proposed sentence expansion method called Masked Token and Label Enhancement (MTLE). MTLE selectively masks important parts of sentences related to moral judgment and replaces them with alternative expressions generated by a large language model (LLM), while re-assigning appropriate labels. The model trained using our eJCM achieved an F1 score of 0.857, higher than the scores for the original JCM (0.837), ChatGPT one-shot classification (0.841), and data augmented using AugGPT, a state-of-the-art augmentation method (0.850). Specifically, in complex moral reasoning tasks unique to Japanese culture, the model trained with eJCM showed a significant improvement in performance (increasing from 0.681 to 0.756) and achieved a performance close to that of GPT-4 Turbo (0.787). These results demonstrate the validity of the eJCM dataset and the importance of developing models and datasets that consider the cultural context.
Expressions Causing Differences in Emotion Recognition in Social Networking Service Documents
Aug 30, 2022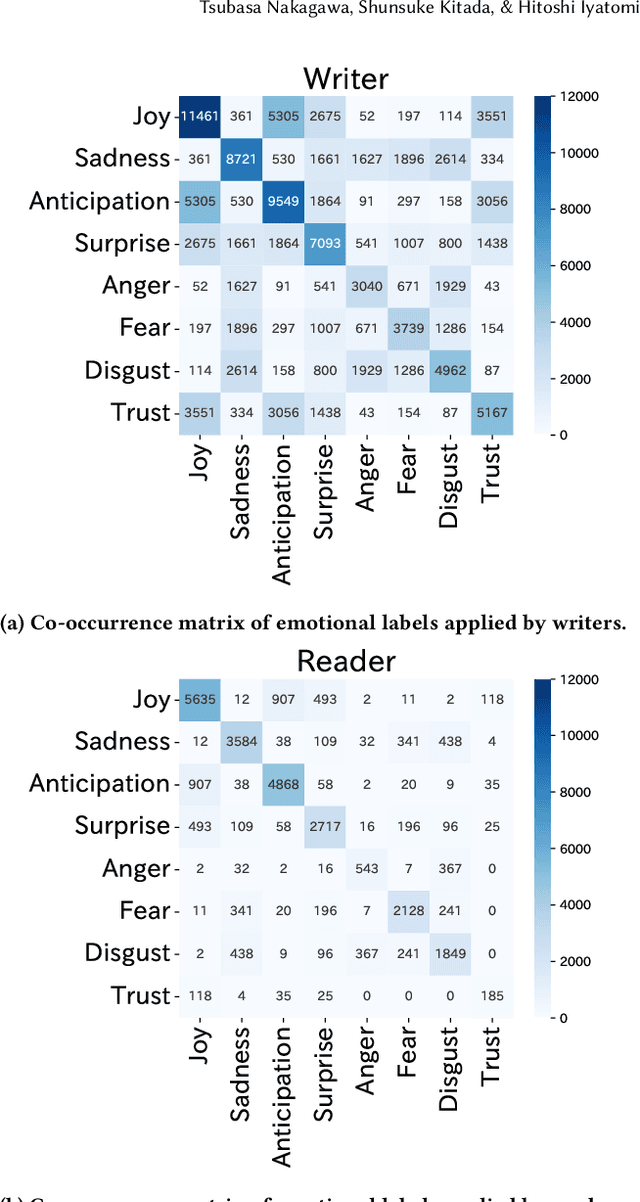
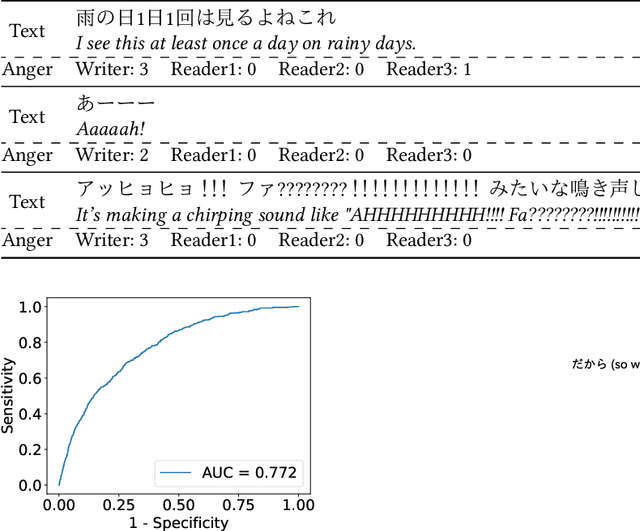


It is often difficult to correctly infer a writer's emotion from text exchanged online, and differences in recognition between writers and readers can be problematic. In this paper, we propose a new framework for detecting sentences that create differences in emotion recognition between the writer and the reader and for detecting the kinds of expressions that cause such differences. The proposed framework consists of a bidirectional encoder representations from transformers (BERT)-based detector that detects sentences causing differences in emotion recognition and an analysis that acquires expressions that characteristically appear in such sentences. The detector, based on a Japanese SNS-document dataset with emotion labels annotated by both the writer and three readers of the social networking service (SNS) documents, detected "hidden-anger sentences" with AUC = 0.772; these sentences gave rise to differences in the recognition of anger. Because SNS documents contain many sentences whose meaning is extremely difficult to interpret, by analyzing the sentences detected by this detector, we obtained several expressions that appear characteristically in hidden-anger sentences. The detected sentences and expressions do not convey anger explicitly, and it is difficult to infer the writer's anger, but if the implicit anger is pointed out, it becomes possible to guess why the writer is angry. Put into practical use, this framework would likely have the ability to mitigate problems based on misunderstandings.
* 5 pages, 3 figures. Accepted at the 31st ACM International Conference on Information and Knowledge Management (CIKM '22) as a short paper